

This article explores how to scrape data from Trulia using coding and no-code methods. This could effectively export real estate data from Trulia to Excel or other formats for easier access and use.
There are three methods to scrape Trulia data:
- Web scraping Trulia with coding: Building a web scraper in Python or JavaScript
- Web scraping Trulia without coding: Using the ScrapeHero Cloud’s Trulia Scraper, a no-code scraping tool
ScrapeHero Cloud offers you ready-made web crawlers and real-time APIs, which are the easiest way to extract data from websites and download it into spreadsheets with a few clicks.

Building a Trulia Data Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Trulia using either Python or Javascript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or Beautiful Soup to build a Trulia Scraper without using a browser or a browser automation library. But bypassing the anti-scraping mechanisms put in place can be challenging and is beyond the scope of this article.
Here are the steps to scrape Trulia data using Playwright:
Step 1: Choose either Python or JavaScript as your programming language.
Step2: Install Playwright for your preferred language:
Python
pip install playwright
# to download the necessary browsers
playwright installJavaScript
npm install playwright@latestStep 3: Write your code to emulate browser behavior and extract the desired data from Trulia using the Playwright API. You can use the code provided below:
Python
import asyncio
import json
import logging
from playwright.async_api import async_playwright
location = "Atlanta, GA"
max_pagination = 2
async def extract_data(page, selector) -> list:
"""
Parsing details from the listing page
Args:
page (_type_): webpage of the browser
selector: selector for the div containing
property details
Returns:
list: details of homes for sale
"""
# Initializing selectors and xpaths
total_results_xpath = "//h2[contains(@class,'bcPATd')]"
next_page_selector = "[data-testid='pagination-next-page']"
price_selector = "[data-testid='property-price']"
bed_selector = "[data-testid='property-beds']"
bath_selector = "[data-testid='property-baths']"
area_selector = "[data-testid='property-floorSpace']"
address_selector = "[data-testid='property-address']"
# Number of results obtained for the location
total_results_count = await page.locator(total_results_xpath).inner_text()
total_results_count = total_results_count.split()[0]
logging.warning(f"Total results found for {location}- {total_results_count}")
# List to save the details of properties
homes_for_sale = []
# Paginating through each page
for _ in range(max_pagination):
# Waiting to finish loading
await page.wait_for_load_state("load")
# Extracting the elements
all_visible_elements = page.locator(selector)
all_visible_elements_count = 40
for index in range(all_visible_elements_count):
# Hovering the element to load the price
inner_element = all_visible_elements.nth(index=index)
await inner_element.hover()
inner_element = all_visible_elements.nth(index=index)
# Extracting necessary data
price = await inner_element.locator(price_selector).inner_text() if await inner_element.locator(price_selector).count() else None
no_of_beds = await inner_element.locator(bed_selector).inner_text() if await inner_element.locator(bed_selector).count() else None
no_of_baths = await inner_element.locator(bath_selector).inner_text() if await inner_element.locator(bath_selector).count() else None
area = await inner_element.locator(area_selector).inner_text() if await inner_element.locator(area_selector).count() else None
address = await inner_element.locator(address_selector).inner_text() if await inner_element.locator(address_selector).count() else None
# Removing extra spaces and unicode characters
price = clean_data(price)
no_of_beds = clean_data(no_of_beds)
no_of_baths = clean_data(no_of_baths)
area = clean_data(area)
address = clean_data(address)
data_to_save = {
"price": price,
"no of Beds": no_of_beds,
"no of Baths": no_of_baths,
"Area": area,
"address": address,
}
homes_for_sale.append(data_to_save)
next_page = page.locator(next_page_selector)
await next_page.hover()
if not await next_page.count():
break
# Clicking the next page button
await next_page.click()
save_data(homes_for_sale, "Data.json")
async def run(playwright) -> None:
