

The data extracted after web scraping is unstructured and difficult to work with. Then how could you transform this unstructured data into a structured or readable format? This is where a crucial step in web scraping comes in: Data parsing.
This article is all about data parsing, its importance in web scraping, how it is different from data scraping, common data parsing techniques used, and much more.
What Is Data Parsing?
Data parsing in web scraping is a process that transforms unstructured data, like HTML, into structured, readable formats. It involves mainly two steps:
- Lexical Analysis – Breaks down data into tokens, like numbers or strings
- Syntactic Analysis – Organizes these tokens into a parse tree and makes the data easier to use
This organization is vital as it integrates data from different sources into a single format. It also simplifies the analysis and supports data-driven decision-making.
What Is a Data Parser? How Does a Data Parser Work?
A data parser is a tool that receives data in one format and returns it in a new format. Data parsing in web scraping relies on data parsers and can be built in different programming languages.
Numerous libraries and APIs are available for parsing data in Python. For instance, Python Pandas for Excel files, Python Requests for handling web requests for APIs, and more complex data interactions.
Now let’s see how a data parser works with an example. To parse an HTML document, the HTML parser will:
- Input an HTML document
- Load and store the HTML as a string
- Extract key information by parsing the HTML string
- Refine and cleanse the data during parsing, as needed
- Output the parsed data as a JSON, YAML, or CSV file, or store it in a SQL or NoSQL database
Why Is Data Parsing in Web Scraping Important?
Web scraping uses data parsing to organize unstructured information from websites into a clear and structured format. This step is crucial because it helps clean the data and make it readable, which is necessary for accurate analysis.
Data parsing in Python greatly affects the quality of the data collected. It cleans up the data, speeds up the processing, helps handle errors, and adapts to changes in website layouts, making the data more useful for analysis and applications.
What Is the Difference Between Data Scraping and Data Parsing?
Data scraping and data parsing are two separate processes in data extraction. Data scraping involves the retrieval of information from websites, including HTML content, metadata, and multimedia elements. It must be approached with careful attention to legal considerations, ensuring ethical data extraction.
On the other hand, data parsing converts unstructured data to a structured format for analysis or database insertion. It deals with predefined data formats such as JSON or XML. Unlike scraping, parsing generally doesn’t involve legal issues unless the data is obtained illegally.
| Aspect | Data Scraping | Data Parsing |
| Process | Extracting data from websites/web pages | Analyzing and breaking down structured data |
| Scope | Broad: Includes HTML, metadata, multimedia | Specific: Deals with structured formats like JSON, XML, CSV |
| Purpose | Gathering data for various purposes | Extracting specific information for analysis or storage |
| Complexity | Can be complex, especially with dynamic sites | Can be simpler, but complexity depends on data structure |
| Legal Implications | Often in a legal gray area, may infringe TOS or copyrights | Generally legal if data is obtained legally, but usage may have legal constraints |
Example of Raw HTML Data
Given is an example of raw HTML data for a simple e-commerce product page. This HTML snippet contains the data generally found on an online store, like basic information about a product:
Line 1 <!DOCTYPE html> Line 2 <html lang="en"> Line 3 <head> Line 4 <meta charset="UTF-8"> Line 5 <meta name="viewport" content="width=device-width, initial-scale=1.0"> Line 6 <title>Sample Product Page</title> Line 7 </head> Line 8 <body> Line 9 <header> Line 10 <h1>Sample Online Store</h1> Line 11 </header> Line 12 <section> Line 13 <h2>Classic Blue T-Shirt</h2> Line 14 <img src="blue-tshirt.jpg" alt="Blue T-shirt" width="200"> Line 15 <p>Price: $19.99</p> Line 16 <p>Description: This classic blue t-shirt is perfect for any occasion. Made from 100% cotton, it offers comfort and durability.</p> Line 17 <button>Add to Cart</button> Line 18 </section> Line 19 <footer> Line 20 <p>Contact us at contact@example.com</p> Line 21 </footer> Line 22 </body> Line 23 </html>
This HTML includes:
The DOCTYPE declaration and <html> element, specifying the language as English.
A <head> section with meta tags for character set and viewport settings, and a <title> for the page.
A <body> containing the main content:
A <header> with the name of the online store – line 9
A <section> that describes a product, including:
A heading (<h2>) with the product name – line 13
An image (<img>) of the product with an alternative text description – line 14
Two paragraphs (<p>) detailing the price and a description of the product – lines 15 and 16
A button to add the item to a shopping cart – line 17
A <footer> with a contact email address – line 19
Example of Parsed Data
Now let’s see how the raw HTML from the above example is converted into parsed data in the JSON format. This JSON object represents the product details extracted from the HTML, organized in a way that is easy to use programmatically:
Line 1 { Line 2 "storeName": "Sample Online Store", Line 3 "product": { Line 4 "name": "Classic Blue T-Shirt", Line 5 "image": "blue-tshirt.jpg", Line 6 "price": "$19.99", Line 7 "description": "This classic blue t-shirt is perfect for any occasion. Made from 100% cotton, it offers comfort and durability." Line 8 }, Line 9 "contactEmail": "contact@example.com" Line 10 }
In this JSON structure:
“storeName” captures the name of the online store from the header – line 2
“product” is an object that contains:
“name”: the name of the product – line 4
“image”: the file path or URL to the product image – line 5
“price”: the price of the product – line 6
“description”: a description of the product, highlighting key features like material and suitability – line 7
“contactEmail” stores the contact information from the footer – line 9
How To Parse Data in Python
Let’s look at how data is parsed considering a sample web page, ScrapeMe.
