

RPA stands for robotic process automation. It aims to automate mundane processes to make businesses more efficient. Web scraping involves programmatically gathering data. Although both are distinct activities, you may use them together.
Read on to learn the difference between web scraping and robotic process automation and how they work together.
What is web scraping?
Web scraping gathers data from the internet using a computer program. It is similar to copying and pasting information from a web page but faster.
Web scraping has three main steps:
- Accessing the web pages in HTML
- Parsing the contents
- Storing the extracted data in a file
The usual method for accessing a web page’s HTML content is to send an HTTP request. The response will contain the HTML data.
However, some websites use JavaScript to display content dynamically. As HTTP requests cannot render JavaScrpit, they are unsuitable for scraping a dynamic website.
Scraping data from these sites is only possible if you mimic human behavior. That means opening the website with a browser and clicking on links until you reach the web page you wish to scrape.
Therefore, you must automate these steps to get the required data; this is where you automate web scraping with RPA.
What is RPA?
Robotic process automation, or RPA, automates routine steps, including clicking, logging in, and filing information. For example, if you want to search for a keyword, find the search results, and save them into a file, you can automate these steps using RPA.
You can consider RPA as a part of BPA, or business process automation, where you perform end-to-end automation of the entire business process. RPA only automates repetitive tasks.
RPA is more accessible than programming and is unlike traditional automation, which uses scripts. You can use the prebuilt modules of an RPA suite to create and automate your processes. For the steps mentioned above, the suite will have modules. It will have a module for searching the web for information, extracting it, opening an Excel file, and adding the search results.
Here are the primary characteristics of the processes that you can automate using RPA:
- Rule-based without having complex decisions: RPA is unsuitable for tasks where you must make complex decisions.
- Repetitive in high volumes: Processes that occur very frequently are best suited for RPA automation.
- Uses structured data: RPA won’t be able to handle unstructured data.
- Doesn’t change frequently: The RPA bot will fail to execute the processes if they change frequently.
Types of RPA
- Off-the-shelf RPAs: These RPAs have a fixed number of modules you can use. You can use these modules to automate various processes; they provide a user-friendly UI for adding the modules to create your workflow.
- Custom RPAs: Services that provide custom RPAs. They will create customized RPAs based on your business.
While off-the-shelf RPAs are cheaper than custom RPAs, they may not handle complex automation specific to your business. However, you can use web scraping with either of them.
Using web scraping with RPA
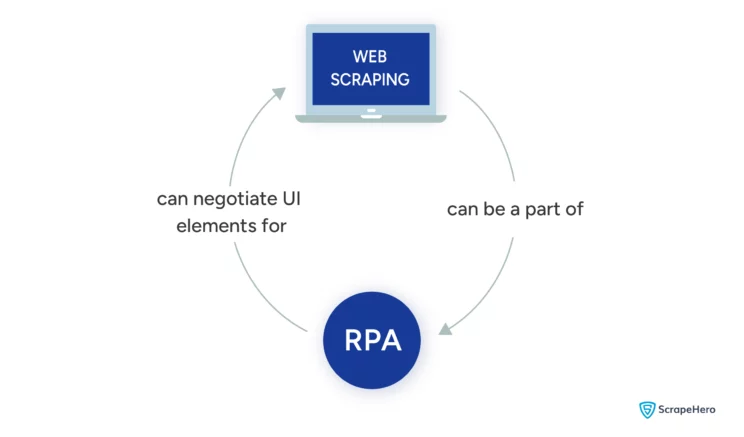
You can use web scraping with RPA in two ways:
Web Scraping as a Part of RPA
Using web scraping as a part of robotic process automation is possible.
For example, consider a process where you need to get data from a website, such as Google News, and send an email with the file containing the data.
Here, the part where you get news headlines is web scraping.
You can automate such a process using RPA. An off-the-shelf RPA suite will have modules for opening a browser, visiting a website, extracting information, and sending an email.
RPA Facilitating Web Scraping
RPA and web scraping can also work together. RPA can help you navigate complex websites that use JavaScript for web scraping.
For such websites, you may need several sub-processes to extract data. You may need to perform several actions, including logging in, scrolling a certain amount, clicking buttons, and filling in information.
In the above example of Google News, the part where you traverse the Google News UI is how RPA facilitates web scraping.
This flowchart integrates both the methods of using web scraping with RPA.

Neither of the methods for using web scraping with RPA requires technical expertise. For an off-the-shelf RPA suite, you only need to build a flow using the available modules. You don’t have to do even that if you choose a custom RPA service.
In contrast, traditional automation methods require you to write a script for the same flow.
from playwright.async_api import async_playwright
import pandas
import asyncio
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email import encoders
import os
from time import sleep
async def getNews():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("https://news.google.com")
business = page.locator("//a[@aria-label='Business']")
await business.click()
articles = await page.locator("//a[@class='gPFEn']").all()
topics =[]
print("got topics")
for article in articles[:10]:
topic = await article.inner_text()
print("got the name ",topic)
href = await article.get_attribute('href')
newPage = await browser.new_page(java_script_enabled=False)
newPage.set_default_timeout(300000)
goto = "https://news.google.com"+href[1:]
await newPage.goto(goto)
url = await newPage.locator("//div[@class='m2L3rb']//a").get_attribute('href')
print("got the url ",url)
await newPage.close()
topics.append(
{
"News":topic,
"Link":url
}
)
return topics
async def send_email_with_attachment_async():
# Get the full filepath (assuming the file is in the same directory)
filename = "news.csv"
filepath = os.path.join(os.path.dirname(__file__), filename)
body = "Here are the top news of the day. Enjoy!"
sender_email = ""
receiver_email = ""
your_password = ""
# Create message container
message = MIMEMultipart()
message["From"] = sender_email
message["To"] = receiver_email
message["Subject"] = "Top News"
# Add body content
message.attach(MIMEText(body, "plain"))
# Open and attach the file
with open(filepath, "rb") as attachment:
# Get attachment details
part = MIMEBase("application", "octet-stream")
part.set_payload(attachment.read())
encoders.encode_base64(part)
part.add_header("Content-Disposition", f"attachment; filename={filename}")
message.attach(part)
# Send the email
with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
server.login(sender_email, your_password) # Replace "your_password" with your actual password
server.sendmail(sender_email, receiver_email, message.as_string())
async def main():
topics = await getNews()
df = pandas.DataFrame(topics)
df.to_csv("news.csv")
await send_email_with_attachment_async()
asyncio.run(main())
The above Python script gets a list of news headlines and their links from Google News and emails the list. You can see that building such a script would require technical expertise.
Wrapping Up
RPA and web scraping are complementary.
You can perform web scraping automation with RPA by directly using RPA for web data extraction, or you can use web scraping as one of the processes in your RPA workflow.
An RPA suite or an RPA service provider can help you build the RPA workflow for your business.
While cheaper, an RPA suite may not suit your specific business process. However, custom RPA service providers, like ScrapeHero, can create custom RPA bots to meet your needs.
ScrapeHero is a full-service web scraping and RPA service provider. We can build enterprise-grade, high-quality web scrapers and highly scalable RPA bots customized to your needs.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



