

YouTube is a dynamic website that delivers its content by executing JavaScript. The website doesn’t work without JavaScript. Although you can use automated browsers to execute JavScript, they may be unnecessary for scraping data from YouTube.
The information is already available in one of the script tags of the YouTube page as a JSON string. Scraping this information does not require JavScript execution. Therefore, HTTP requests are enough for web scraping YouTube.
This article tells you how to perform YouTube web scraping with Python requests, json module, and BeautifulSoup.
Data Scraped from YouTube
This tutorial scrapes six data points from the YouTube search results.
- Title
- Description
- Duration
- View Count
- Published On
- URL
- Channel Details
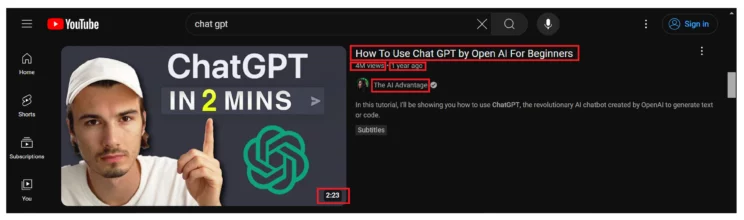
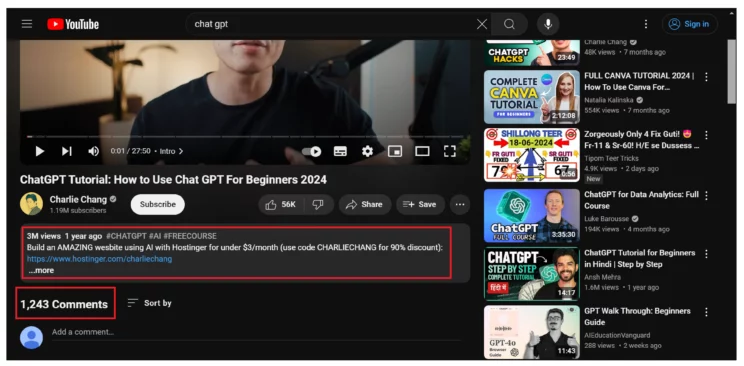
It also extracts two data points from the video page.
- Number of Comments
- Description
Web Scraping YouTube: The environment
The code uses four Python packages for YouTube web scraping:
- Requests: A library designed to manage HTTP requests
- BeautifulSoup: A popular library with intuitive methods to extract data from HTML/XML code
- The json module: A module included in the Python standard library for managing JSON data
- The re module: Another module included in the Python standard library for using RegEx
Requests and BeautifulSoup are external Python libraries that require installation. You can use Python’s package manager, pip, to install them.
pip install bs4 requestsWeb Scraping YouTube with Python: The code

First, import the packages mentioned above.
from bs4 import BeautifulSoup
import re, json, requestsYou can now use Python requests to make HTTP requests to the YouTube search results page from which you wish to scrape video details.
content = requests.get("https://www.youtube.com/results?search_query=chat+gpt").textThe response text will contain HTML data; pass this to the BeautifulSoup for parsing.
soup = BeautifulSoup(content,"lxml")Note: Use lxml while parsing with BeautifulSoup; using “html.parser” might give you errors when you try to load the extracted JSON string.
Analyzing the source code will reveal that the details of each video listing are inside the key “videoRenderer.”
Therefore, to find the required script containing YouTube data, find all the scripts using the find_all method of BeautifulSoup.
scripts = soup.find_all("script")Then, you can iterate through the scripts to
- check if any script has the text “videoRenderer,”
- extract data from that script
- Save the data to a dict
An if statement can check if the the script contains the text “videoRenderer”
if "videoRenderer" in script.text:The extracted script text contains the JSON string, which you can get using RegEx.
groups=re.search(r"({.+})",script.text)Now, load the JSON string to create a JSON object. From this object, you can find the required data.
jsonObject = json.loads(groups[0])In the JSON object, the details about the video will be inside the keys named “videoRenderer.” These keys are a part of an array that includes other renderers. Therefore, you must iterate through the array to get the value of “videoRenderer.”
First, find the array that has renderers.
sectionList = jsonObject['contents']['twoColumnSearchResultsRenderer']['primaryContents']['sectionListRenderer']
renderers = sectionList['contents'][0]['itemSectionRenderer']['contents']Then, you can iterate through renders.
for renderer in renderers:You will encounter other renderers when iterating through the array. Therefore, use try-except blocks to avoid errors.