# Initializing the browser and creating a new page.
browser = await playwright.firefox.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
await page.set_viewport_size({"width": 1920, "height": 1080})
page.set_default_timeout(120000)
# Navigating to homepage
await page.goto("https://www.trulia.com/", wait_until="domcontentloaded")
await page.wait_for_load_state("load")
await page.wait_for_load_state(timeout=60000)
# Initializing xpath and selector
xpath_search_box = "[id='banner-search']"
listing_div_selector = "[data-testid='home-card-sale']"
# Clicking the input field to enter the location and navigating to listing page
await page.locator(xpath_search_box).click()
await page.locator(xpath_search_box).fill(location)
await page.locator(xpath_search_box).press("Enter")
# Wait until the list of properties is loaded
await page.wait_for_selector(listing_div_selector)
await extract_data(page, listing_div_selector)
await context.close()
await browser.close()
def clean_data(data: str) -> str:
"""
Cleaning data by removing extra white spaces and Unicode characters
Args:
data (str): data to be cleaned
Returns:
str: cleaned string
"""
if not data:
return ""
cleaned_data = " ".join(data.split()).strip()
cleaned_data = cleaned_data.encode("ascii", "ignore").decode("ascii")
return cleaned_data
def save_data(product_page_data: list, filename: str):
"""Converting a list of dictionaries to JSON format
Args:
product_page_data (list): details of each product
filename (str): name of the JSON file
"""
with open(filename, "w") as outfile:
json.dump(product_page_data, outfile, indent=4)
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
if __name__ == "__main__":
asyncio.run(main())JavaScript
const { chromium, firefox } = require('playwright');
const fs = require('fs');
const location = "Atlanta,GA";
const maxPagination = 2;
/**
* Save data as list of dictionaries
as json file
* @param {object} data
*/
function saveData(data) {
let dataStr = JSON.stringify(data, null, 2)
fs.writeFile("DataJS.json", dataStr, 'utf8', function (err) {
if (err) {
console.log("An error occurred while writing JSON Object to File.");
return console.log(err);
}
console.log("JSON file has been saved.");
});
}
function cleanData(data) {
if (!data) {
return;
}
// removing extra spaces and unicode characters
let cleanedData = data.split(/s+/).join(" ").trim();
cleanedData = cleanedData.replace(/[^x00-x7F]/g, "");
return cleanedData;
}
/**
* The data extraction function used to extract
necessary data from the element.
* @param {HtmlElement} innerElement
* @returns
*/
async function extractData(innerElement) {
async function extractData(data) {
let count = await data.count();
if (count) {
return await data.innerText()
}
return null
};
// initializing xpath and selectors
const priceSelector = "[data-testid='property-price']"
const bedSelector = "[data-testid='property-beds']"
const bathSelector = "[data-testid='property-baths']"
const areaSelector = "[data-testid='property-floorSpace']"
const addressSelector = "[data-testid='property-address']"
// Extracting necessary data
let price = innerElement.locator(priceSelector);
price = await extractData(price);
let noOfBeds = innerElement.locator(bedSelector);
noOfBeds = await extractData(noOfBeds);
let noOfBaths = innerElement.locator(bathSelector);
noOfBaths = await extractData(noOfBaths);
let area = innerElement.locator(areaSelector);
area = await extractData(area);
let address = innerElement.locator(addressSelector);
address = await extractData(address)
// cleaning data
price = cleanData(price)
noOfBeds = cleanData(noOfBeds)
noOfBaths = cleanData(noOfBaths)
area = cleanData(area)
address = cleanData(address)
extractedData = {
"price": price,
"no of Beds": noOfBeds,
"no of Baths": noOfBaths,
'area': area,
'address': address
}
console.log(extractData)
return extractedData
}
/**
* The main function initiates a browser object and handles the navigation.