Steps:
- Identify Elements – Open the webpage in a browser and use the developer tools ( right-click on the page and select “Inspect”) to locate the HTML elements containing the data.
- HTML Structure – Determine the HTML structure that contains the product information. Based on the image, products are likely structured within list items (<li> tags) with classes identifying them as products.
- Select Data – Decide the pieces of information that you want to extract, for instance, the product names, prices, and image URLs.
- Write Parsing Logic – Using a web scraping library like BeautifulSoup, write the code that targets the specific CSS classes or XPath expressions that match your selected elements.
- Execute Parser – Run the parsing code to extract the data. The code navigates the HTML structure and collects the content of the targeted elements.
- Store Data – Format and save the extracted data into a structured file or database.
- Handle Pagination – When dealing with multiple pages of products, implement logic to navigate through each page and repeat the data extraction process.
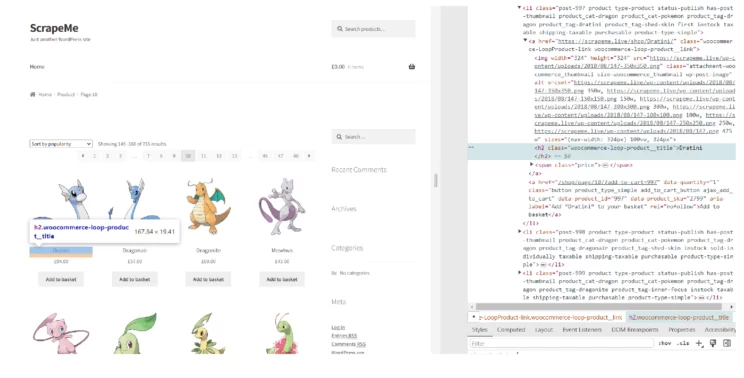
The parsed data might look like the following in JSON format, extracted from the information visible in the image:
[
{
"productName": "Dratini",
"price": "£94.00",
"imageSrc": "path_to_image/dratini.jpg"
},
{
"productName": "Dragonair",
"price": "£57.00",
"imageSrc": "path_to_image/dragonair.jpg"
},
{
"productName": "Dragonite",
"price": "£69.00",
"imageSrc": "path_to_image/dragonite.jpg"
},
// ... other products
]
Some Common Data Parsing Techniques
Data parsing in Python transforms data enhancing manageability and usability for specific applications. There are various parsing techniques used for different data types. Each of these parsing techniques is implemented using various programming languages and libraries designed to handle specific data formats.
-
String Parsing
String parsing breaks down data into smaller parts in order to locate and extract relevant data. It is commonly used for tasks like locating specific keywords in a document or obtaining information from URLs.
-
Regular Expression (regex) Parsing
Regular expression (regex) parsing uses character sequence patterns, known as regular expressions, in order to extract data from unstructured sources. This method is apt at finding specific patterns of letters and numbers, like phone numbers or email addresses, in text.
-
XML Parsing
XML parsing extracts data by deconstructing the document into its elemental components and attributes. This method focuses on XML documents and is effective for data retrieval.
-
JSON Parsing
JSON parsing is similar to XML parsing and is for JSON documents. This technique breaks down JSON data into its constituent key-value pairs for information extraction.
-
HTML Parsing
HTML parsing extracts data from HTML documents. It involves breaking down the basic HTML structure into parts like tags and attributes, allowing for the retrieval of necessary data.
Popular HTML Parsing Tools
HTML parsing is a popular technique in web data extraction. So many tools are used for HTML parsing to extract information from HTML files. Some of them include:
1. Python HTML Parsers
BeautifulSoup
BeautifulSoup is a highly popular Python library for web scraping and parsing HTML data. It is known for its simplicity and versatility. BeautifulSoup constructs a hierarchical ‘soup’ structure from HTML documents, facilitating easy navigation and data extraction using functions like find_all(), find(), and select().
Here’s how to initiate BeautifulSoup for parsing:
pip install beautifulsoup4
from bs4 import BeautifulSoup
import requests
# Example URL
url = 'http://example.com'
# Fetching the webpage
response = requests.get(url)
response.raise_for_status() # Raises an HTTPError for bad responses
# Using Beautiful Soup to parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Now you can use `soup` to navigate and search the parsed HTML tree
print(soup.prettify()) # Print the nicely formatted HTML
PyQuery
PyQuery is a Python tool that makes working with HTML documents easier, especially for developers who are familiar with jQuery’s syntax. It allows adding, modifying, and changing the HTML elements using simple commands.