Extract the six data points mentioned above from the search results page.
try:
video = renderer['videoRenderer']
videoLength = video['lengthText']['simpleText']
channelName = video['longBylineText']['runs'][0]['text']
title = video['title']['runs'][0]['text']
videoUrl = "https://youtube.com/watch?v="+video['videoId']
publishedOn = video['publishedTimeText']['simpleText']
channelUrl = "https://youtube.com"+video['shortBylineText']['runs'][0]['navigationEndpoint']['commandMetadata']['webCommandMetadata']['url']
viewCount = video['viewCountText']['simpleText']
Use the video URL to make a request and extract the other two data points. Here also, you must extract the JSON string with RegEx.
videResponse = requests.get(videoUrl)
videoSoup = BeautifulSoup(videResponse.text)
videoScript = videoSoup.find_all('script')
reqScript=""
for script in videoScript:
if "engagementPanels" in script.text:
reqScript = script.text
groups=re.search(r"({.+})",reqScript)
jsonObject = json.loads(groups[0])
commentCount = jsonObject['contents']['twoColumnWatchNextResults']['results']['results']['contents'][2]['itemSectionRenderer']['contents'][0]['commentsEntryPointHeaderRenderer']['commentCount']['simpleText']
description =jsonObject['engagementPanels'][2]['engagementPanelSectionListRenderer']['content']['structuredDescriptionContentRenderer']['items'][1]['expandableVideoDescriptionBodyRenderer']['attributedDescriptionBodyText']['content']
You can now store all the extracted data in a dict.
parsed.append(
{
"Title": title,
"Description":description,
"Duration":videoLength,
"View Count":viewCount,
"Published On": publishedOn,
"URL": videoUrl,
"Number of Comments": commentCount,
"Channel Details":{
"Name":channelName,
"URL" : channelUrl
}
}
)
Finally, the YouTube data scraping concludes with writing the dict to a JSON file.
with open("youtube.json","w",encoding="utf-8") as f:
json.dump(parsed,f,indent=4,ensure_ascii=False)Here, is the complete code for web scraping YouTube.
from bs4 import BeautifulSoup
import re, json, requests
def YouTubeChannels():
content = requests.get("https://www.youtube.com/results?search_query=chat+gpt").text
parsed = []
soup = BeautifulSoup(content,"lxml")
scripts = soup.find_all("script")
for script in scripts:
if "videoRenderer" in script.text:
groups=re.search(r"({.+})",script.text)
jsonObject = json.loads(groups[0])
sectionList = jsonObject['contents']['twoColumnSearchResultsRenderer']['primaryContents']['sectionListRenderer']
renderers = sectionList['contents'][0]['itemSectionRenderer']['contents']
for renderer in renderers:
try:
video = renderer['videoRenderer']
videoLength = video['lengthText']['simpleText']
channelName = video['longBylineText']['runs'][0]['text']
title = video['title']['runs'][0]['text']
videoUrl = "https://youtube.com/watch?v="+video['videoId']
publishedOn = video['publishedTimeText']['simpleText']
channelUrl = "https://youtube.com"+video['shortBylineText']['runs'][0]['navigationEndpoint']['commandMetadata']['webCommandMetadata']['url']
viewCount = video['viewCountText']['simpleText']
#This section gets the comment count and detailed video descrition
videResponse = requests.get(videoUrl)
videoSoup = BeautifulSoup(videResponse.text)
videoScript = videoSoup.find_all('script')
reqScript=""
for script in videoScript:
if "engagementPanels" in script.text:
reqScript = script.text
groups=re.search(r"({.+})",reqScript)
jsonObject = json.loads(groups[0])
commentCount = jsonObject['contents']['twoColumnWatchNextResults']['results']['results']['contents'][2]['itemSectionRenderer']['contents'][0]['commentsEntryPointHeaderRenderer']['commentCount']['simpleText']
description =jsonObject['engagementPanels'][2]['engagementPanelSectionListRenderer']['content']['structuredDescriptionContentRenderer']['items'][1]['expandableVideoDescriptionBodyRenderer']['attributedDescriptionBodyText']['content']
parsed.append(
{
"Title": title,
"Description":description,
"Duration":videoLength,
"View Count":viewCount,
"Published On": publishedOn,
"URL": videoUrl,
"Number of Comments": commentCount,
"Channel Details":{
"Name":channelName,
"URL" : channelUrl
}
}
)
except Exception as e:
print(e)
continue
return parsed
if __name__ == "__main__":
parsed = YouTubeChannels()
with open("youtube.json","w",encoding="utf-8") as f:
json.dump(parsed,f,indent=4,ensure_ascii=False)Code Limitations
The code in this tutorial can perform YouTube web scraping. However, keep the following limitations in mind:
- Limited results: Because this code employs Python requests, it doesn’t get the results available after you reach the end of the page. You need to use headless browsers for that.
- No techniques to bypass anti-scraping measures: This Python script is unsuitable for large-scale web scraping. It doesn’t have code to bypass anti-scraping measures, which will become necessary in large-scale projects.
- May require code changes: YouTube may change the JSON structure. It will break the code because your scraper will fail to locate the required data.
- Comments are Not Scraped: Web scraping YouTube comments is not possible with this code. Youtube executes JavaScript and fetches comments from another URL, which requires authentication. However, you can scrape YouTube comments, but you need automated browsers.
Wrapping Up
YouTube web scraping is possible with Python requests and BeautifulSoup; you can use RegEx to extract the JSON string containing video details.
However, watch for the changes in the JSON structure. If it changes, you need to reanalyze the JSON to figure out how to extract the data.
Moreover, you need to upgrade your code if you need to scrape the details of the videos loaded after reaching the end of the page or to extract comments.
You can avoid all this coding if you choose ScrapeHero. You can also forget about bypassing anti-scraping measures in large-scale web scraping projects; we will do that for you.
ScrapeHero is an enterprise-grade web scraping service provider capable of large-scale web scraping and crawling. ScrapeHero services also include product and brand monitoring and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