*/
async function run() {
// initializing browser and creating new page
const browser = await firefox.launch({ headless: false,proxy: {
server: '172.16.244.221:20225',
}});
const context = await browser.newContext();
const page = await context.newPage();
await page.setViewportSize({"width": 1920, "height": 1080});
// initializing xpaths and selectors
const xpathSearchBox = "[id='banner-search']";
const listingDivSelector = "[data-testid='home-card-sale']";
const totalResultsXpath = "//h2[contains(@class,'bcPATd')]";
const nextPageSelector = "[data-testid='pagination-next-page']";
// Navigating to the home page
await page.goto('https://www.trulia.com/', {
waitUntil: 'domcontentloaded',
timeout: 60000,
});
// Clicking the input field to enter the location
await page.waitForSelector(xpathSearchBox, { timeout: 60000 });
await page.click(xpathSearchBox);
await page.fill(xpathSearchBox, location);
await page.keyboard.press('Enter');
// Wait until the list of properties is loaded
await page.waitForSelector(listingDivSelector);
const totalResultCount = await page.locator(totalResultsXpath).innerText();
console.log(`Total results found - ${totalResultCount} for location - ${location}`);
// to store the extracted data
let data = [];
// navigating through pagination
for (let pageNum = 0; pageNum < maxPagination; pageNum++) {
await page.waitForLoadState("load", { timeout: 120000 });
await page.waitForTimeout(10);
let allVisibleElements = page.locator(listingDivSelector);
allVisibleElementsCount = 40;
// going through each listing element
for (let index = 0; index < allVisibleElementsCount; index++) {
await page.waitForTimeout(2000);
await page.waitForLoadState("load");
let innerElement = await allVisibleElements.nth(index);
await innerElement.hover();
innerElement = await allVisibleElements.nth(index);
let dataToSave = await extractData(innerElement);
data.push(dataToSave);
