
Web scraping is the process of automatically extracting information from the web. With the growth of the internet and data-driven decisions, it has become an essential method for gathering and analyzing data.
Python is a preferred language for web scraping due to its simplicity and a large selection of libraries that make data extraction and manipulation straightforward.
This tutorial focuses on Python urllib package. Python’s Urllib package is a collection of modules used for preprocessing URLs. Understanding urllib is useful for web scraping tasks, whether you’re just getting started or have some experience.
Our objective here is to learn how urllib can be employed for web scraping tasks.
What is Urllib in Python?
Python’s urllib is a standard library that handles the core components of working with URLs, thus making it a vital tool in scraping.
Specifically,
- the urllib.request module enables opening and reading URLs, while
- the urllib.parse module defines a standard interface to break URL and combine the components back into a URL.
This overview offers a concise look at what Python urllib is all about, breaking down the functionalities of its modules.
Understanding urllib will equip you with the fundamental skills needed to retrieve and manipulate data from the web.
urllib.request
The Python module urllib.request is instrumental in opening URLs and managing various HTTP functionalities.
You can also set proxies, handle HTTP Basic authentication, and manage response cookies. Additionally, the module provides capabilities for working with openers and handlers, though it comes with certain restrictions.
Sending HTTP GET Request with urllib.request
Urllib.request.urlopen function allows to open URLs, it includes HTTP URLs, HTTPS URLs, FTP URLs, Data URLs.
The URL can be the URL as a string or a urllib.request.Request object
Example of an HTTP GET request:
import urllib.request
# sending HTTP GET request
response = urllib.request.urlopen("https://httpbun.com/anything")The urllib.response defines the functions and classes used for request responses in a file-like interface.
The urllib.response object comprises of the following:
-
Response Message
Use the read() function to extract the text from response object
import json
import urllib.request
# sending HTTP GET request
response = urllib.request.urlopen("https://httpbun.com/anything")
# getting response in bytes
response_bytes = response.read()
response_json = json.loads(response_bytes)
print(response_json)
response.close() Output
{'args': {}, 'data': '', 'files': {}, 'form': {}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Host': 'httpbun.com', 'User-Agent': 'Python-urllib/3.8'}, 'json': None, 'method': 'GET', 'origin': '’, 'url': 'https://httpbun.com/anything'}
The urllib.response object uses a file-like interface, which means you can’t read it twice and you also need to close it explicitly.
Reading twice will print empty bytes.
import urllib.request
# sending HTTP GET request
response = urllib.request.urlopen("https://httpbun.com/anything")
# getting response in bytes
response_bytes = response.read()
print(response_bytes)
# reading twice
response_bytes = response.read()
print(response_bytes)
response.close() Output
b'{\n "args": {},\n "data": "",\n "files": {},\n "form": {},\n "headers": {\n "Accept-Encoding": "identity",\n "Connection": "close",\n "Host": "httpbun.com",\n "User-Agent": "Python-urllib/3.8"\n },\n "json": null,\n "method": "GET",\n "origin": "",\n "url": "https://httpbun.com/anything"\n}\n'
# prints empty bytes
b'' Since this response is in JSON structure, we can load it directly using json.loads. However, if we want it in string format, then we need to know the encoding of the response.
Usually, the response’s encoding will be present in the Content-Type response headers. If its not mentioned in the response headers, its most likely “UTF-8” encoding or you can use charset-normalizer · PyPI or Chardet – Python character encoding detector to determine the encoding.
