

Want to make web scraping faster? Read on to learn about two methods: Concurrency and Parallelism. They both reduce the code execution time, but their approach differs entirely.
This article covers both methods with examples in Python.
Concurrency vs. Parallelism
Concurrency and parallelism improve performance differently:
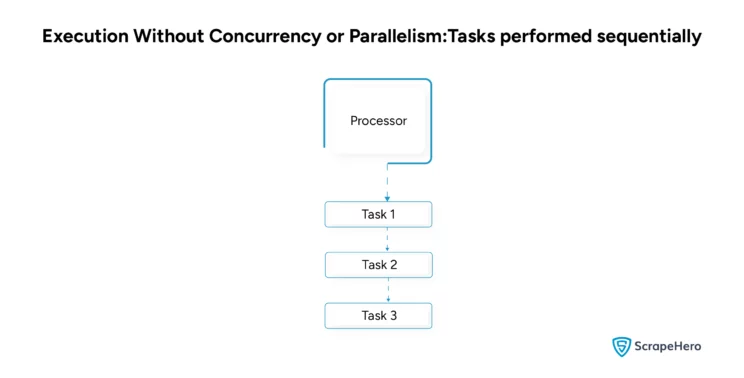
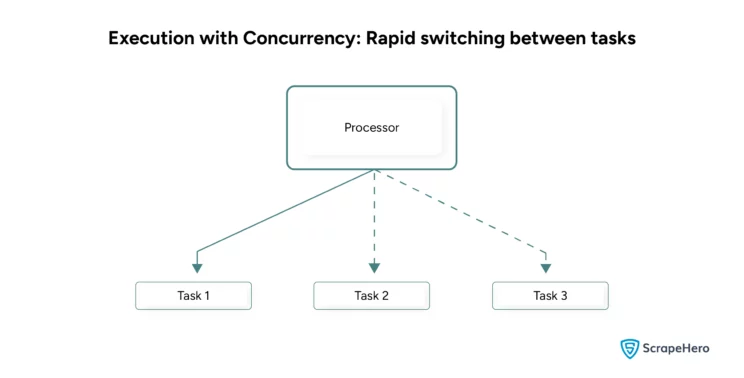
- Concurrency is when a single processor manages multiple tasks.
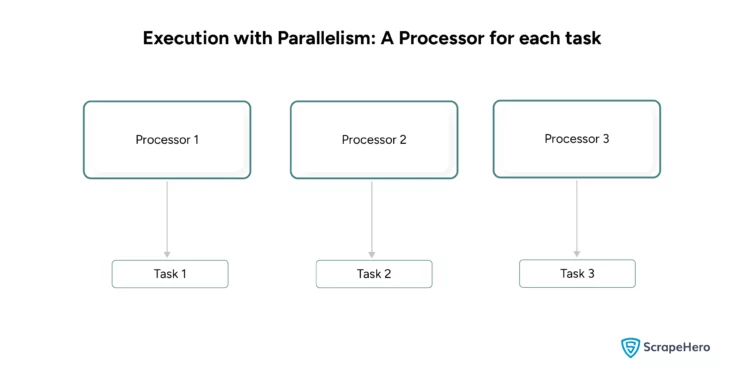
- In Parallelism, multiple processors manage the tasks where each performs only one.
The following table illustrates how exactly concurrency and parallelism differ.
|
Concurrency |
Parallelism |
| Requires only a single processor | Requires multiple processors |
| Preferred for less CPU-intensive tasks where there are idle periods | Preferred for CPU-intensive tasks that are independent |
| Example: when you browse the web with a task in the background, it is concurrency. The processor rapidly switches between web browsing and performing the background task. | Example: GPU processing is an example of parallelism. A GPU has many cores, each independently processing a part of an image or a video. |
| Concurrency uses threads that share memory. | Parallelism uses processes that have a separate memory. |
How to Make Web Scraping Faster Using Concurrency and Parallelism
You can use concurrency and parallelism in any programming language. Here, you will read how to make web scraping faster in Python.
Python has several modules for implementing concurrency and parallelism to make web scraping faster. This tutorial shows the example using two modules:
- ThreadPoolExecuter: This module helps you with concurrency. It uses threads called workers to manage multiple tasks.
- Multiprocessing: This module helps you achieve parallelism.