};
//to load next page
let nextPage = page.locator(nextPageSelector);
await nextPage.hover();
if (await nextPage.count()) {
await nextPage.click();
await page.waitForLoadState("domcontentloaded", { timeout: 120000 });
await page.waitForTimeout(10);
}
else { break };
};
saveData(data);
await context.close();
await browser.close();
};
run();This code shows how to scrape Trulia using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions, namely:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Trulia, fills in a search query, clicks the search button, and waits for the results to be displayed on the page.
The extract_data function is then called to extract the listing details and store the data in a Data.json file. - extract_data function: This function takes a Playwright page object as input and returns a list of dictionaries containing restaurant details. The details include each restaurant’s title, review count, rating, address, and phone.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Trulia script you just executed would be created.
Step 4: Run your code and collect the scraped data from Trulia.
Using No-Code Trulia Scraper by ScrapeHero Cloud
The Trulia Scraper by ScrapeHero Cloud is a convenient method for scraping data from Trulia. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the scraper.
1. Sign up or log in to your ScrapeHero Cloud account.
2. Go to the Trulia Scraper by ScrapeHero Cloud.
3. Click the Create New Project button.
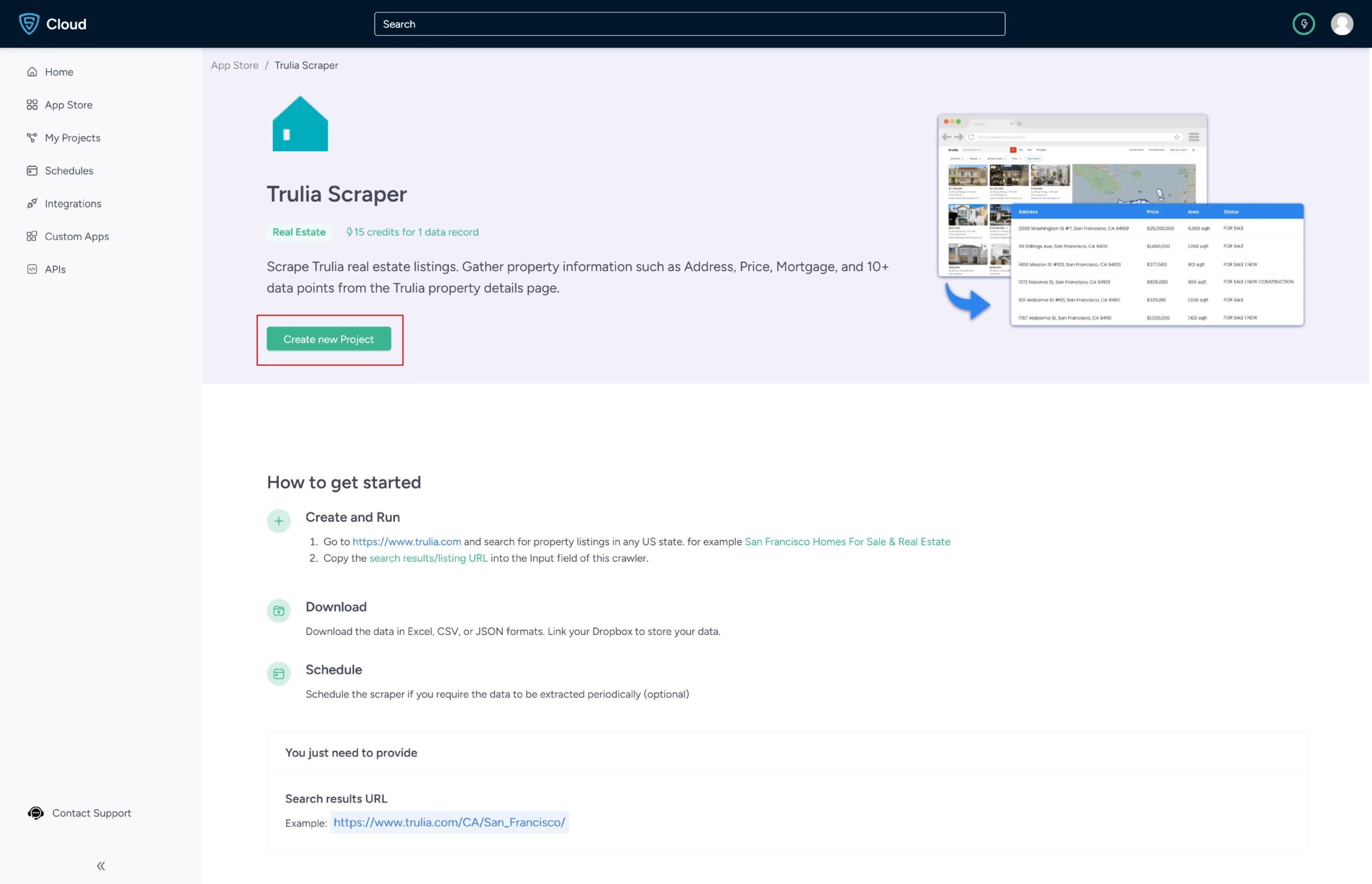
4. To scrape the details, you need to provide the Trulia search results URL for a specific search query.
5. You can get the URL from the Trulia search results page.
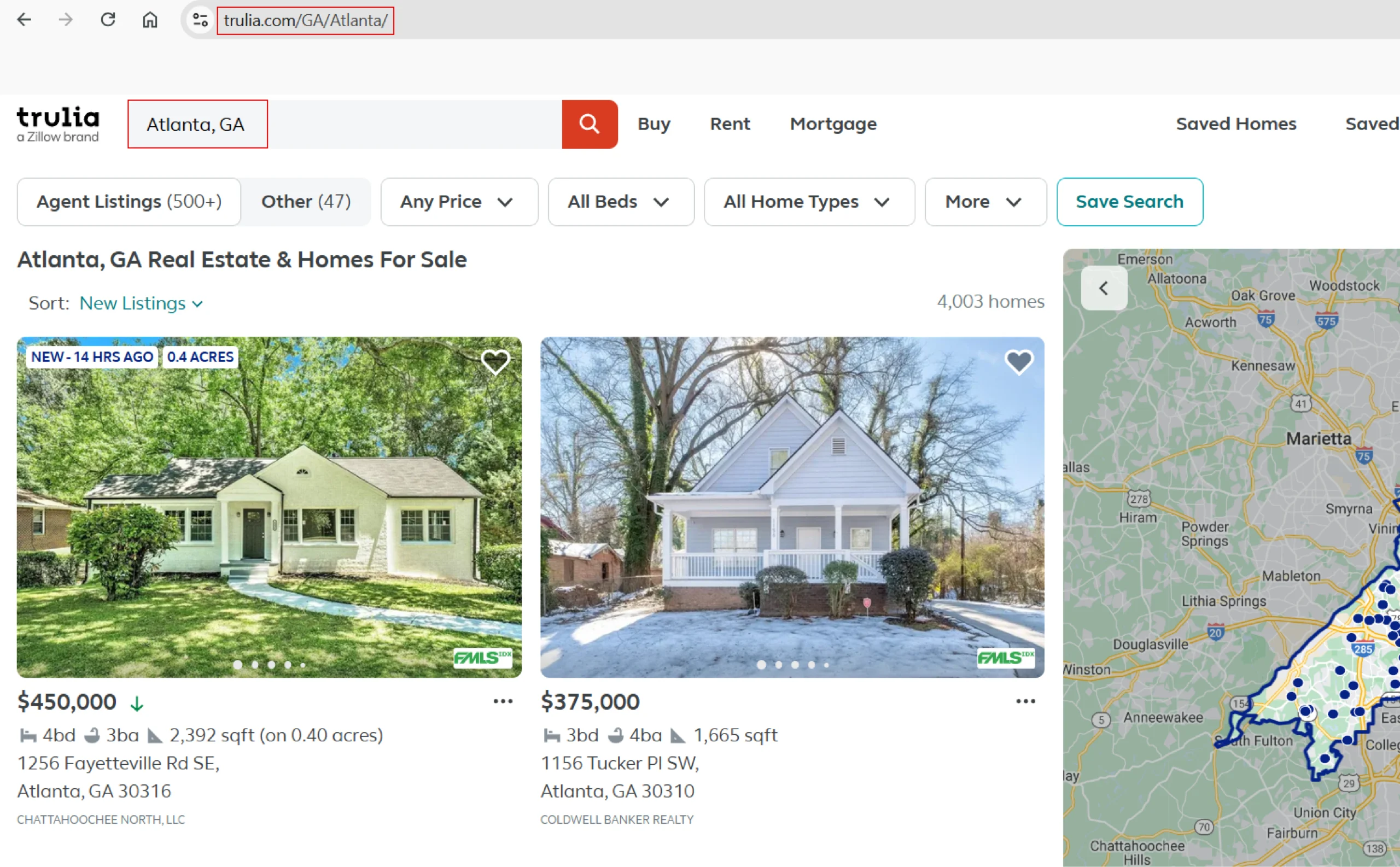
6. In the field provided, enter a project name, Trulia URL and the number of records you want to gather. Then, click the Gather Data button to start the scraper.