Note: Use urlopen as context manager to avoid explicitly calling close()
import urllib.request
# sending HTTP GET request
with urllib.request.urlopen("https://httpbun.com/anything") as response:
# getting response in bytes
response_bytes = response.read()
print(response_bytes) Output
b'{\n "args": {},\n "data": "",\n "files": {},\n "form": {},\n "headers": {\n "Accept-Encoding": "identity",\n "Connection": "close",\n "Host": "httpbun.com",\n "User-Agent": "Python-urllib/3.8"\n },\n "json": null,\n "method": "GET",\n "origin": "",\n "url": "https://httpbun.com/anything"\n}\n' -
Response Status
To get the status code of the response, we can use the below code:
response_status = response.status
print(response_status)
Output: 200 -
Response URL
To get the response url, we can use the below code:
response_url = response.url
print(response_url)
Output: https://httpbun.com/html-
Response Headers
Using the below code, we can extract the response headers
response_headers = response.headers.items()
print(response_headers)
Output:[('Server', 'nginx'), ('Date', 'Wed, 19 Jul 2023 15:03:30'), ('Content-Type', 'text/html'), ('Transfer-Encoding', 'chunked'), ('Connection', 'close'), ('X-Powered-By', 'httpbun/3c0dcb04705037d50b02f2596')] Sending Headers Along With Request
Use urllib.request.Request and pass it to urlopen as urlopen() lacks a headers parameter.
import urllib.request
# creating a Request object
url = "https://httpbun.com/anything"
headers = {"Referer": "https://httpbun.com"}
request = urllib.request.Request(url, headers=headers)
# sending HTTP GET request
with urllib.request.urlopen(request) as response:
# getting response in bytes
response_bytes = response.read()
print(response_bytes) Output
b'{\n "args": {},\n "data": "",\n "files": {},\n "form": {},\n "headers": {\n "Accept-Encoding": "identity",\n "Connection": "close",\n "Host": "httpbun.com",\n "Referer": "https://httpbun.com",\n "User-Agent": "Python-urllib/3.8"\n },\n "json": null,\n "method": "GET",\n "origin": "",\n "url": "https://httpbun.com/anything"\n}\n' Sending HTTP POST Request with urllib.request
To send an HTTP POST request, pass form data in bytes.
import json
import urllib.request
import urllib.parse
# form data
data = {'user': 'password'}
# qouteplus encoding and into bytes
data = urllib.parse.urlencode(data).encode('UTF-8')
# sending HTTP POST request
url = "https://httpbun.com/anything"
with urllib.request.urlopen(url, data=data) as response:
# getting response in bytes
response_bytes = response.read()
response_json = json.loads(response_bytes)
print(response_json)
Output
{'args': {}, 'data': '', 'files': {}, 'form': {'user': 'password'}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Content-Length': '13', 'Content-Type': 'application/x-www-form-urlencoded', 'Host': 'httpbun.com', 'User-Agent': 'Python-urllib/3.8'}, 'json': None, 'method': 'POST', 'origin': '', 'url': 'https://httpbun.com/anything'}
urlencode() will encode the form data using quote_plus encoding, and str.encode() is used to convert into bytes.
Also, urllib will add an additional header, ‘Content-Type’, in the POST request.
However, to send a POST request with JSON data, pass JSON data in bytes along with {‘Content-Type’: ‘application/json’} headers
import json
import urllib.request
json_data = json.dumps({'user': 'password'}).encode('utf-8')
headers = {'Content-Type': 'application/json'}
url = "https://httpbun.com/anything"
request = urllib.request.Request(url, headers=headers, data=json_data)
# sending HTTP POST request
with urllib.request.urlopen(request) as response:
# getting response in bytes
response_bytes = response.read()
response_json = json.loads(response_bytes)
print(response_json)
Output
{'args': {}, 'data': '{"user": "password"}', 'files': {}, 'form': {}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Content-Length': '20', 'Content-Type': 'application/json', 'Host': 'httpbun.com', 'User-Agent': 'Python-urllib/3.8'}, 'json': {'user': 'password'}, 'method': 'POST', 'origin': '', 'url': 'https://httpbun.com/anything'} Sending Requests Using Other HTTP Methods
While sending requests using other HTTP methods using Python urllib, take into account that:
To set the method, you can use the parameter method while sending requests using urllib.request.Request.
We can use the function get_method() to determine the request method. Urllib uses this funtion to identify the request method. By default the request method will be GET or POST(If we pass form data along with the request).