The Example
Here, you will see a code that scrapes the details of 100 companies. This code takes 1 minute to execute on Colab.
import csv
import requests
from lxml import html
def get_response(company_name: str) -> requests.Response:
"""
Retrieves html response by sending requests
Args:
company_name(str): Company name. This is used as a search term in the Google search URL
Returns:
requests.Response
"""
def scrape_data(input_company_names: list, output_file: str):
"""
Reads list of company names from the input file, extracts company data, and writes to CSV file
Args:
input_company_names(list): List of company names
output_file(str): Output file name
"""
company_details_list = []
for company in input_company_names:
response = get_response(company)
# If the response fails, even after retries, get_response won't return any response
if not response:
print(f'Invalid response for company name {company}')
continue
company_details = extract_company_details(response)
company_details['input_company_name'] = company
company_details_list.append(company_details)
write_csv(output_file, company_details_list)
def write_csv(file_name: str, company_details_list: list):
"""
Writes scraped data to CSV file
Args:
file_name: output file name
company_details_list: list of scraped company details
"""
if __name__ == "__main__":
company_names = [
"Facebook", "Twitter", "Microsoft", "Amazon", "Apple", "Netflix", "Spotify", "Adobe", "Salesforce", "Oracle",
"IBM", "Intel", "NVIDIA", "Samsung Electronics", "LG Electronics", "Sony", "Panasonic", "Dell Technologies",
"HP Inc.", "Cisco Systems", "Zoom Video Communications", "Dropbox", "Slack Technologies", "Square", "Shopify",
"Airbnb", "Uber", "Lyft", "Pinterest", "Snap Inc.", "Reddit", "TikTok", "ByteDance", "Alibaba Group", "Tencent",
"Baidu", "Xiaomi", "Huawei Technologies", "Lenovo Group", "ZTE Corporation", "Asus", "Acer", "Rakuten", "SoftBank Group",
"NTT Data", "SAP", "Siemens AG", "Philips", "Logitech", "Fitbit", "Garmin", "GoPro", "AMD", "Micron Technology",
"Western Digital", "Seagate Technology", "Kingston Technology", "Corsair Gaming", "Razer Inc.", "AsusTek Computer",
"MSI", "Gigabyte Technology", "Palit Microsystems", "Zotac", "EVGA Corporation", "Intel Corporation", "Qualcomm",
"Broadcom Inc.", "Texas Instruments", "ARM Holdings", "TSMC", "SK Hynix", "MediaTek", "Infineon Technologies",
"STMicroelectronics", "NXP Semiconductors", "Renesas Electronics", "Analog Devices", "Microchip Technology",
"ON Semiconductor", "Kyocera", "Sharp Corporation", "Toshiba", "Fujitsu", "NEC Corporation", "Hitachi",
"Kaspersky Lab", "Symantec", "McAfee", "Trend Micro", "Avast", "Fortinet", "Check Point Software Technologies",
"Palo Alto Networks", "SolarWinds", "Atlassian", "Twilio", "Akamai Technologies", "Cloudflare", "Fastly"
]
output_file_name = 'company_details.csv'
scrape_data(company_names, output_file_name)
However, it takes only 14 seconds if you use the ThreadPoolExecuter. Here is how you import ThreadPoolExecutor.
from concurrent.futures import ThreadPoolExecutor, as_completed
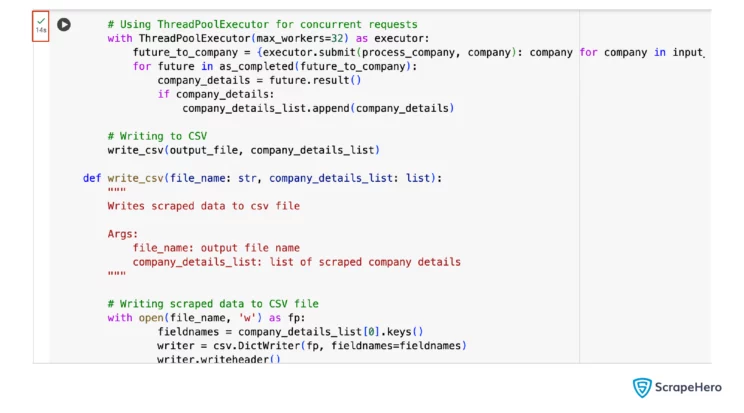
You only have to modify the scrape_data() function to implement concurrency. The scrape_data() function will now have the extra process_company(); ThreadPoolExecutor will use this function to implement concurrency.
Each worker executes a task, calling the process_company() function with the company name as the argument. You can set the maximum number of workers, which sets the maximum number of concurrent operations.