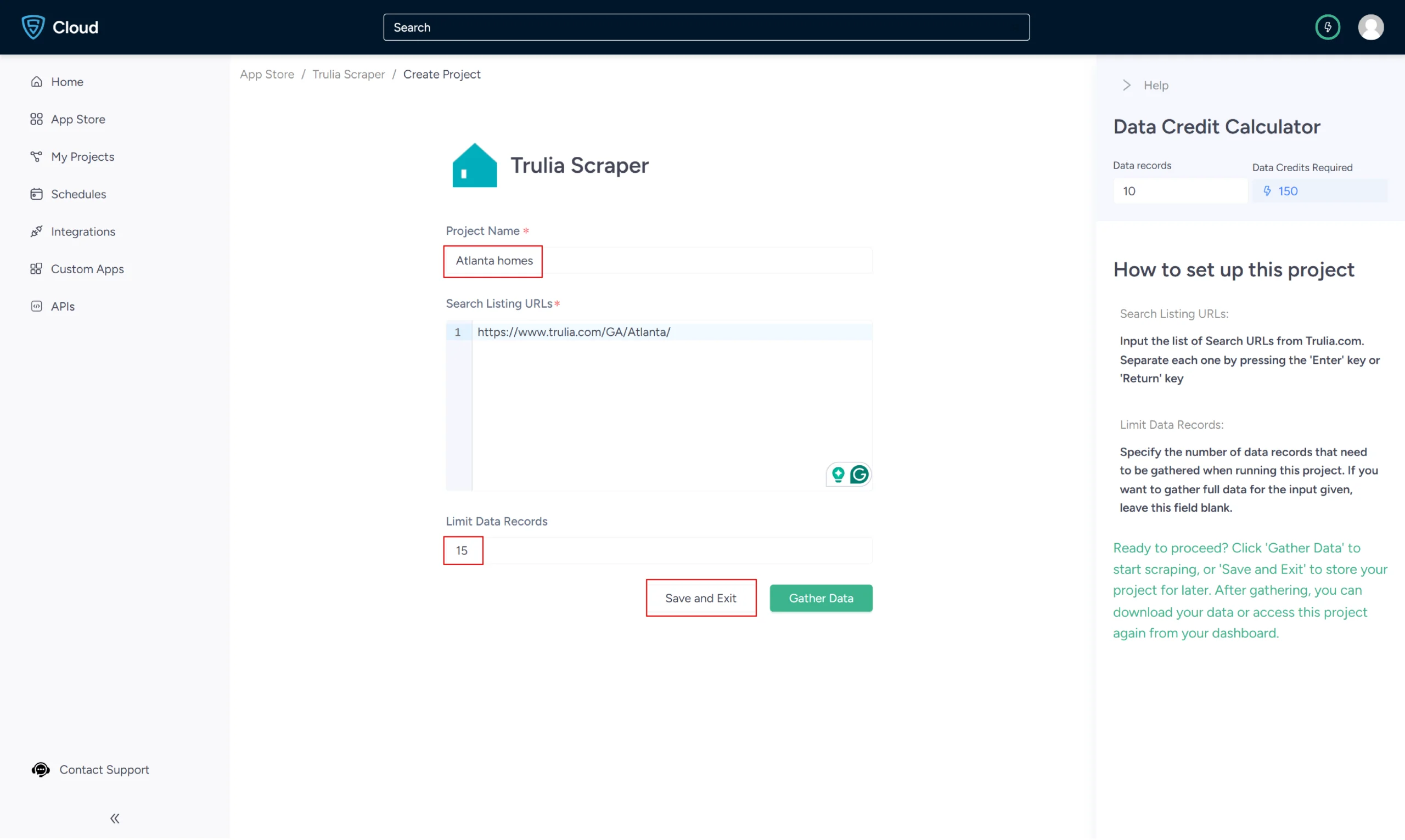
7. The scraper will start fetching data for your queries, and you can track its progress under the Projects tab.
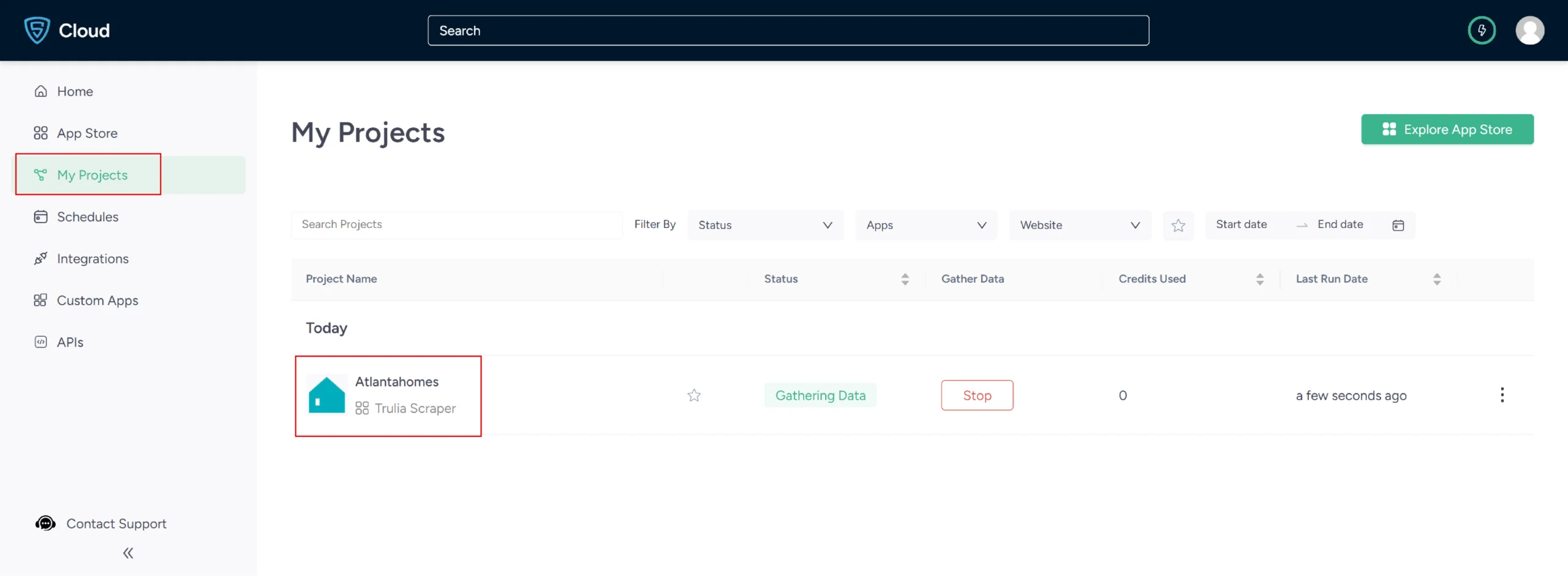
8. Once it is finished, you can view the data by clicking on the project name. A new page will appear, and under the Overview tab, you can see and download the data.