The method parameter can be used to send different types of HTTP requests like HEAD, PATCH, PUT, etc.
import json
import urllib.request
# creating a urllib PATCH request object
request = urllib.request.Request("https://httpbun.com/patch", method='PATCH')
# verifying request method
print("request method:", request.get_method())
# sending HTTP PATCH request
with urllib.request.urlopen(request) as response:
# getting response in bytes
response_bytes = response.read()
response_json = json.loads(response_bytes)
print(response_json)
Output
request method: PATCH
{'args': {}, 'data': '', 'files': {}, 'form': {}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Content-Length': '0', 'Host': 'httpbun.com', 'User-Agent': 'Python-urllib/3.8'}, 'json': None, 'method': 'PATCH', 'origin': '', 'url': 'https://httpbun.com/patch'} Setting Proxies with HTTP Requests
To set a proxy we can call the function set_proxy , set_proxy accepts hosts and type(scheme)
import urllib.request
import json
# creating a Request instance
url = "https://httpbun.com/anything"
headers = {"Referer": "https://httpbun.com"}
request = urllib.request.Request(url, headers=headers)
# setting proxy
request.set_proxy('example_proxy:port', 'https')
# sending http get request
with urllib.request.urlopen(request) as response:
# getting response in bytes
response_bytes = response.read()
response_json = json.loads(response_bytes)
print(response_json)
Output
{'args': {}, 'data': '', 'files': {}, 'form': {}, 'headers': {'Accept-Encoding': 'identity', 'Connection': 'close', 'Host': 'httpbun.com', 'Referer': 'https://httpbun.com', 'User-Agent': 'Python-urllib/3.8'}, 'json': None, 'method': 'GET', 'origin': 'example_proxy', 'url': 'https://httpbun.com/anything'} Openers and Handlers
An opener in Python urllib is used to open urls. For example, urlopen() is an opener. There will be a chain of handlers added to each opener.
Openers let you tailor your URL requests according to your specific needs.
But What do Handlers do?
Handlers manage different aspects of the journey from making a request to receiving a response. Each request you initiate goes through these registered handlers, each designed to handle specific tasks and scenarios.
When you use the urlopen() function in Python’s urllib library, you’re benefiting from a set of pre-registered handlers that come in handy for various URL types:
- HTTPHandler – handles opening of http URLS
- HTTPSHandler – handles opening of https URLS
- FileHandler – handles opening of https URLS
- FTPHandler – handles opening of FTP URLS
- UnknownHandler – handles unknown URLS
- HTTPRedirectHandler – handles http redirection
Here are some examples to help you understand the concept of openers and handlers.
1. Openers are instances of urllib.request.OpenerDirector, here we create a new instance which is an opener like urlopen, Under the hood urlopen() will call the open() method.
import urllib.request
# creating a Request instance
request = urllib.request.Request("https://httpbun.com/anything")
# creating a new opener
opener = urllib.request.OpenerDirector()
# sending request same as urlopen()
response = opener.open(request)
print(response) Output
NoneHere response prints None, since no request is send.
2. Now to handle HTTP request, we can add HTTPHandle handler
<strong>import</strong> urllib.request
# creating a Request instance
request = urllib.request.Request("http://httpbun.com/anything")
# creating opener
opener = urllib.request.OpenerDirector()
# http handler
http_handler = urllib.request.HTTPHandler()
# adding handler to opener
opener.add_handler(http_handler)
# sending request
response = opener.open(request)
print(response.read())
response.close()
Output
b'{\n "args": {},\n "data": "",\n "files": {},\n "form": {},\n "headers": {\n "Accept-Encoding": "identity",\n "Connection": "close",\n "Host": "httpbun.com",\n "User-Agent": "Python-urllib/3.8"\n },\n "json": null,\n "method": "GET",\n "origin": "",\n "url": "http://httpbun.com/anything"\n}\n'
This code will handle URLs with HTTP protocol. If we send an HTTPS it will fail to do so.
3. To handle HTTPS URLs, we can add HTTPSHandler
<strong>import</strong> urllib.request
# creating opener
opener = urllib.request.OpenerDirector()
https_handler = urllib.request.HTTPSHandler()
opener.add_handler(https_handler)
# now send a request using opener
# …… Handlers are highly useful, and we can add more functionality by building a custom handler.
Handling HTTP Basic Authentication
HTTP authentication provides a framework that controls access and verifies identity. It’s a way to ensure security and control over who can access certain resources on a server. This system operates through a series of challenges and response.