Here, you can see that the maximum number of workers is 10; the code can scrape the details of 10 companies concurrently.
def scrape_data(input_company_names: list, output_file: str):
"""
Reads list of company names, extracts company data concurrently and writes to CSV file
Args:
input_company_names(list): List of company names
output_file(str): Output file name
"""
company_details_list = []
# Function to process each company name
def process_company(company):
response = get_response(company)
if response:
details = extract_company_details(response)
details['input_company_name'] = company
return details
else:
print(f'Invalid response for company name {company}')
return None
# Using ThreadPoolExecutor for concurrent requests
with ThreadPoolExecutor(max_workers=32) as executor:
future_to_company = {executor.submit(process_company, company): company for company in input_company_names}
for future in as_completed(future_to_company):
company_details = future.result()
if company_details:
company_details_list.append(company_details)
# Writing to CSV
write_csv(output_file, company_details_list)
With parallelism using multiprocessing, you can achieve the same task in around 29 seconds, still better than the original code. You need to use the Pool object from the multiprocessing module to implement parallelism.
from multiprocessing import Pool
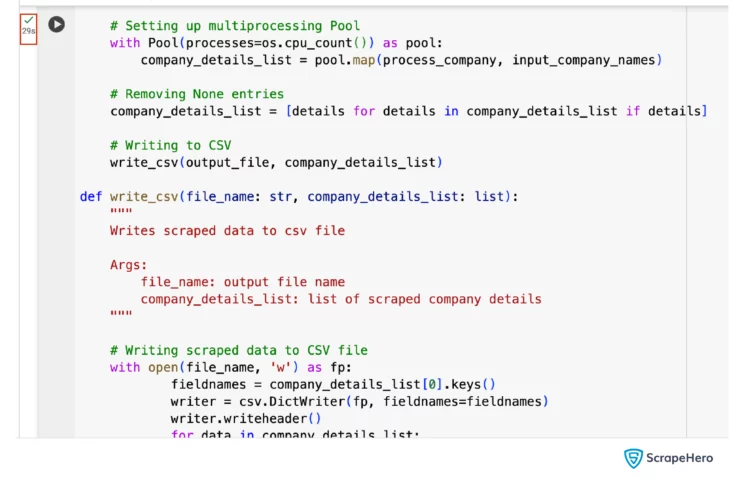
Again, you must modify the original scrape_data() to achieve parallelism. You also must add another function, process_company(), outside scrape_data().
The process_company() function takes a company name and returns its details. This code executes this step using the multiprocessing module. That means there will be multiple simultaneous calls of process_company().
def process_company(company):
"""
Process a single company, fetching and extracting data.
Args:
company (str): Company name.
Returns:
dict: Extracted company data or None if failed.
"""
response = get_response(company)
if response:
details = extract_company_details(response)
details['input_company_name'] = company
return details
else:
print(f'Invalid response for company name {company}')
return None
def scrape_data(input_company_names: list, output_file: str):
"""
Reads list of company names, extracts company data in parallel using multiprocessing and writes to CSV file
Args:
input_company_names(list): List of company names
output_file(str): Output file name
"""
company_details_list = []
# Setting up multiprocessing Pool
with Pool(processes=os.cpu_count()) as pool:
company_details_list = pool.map(process_company, input_company_names)
# Removing None entries
company_details_list = [details for details in company_details_list if details]
# Writing to CSV
write_csv(output_file, company_details_list)
Which Option is Better for Making Web Scraping Faster?
The fastest way to scrape a website depends on the use case and available resources.
Here, the code using concurrency was faster than the code using parallelism. The reason is that web scraping involves a lot of waiting.
You must wait a little before the server responds with the required data. During this time, the processor is available for another task. Concurrency leverages this window.
However, the code that uses parallelism requires separate processors for each simultaneous task. The code shown in the tutorial ran on Colab with only 2 processors. Therefore, the execution is substantially less efficient than using a ThreadPoolExecuter with 10 workers.
That means
- Use concurrency when you have limited resources for web scraping
- Implement parallelism when you have enough processors and the tasks are CPU intensive.
Challenges in Making Web Scraping Faster
The two main challenges you will face are
- Code complexity: The code will become quite complex, increasing the probability of errors and difficulty in debugging.
- Rate limiting: Websites use rate-limiting measures to prevent anyone from accessing their data above a specific rate.
- Lack of Resources: Programming alone can’t speed up web scraping. The lack of resources will limit it, especially in the case of parallelism.
Are There Other Tips for Fast Web Scraping?
We only discussed concurrency and parallelism here. However, consider the following tips to improve performance while web scraping.
- Use headless browsers for web scraping to reduce resource consumption.
- Don’t launch a new browser context for every start page.
- Avoid downloading all the resources to save bandwidth.
- Use browsers to scrape websites only if HTTP request methods fail.
Conclusion
Using concurrency and parallelism can speed up web scraping. However, you must be well-versed in coding and have enough resources to support it.
If you want to avoid coding yourself or invest in resources for faster web scraping, try ScrapeHero Services.
ScrapeHero is a full-service web scraping service provider. Our infrastructure can scrape data at 3000 pages per second. We have the resources and skills to provide enterprise-grade scraping services tailored to your needs.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