Here’s how to initiate PyQuery for parsing:
pip install pyquery
from pyquery import PyQuery as pq
import requests
# Example URL
url = 'http://example.com'
# Fetching the webpage
response = requests.get(url)
response.raise_for_status() # Raises an HTTPError for bad responses
# Using PyQuery to parse the HTML content
doc = pq(response.text)
# Now you can use `doc` to navigate and search the parsed HTML tree
print(doc)
2. JavaScript HTML Parsers
Cheerio is a tool for JavaScript developers that works quickly and flexibly, using jQuery’s style but on servers. With Cheerio, developers can easily change and move through the structure of HTML documents using familiar commands.
Here’s how to initiate Cheerio for parsing:
like jQuery to navigate and search the parsed HTML tree console.log($('title').text()); // Example: prints the content of the <title> tag } catch (error) { console.error('Error fetching the page: ', error); } } // Call the function with the URL fetchAndParse(url);
jQuery
jQuery is not a traditional HTML parser but has greatly influenced how developers work with HTML on websites. jQuery is used on the client side (in web browsers), and it has inspired server-side tools like Cheerio and pyQuery.
Here’s how to initiate jQuery for parsing:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <!-- Include jQuery from CDN --> <script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script> </head> <body> <div id="content">Hello, world!</div> <script> // Document ready function to ensure the DOM is fully loaded $(document).ready(function() { // Using jQuery to select and manipulate HTML elements var content = $('#content').text(); console.log(content); // Outputs: Hello, world! }); </script> </body> </html>
Challenges in Data Parsing in Python
Even though data parsing in Python is relatively straightforward, it has its own challenges and limitations. Here are some common challenges in data parsing:
- Changing Page Structure – When websites like e-commerce sites update their HTML structure, this can break parsers, requiring frequent adjustments.
- Inconsistent Formatting – Data points may vary in format across different pages, so special rules to recognize and organize them consistently might be needed.
- JavaScript-generated HTML – Pages with HTML generated via JavaScript may not have typical attributes, which complicates navigation and data extraction.
- Errors and Inconsistencies – When inputs contain errors or inconsistencies like unclosed tags or invalid HTML, parsing becomes difficult.
- Handling Large Data Volumes – For parsing large datasets, more resources are required. So multiple processes at once should be used, which enhance efficiency but increase complexity.
- Handling Diverse Data Formats – Since data formats evolve quickly, parsers also must be up-to-date and versatile to handle various input and output formats.
- Data Quality – When the quality of data is poor, such as due to missing or inconsistent information, it can lead to inaccurate analysis, requiring sophisticated data cleaning processes.
- Data Complexity – Complex data structures or unstructured data like text or images require more advanced parsing techniques compared to structured data.
Building vs. Buying a Data Parsing Tool
Whether to build or buy a data parsing tool is a decision that must be made considering several factors, such as the flexibility, control, cost, and efficiency of the data parsing process. Let’s discuss the pros and cons of each option:
Building Your Own Data Parser
Pros:
- Customization of the parser according to specific needs and integration with existing tools
- Full ownership and control over the development and maintenance of the software
- Long-term cost efficiency if the tool is used extensively
Cons:
- Significant time and money investments are needed for development, maintenance, and server hosting
- Requires continuous updates and security measures
- Costs for staff, servers, and other infrastructure can add up
Buying a Commercial Data Parsing Tool
Pros:
- Quick deployment when needed
- The provider handles updates, maintenance, and security
- Predictable costs without the need for ongoing large investments in infrastructure
Cons:
- Limited control over the tool’s functionality and integration with existing systems
- Long-term costs could exceed those of building a custom solution if usage is high
- The tool may not adapt well to future needs or changes in data formats
Wrapping Up
Data parsing in Python is an unavoidable step in web scraping, as it is required to convert unstructured data extracted from web pages into a structured format. The challenges that come with data parsing are also not easy to deal with, especially for smaller organizations.
At ScrapeHero, we understand the specific challenges involved in data scraping and data parsing. We provide pre-built scrapers and APIs via ScrapeHero Cloud that are ready to use, saving time and resources.
Businesses seeking to optimize their data parsing and scraping strategies on a large scale can consult ScrapeHero web scraping services and significantly enhance their business growth.
Frequently Asked Questions
To parse a file in Python, read its contents, and extract the data into a structured format later to analyze and manipulate. In data parsing, different data formats like CSV, JSON, XML, or HTML are handled.
You can parse output in Python by importing the json module and then using json.loads() to convert a JSON string into a Python object for further processing.
import json
parsed_data = json.loads(output_string)Parsing data in Python often involves reading JSON, XML, or CSV files. These are then converted into Python data structures like dictionaries or lists. Built-in libraries like json and xml.etree.ElementTree, or csv, are used to extract structured data from these formats.
To parse an HTML tree in Python, use the BeautifulSoup library from bs4. This creates a BeautifulSoup object to navigate and extract data from HTML content. Then using the Requests library fetch the HTML. Later utilize BeautifulSoup’s methods like find() and find_all() to explore the parsed HTML.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