If we send request to a basic auth endpoint, it will ask for authentication with 401 status.
<strong>import</strong> urllib.request
url = "https://httpbun.com/basic-auth/user/pass"
# use opener to send request
<strong>with</strong> urllib.request.urlopen(url) <strong>as</strong> response:
print(response.status)
Output
HTTPError: HTTP Error 401: Unauthorized
To handle this error, you can:
import urllib.request
# creating a password manager
password_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
top_level_url = "https://httpbun.com"
username = "user"
password = "pass"
# adding password
password_manager.add_password(None, top_level_url, username, password)
# creating basic auth handler
basic_handler = urllib.request.HTTPBasicAuthHandler(password_manager)
# create opener
opener = urllib.request.build_opener(basic_handler)
# use the opener to send request
<strong>with</strong> opener.open("https://httpbun.com/basic-auth/user/pass") <strong>as</strong> response:
print("response status:", response.status) Output
response status: 200 Getting Response Cookie
A website sends back response cookies after you’ve made a request. Cookies are small pieces of data that websites use to remember information about your interactions.
There are two ways you can get these response cookies using urllib:
- Via headers
- Via handlers
Via Headers
When a website responds to your request, it includes headers in the response. These headers can contain cookies the website wants your program to store and send back with future requests.
Here, cookies are obtained via the Set-Cookie header.
import urllib.request
# create an opener with the cookie handler
request = urllib.request.Request("https://www.google.com/")
# sending http get request
with urllib.request.urlopen(request) as response:
# getting response cookies
response_cookies = response.headers.get_all('Set-Cookie') Via Handlers
In Python urllib, you can also use handlers to manage cookies. By setting up a cookie handler, you can automatically manage cookies between requests.
import http.cookiejar
import urllib
# create a cookie jar
cookiejar = http.cookiejar.CookieJar()
# creating a cookie handler
cookie_handler = urllib.request.HTTPCookieProcessor(cookiejar)
# creating a opener object
opener = urllib.request.build_opener(cookie_handler)
# sending http get request
with opener.open("https://www.google.com/") as response:
# getting response cookie
response_cookies = cookiejar Handling urllib Exceptions
The urllib.error module defines the exception classes for exceptions raised by urllib.request. The base exception class is URLError.
The following exceptions are raised:
-
Exception urllib.error.URLError
If you encounter issues like sending a request with an incorrect URL format, this exception is raised.
import urllib.request
import urllib.error
try:
urllib.request.urlopen('htttt://httpbun.com/anything')
except urllib.error.URLError as Error:
print(Error.reason) Output
unknown url type: htttt-
Exception urllib.error.HTTPError
This exception is useful when handling exotic HTTP errors, such as requests for authentication.
import urllib.request
import urllib.error
try:
res = urllib.request.urlopen('https://httpbun.com/status/404')
except urllib.error.HTTPError as Error:
print(Error.code) Output
404 Limitations of Python urllib
No HTTP/2 Support
One significant drawback of urllib is that it doesn’t support the HTTP/2 protocol. You might need to consider using other libraries like the httpx module, which does support HTTP/2 and offers a more advanced feature set.
Lack of Async Support
Another limitation of urllib is its lack of built-in asynchronous (async) support. While other libraries like httpx and aiohttp offer async capabilities, urllib is limited to synchronous requests.
Ease of Use
While urllib is a reliable library for making HTTP requests, some developers find it a bit challenging to use compared to more user-friendly alternatives like Requests.
urllib.parse
The Python urllib.parse module offers a standardized way to break URL strings into their various components, such as addressing scheme, network location, path, and so on. It’s also reassembles these components back into a URL string and transforms a “relative URL” into an absolute one with a given “base URL.”
A key feature of this module is its URL quoting functions, which ensure program data is safe for use in URLs by quoting special characters and encoding non-ASCII text properly.