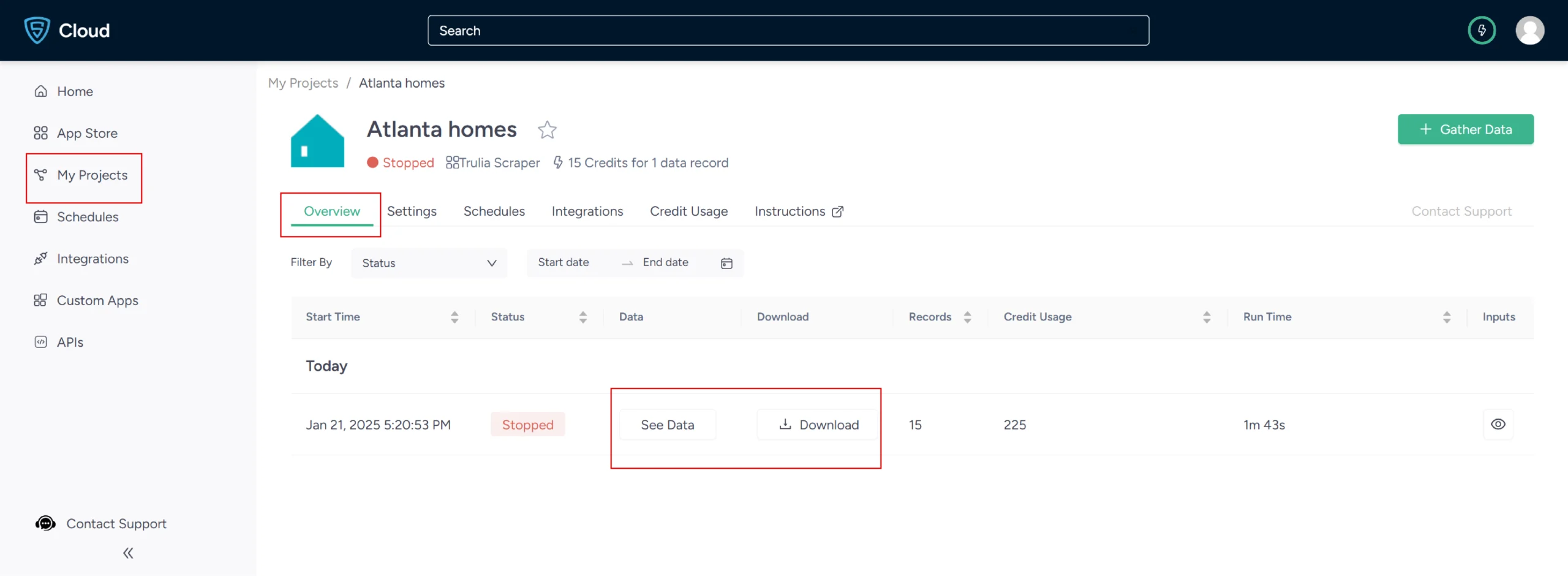
9. You can also pull Trulia data into a spreadsheet from here. Just click on Download Data, select Excel, and open the downloaded file using Microsoft Excel.
Uses Cases of Trulia Data
If you’re unsure as to why you should scrape Trulia, here are a few use cases where this data would be helpful:
-
Investment Insight
You can scrape data from Trulia for in-depth analysis of property prices, historical trends, and local features.
This empowers investors to target profitable areas, manage risks, and optimize their return on investment.
-
Smart Home-Buying
Use data to guide potential homeowners in comparing property prices, analyzing value trends, and evaluating amenities. This facilitates cost-effective and lifestyle-compatible buying decisions.
-
Professional Edge for Agents
Trulia data assists real estate professionals in understanding market averages, buyer preferences, and sales history. Agents can better match properties with buyers and set competitive listing prices.
-
Proactive Development Strategies
Builders can identify trending property features and preferences in targeted locations using Trulia data.
For instance, if energy-efficient homes are in demand, developers can include such features in new projects.
-
Data-Driven Urban Policies
Policy-makers and planners can make informed decisions on zoning and housing policies based on real estate data from Trulia.
If there’s a shortage of affordable housing, strategic initiatives can be devised to encourage the development of cost-effective housing options.
Frequently Asked Questions
Trulia data scraping refers to extracting real estate data from the real estate listings available on Trulia.com. This process allows for systematically collecting housing data displayed on this prominent real estate platform.
You can scrape data from Trulia with and without code. You can manually build a scraper using Python, JavaScript, etc.
You can also use a pre-built scraper like the Trulia Scraper from ScrapeHero Cloud to scrape data from Trulia without code.
No, Trulia does not have an API that you can use to gather publicly available data on their website, but you can use a Trulia Scraper to do the same.
ScrapeHero provides a comprehensive pricing plan for both Scrapers and APIs. To know more about the pricing, visit our pricing page.
The legality of web scraping depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
For more information, you can refer to our Legal information page.