The urllib.parse module is versatile, supporting a wide range of URL schemes, including
file, ftp, gopher, hdl, http, https, imap, mailto, mms, news, nntp, prospero, rsync, rtsp, rtsps, rtspu, sftp, shttp, sip, sips, snews, svn, svn+ssh, telnet, wais, ws, wss.
URL Parsing
Parsing in the Python urllib.parse module specifically deals with breaking down Uniform Resource Locator (URL) strings into individual components and then reassembling them.
Parsing functions include
-
urllib.parse.urlparse
This function is used to dissect a URL into six components as a tuple and includes the URL scheme specifier, network location part, hierarchical path, parameters for last path element, query component and fragment identifier.
import urllib.parse
url = 'https://httpbun.com/anything;param?q=v&q2=v2#frag'
print(urllib.parse.urlparse(url)) Output
ParseResult(scheme='https', netloc='httpbun.com', path='/anything', params='param', query='q=v&q2=v2', fragment='frag')-
urllib.parse.urlunparse
Conversely, this function takes the six components obtained from urlparse and combines them back into a complete URL string.
import urllib.parse
url = 'https://httpbun.com/anything;param?q=v&q2=v2#frag'
components = urllib.parse.urlparse(url)
# replace scheme with http
components = components._replace(scheme='http')
constructed_url = urllib.parse.urlunparse(components)
print(constructed_url) Output
http://httpbun.com/anything;param?q=v&q2=v2#frag URL Quoting
The URL quoting functions focus on taking program data and making it safe for use as URL components by quoting special characters and appropriately encoding non-ASCII text. They also support reversing these operations to recreate the original data from the contents of a URL component.
The quoting functions include
-
Urllib.parse.quote
The urllib.parse.quote function in Python’s urllib.parse module is used to replace special characters in a string with their corresponding %xxescape codes. Letters, digits, and the characters _.-~ are never quoted.
The safe parameter is optional, it specifies additional ASCII characters that should not be quoted.
-
import urllib.parse
url = 'https://httpbun.com/anything;param?q=v&q2=v2#frag'
quoted_url = urllib.parse.quote(url, safe='/:')
print(quoted_url)Output
https://httpbun.com/anything%3Bparam%3Fq%3Dv%26q2%3Dv2%23frag-
Urllib.parse.quote_plus
Similar to quote, this function replaces spaces with the plus symbol (+) as required for quoting HTML form values when building up a query string to go into a URL.
-
Urllib.parse.unquote
This function replaces %xx escapes with their single-character equivalent.
import urllib.parse
quoted_url = "https://httpbun.com/anything%3Bparam%3Fq%3Dv%26q2%3Dv2%23frag"
unquoted_url = urllib.parse.unquote(quoted_url)
print(unquoted_url)Output
https://httpbun.com/anything;param?q=v&q2=v2#frag-
Urllib.parse.quote_plus
The function is similar to unquote(), but here, it replaces plus symbols (+) with spaces.
Scraper Using Python Urllib
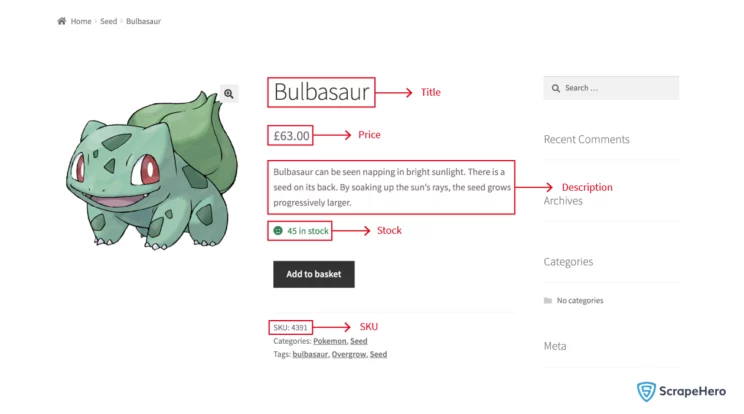
The objective in creating a scraper using the Python’s urllib library is to collect specific information about Pokemon products, including the URL, title, price, description, stock, and SKU (Stock Keeping Unit).
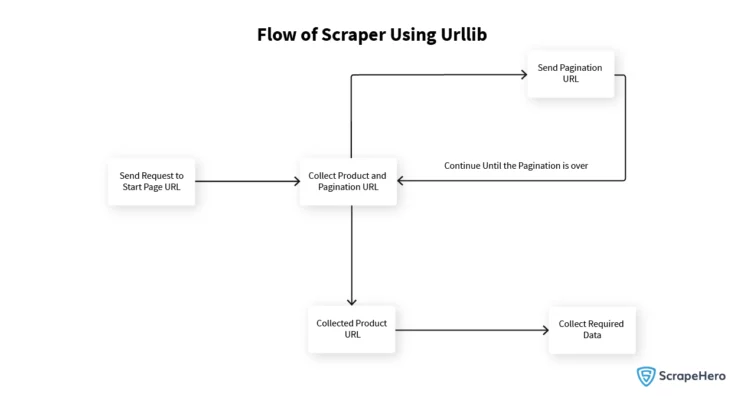
Scraper Flow
To collect product and pagination URLs, start with https://scrapeme.live/shop/. Gather all necessary product URLs and hit the pagination URLs until you reach the final page. Then hit all collected product URLs and scrape required data points. This process streamlines web scraping and efficiently collects data from multiple pages.
Create a Scraper
Since urllib is a Python standard library, no further installation is required.
Now, let’s start building the scraper.
First, import the required libraries.
import urllib.request
import urllib.errorHere, the `urllib.request’ is used to send HTTP request to the target website and urllib.error is for handling errors.
Send Request to Homepage
To send the request to the website, use the following line of code:
request = urllib.request.Request(url)You might get blocked if you send a request to a website without using headers.
Let’s see how to pass headers in urllib.
For that,
- We need to collect the required HTTP headers to hit the “ https://scrapeme.live/shop/ “
- By inspecting networks using Chrome Developer Tools, we can collect the required headers. Most websites block requests that come in without a valid browser as a User-Agent.
import urllib.request
import urllib.error
homepage_url = 'http://scrapeme.live/shop/'
headers = {
'authority': 'scrapeme.live',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language': 'en-US,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'referer': 'https://www.google.com/',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'sec-gpc': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
<strong>}
request = urllib.request.Request(homepage_url, headers=headers)
try:
# sending HTTP GET request
with urllib.request.urlopen(request) as response:
print("response status", response.status)
except urllib.error.HTTPError as Err</strong>or:
print(Error.code)Output
response status 200Collect Product URLs Using LXML and XPath
Now, collect the product URLs from the home page and append them to a list. You can collect these product URLs using LXML and XPath, LXML lets you navigate the HTML Tree Structure using XPaths.

Xpath for collecting product URLs:
//a[contains(@class,'product__link')]/@hrefCode to collect the product URLS:
…….
c<strong>ollected_product_urls = []
with urllib.request.urlopen(request) as resp</strong>onse:
response_bytes = response.read()
parser = fromstring(response_bytes)
product_url_xpath = "//a[contains(@class,'product__link')]/@href"
product_urls = parser.xpath(product_url_xpath)
collected_product_urls.extend(product_urls)
print(collected_product_urls)
……..Output
['https://scrapeme.live/shop/Bulbasaur/', 'https://scrapeme.live/shop/Ivysaur/', 'https://scrapeme.live/shop/Venusaur/', 'https://scrapeme.live/shop/Charmander/', 'https://scrapeme.live/shop/Charmeleon/', 'https://scrapeme.live/shop/Charizard/', 'https://scrapeme.live/shop/Squirtle/', 'https://scrapeme.live/shop/Wartortle/', 'https://scrapeme.live/shop/Blastoise/', 'https://scrapeme.live/shop/Caterpie/', 'https://scrapeme.live/shop/Metapod/', 'https://scrapeme.live/shop/Butterfree/', 'https://scrapeme.live/shop/Weedle/', 'https://scrapeme.live/shop/Kakuna/', 'https://scrapeme.live/shop/Beedrill/', 'https://scrapeme.live/shop/Pidgey/']The collected product URLs are now in a list, which will be used later for sending requests.
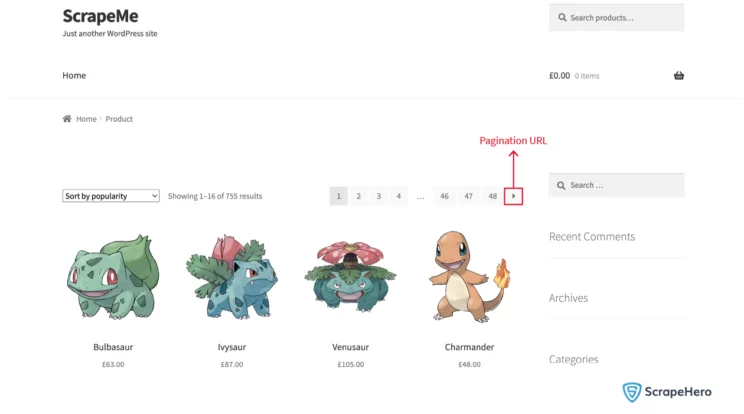
Handling Pagination
Before moving further, let’s structure the code into functions to avoid much repetition.
def get_response_bytes(url, headers):
for _ in range(3):
request = urllib.request.Request(url, headers=headers)
try:
with urllib.request.urlopen(request) as response:
if response.status != 200:
continue
return response.read()
except urllib.error.HTTPError as Error:
print("exception occured:", Error.code)
continue
return
collected_product_urls = []
def scrape(url, headers):
response_bytes = get_response_bytes(url, headers)
if not response_bytes:
print('scraping failed')
return
parser = fromstring(response_bytes)
product_url_xpath = "//a[contains(@class,'product__link')]/@href"
product_urls = parser.xpath(product_url_xpath)
collected_product_urls.extend(product_urls)
print(collected_product_urls)So far, we have handled only a single listing page, but to collect all the products, we need to handle pagination.
First, locate the pagination html tag and write an XPath to retrieve the pagination URL from the tag.

Xpath for next page URL:
(//a[@class='next page-numbers']/@href)[1]After collecting the next page URL, recursively call the scrape function, which will collect all the product URLs into a list.
collected_product_urls = []
def scrape(url, headers):
response_bytes = get_response_bytes(url, headers)
if not response_bytes:
print('scraping failed')
return
parser = fromstring(response_bytes)
product_url_xpath = "//a[contains(@class,'product__link')]/@href"
product_urls = parser.xpath(product_url_xpath)
collected_product_urls.extend(product_urls)
next_page_xpath = "(//a[@class='next page-numbers']/@href)[1]"
next_page = parser.xpath(next_page_xpath)
if next_page:
next_page_url = next_page[0]
print(next_page_url)
scrape(next_page_url, headers)
return
scrape(homepage_url, headers)Output
https://scrapeme.live/shop/page/2/
https://scrapeme.live/shop/page/3/
https://scrapeme.live/shop/page/4/
…
…
https://scrapeme.live/shop/page/48/Collect Data from Product Pages
Write a separate function that handles sending request to each collected product URLs and collecting required data points.
def hit_collected_products():
for product_url in collected_product_urls:
response_bytes = get_response_bytes(product_url, headers)
parser = fromstring(response_bytes)
product_title_xpath = "//h1[contains(@class,'product_title')]/text()"
price_xpath = "//p[@class='price']/span/text()"
description_xpath = "//div[contains(@class,'short-description')]/p/text()"
stock_xpath = "//p[contains(@class,'stock')]/text()"
sku_xpath = "//span[@class='sku']/text()"
# collecting datapoints
each_product_details = []
for required_xpath in [product_title_xpath, price_xpath, description_xpath, stock_xpath, sku_xpath]:
data = parser.xpath(required_xpath)
data = data[0] if data else None
each_product_details.append(data)
each_product_details.append(product_url)
print(each_product_details)Output
['Bulbasaur', '63.00', 'Bulbasaur can be seen napping in bright sunlight. There is a seed on its back. By soaking up the sun's rays, the seed grows progressively larger.', '45 in stock', '4391', 'https://scrapeme.live/shop/Bulbasaur/']
['Ivysaur', '87.00', 'There is a bud on this Pokémon's back. To support its weight, Ivysaur's legs and trunk grow thick and strong. If it starts spending more time lying in the sunlight, it's a sign that the bud will bloom into a large flower soon.', '142 in stock', '7227', 'https://scrapeme.live/shop/Ivysaur/']
['Venusaur', '105.00', 'There is a large flower on Venusaur's back. The flower is said to take on vivid colors if it gets plenty of nutrition and sunlight. The flower's aroma soothes the emotions of people.', '30 in stock', '7036', 'https://scrapeme.live/shop/Venusaur/']Write Collected Data to CSV
After collecting data from product pages, the data should be written into a CSV file.
Code for writing collected data into “product_details.csv”
import csv
def write_to_csv(first_row, each_product_details):
with open('product_details.csv', 'a', newline='') as csvfile:
fieldnames = ['title', 'price', 'description', 'stock', 'SKU', 'product_url']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
if not first_row:
writer.writeheader()
row = {key:value for key, value in zip(fieldnames, each_product_details)}
writer.writerow(row)Full Scraper
Here’s the complete code to build a scraper using Python urllib:
import urllib.request
import urllib.error
import csv
from lxml.html import fromstring
homepage_url = 'http://scrapeme.live/shop/'
headers = {
'authority': 'scrapeme.live',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',
'accept-language': 'en-US,en;q=0.8',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'referer': 'https://www.google.com/',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'sec-gpc': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
def write_to_csv(first_row, each_product_details):
with open('product_details.csv', 'a', newline='') as csvfile:
fieldnames = ['title', 'price', 'description', 'stock', 'SKU', 'product_url']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
if not first_row:
writer.writeheader()
row = {key: value for key, value in zip(fieldnames, each_product_details)}
writer.writerow(row)
collected_product_urls = []
def hit_collected_products():
for index, product_url in enumerate(collected_product_urls):
response_bytes = get_response_bytes(product_url, headers)
parser = fromstring(response_bytes)
product_title_xpath = "//h1[contains(@class,'product_title')]/text()"
price_xpath = "//p[@class='price']/span/text()"
description_xpath = "//div[contains(@class,'short-description')]/p/text()"
stock_xpath = "//p[contains(@class,'stock')]/text()"
sku_xpath = "//span[@class='sku']/text()"
each_product_details = []
for required_xpath in [product_title_xpath, price_xpath, description_xpath, stock_xpath, sku_xpath]:
data = parser.xpath(required_xpath)
data = data[0] if data else None
each_product_details.append(data)
each_product_details.append(product_url)
write_to_csv(index, each_product_details)
def get_response_bytes(url, headers):
for _ in range(3):
request = urllib.request.Request(url, headers=headers)
try:
with urllib.request.urlopen(request) as response:
if response.status != 200:
continue
return response.read()
except urllib.error.HTTPError as Error:
print("exception occured:", Error.code)
continue
return
def scrape(url, headers):
response_bytes = get_response_bytes(url, headers)
if not response_bytes:
print('scraping failed')
return
parser = fromstring(response_bytes)
product_url_xpath = "//a[contains(@class,'product__link')]/@href"
product_urls = parser.xpath(product_url_xpath)
collected_product_urls.extend(product_urls)
next_page_xpath = "(//a[@class='next page-numbers']/@href)[1]"
next_page = parser.xpath(next_page_xpath)
if next_page:
next_page_url = next_page[0]
scrape(next_page_url, headers)
return
hit_collected_products()
print('scraping finished successfully')
scrape(homepage_url, headers)Wrapping Up
If you are dealing with web-related tasks in Python, it is essential to have a solid understanding of urllib. This standard package provides a wide range of tools for working with URLs, including basic operations such as opening and reading URLs, as well as more complex tasks such as URL parsing, quoting, and scraping.
With its versatile functionality, urllib is a necessary foundation for navigating HTTP requests and URLs.
If you’re looking to scrape websites on a much larger scale, ScrapeHero provides web scraping services that will streamline your data extraction efforts without any hassle.


