

Costco.com is a simple website; it doesn’t use much JavaScript to display products, making web scraping Costco possible with Python requests.
This tutorial shows you how to scrape Costco product details using Python requests and BeautifulSoup.
Data Scraped from Costco
In this tutorial, you scrape three product details from the Costco search results page:
- Product Name
- Price
- URL
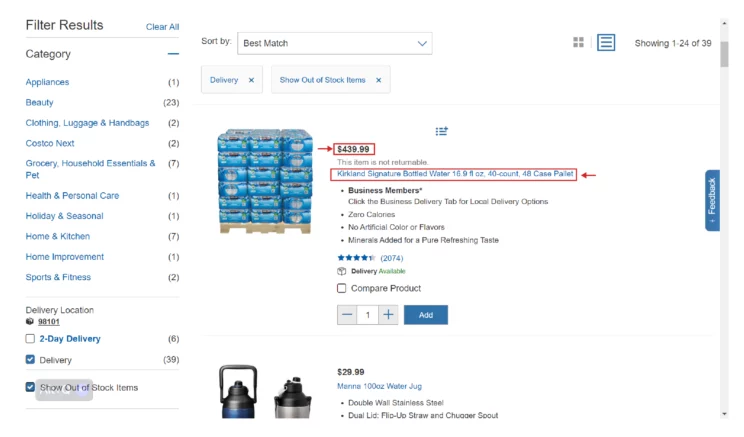
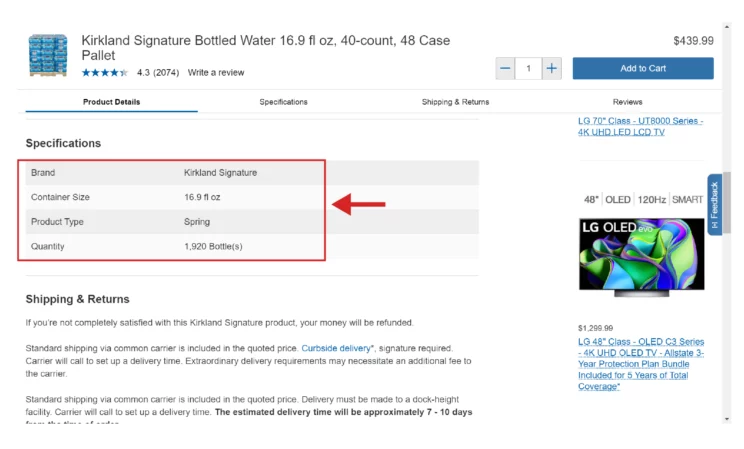
Complete product features are not available on the product results page. Therefore, you need to extract them from the product page. The extracted details depend on the product.
Web Scraping Costco: The Environment
You require two external packages for Costco data scraping:
- Python requests for managing HTTP requests
- BeautifulSoup for parsing
Install the external packages using pip.
You also require two other modules, json and re.
- The json module allows you to save the extracted details to a JSON file.
- The re module enables you to use RegEx.
They come with the Python standard library, so you don’t need to install it.
Web Scraping Costco: The Code
Begin Costco product data scraping by importing the four packages mentioned above.
import requests, re, json
from bs4 import BeautifulSoupThe code also needs to use headers that tell the server that the request originated from a user; this is necessary to bypass anti-scraping measures. Define the headers as a dict.
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
It is better to use functions to keep your code neat; this improves readability and facilitates debugging. Therefore, define four functions:
- getDetails()
- saveToJson()
- getAvailablePages()
- paginate()
getDetails()
The function accepts a BeautifulSoup object and returns Costco product details.
It is better to check if search results exist before locating product details. To do so, check if there is an ‘h1’ tag with the attribute ‘automation-id’ as ‘noResultsFound.’
if soup.find('h1',{"automation-id":"noResultsFound"}):
raise Exception("No items found")If no such tag exists, the function can begin locating the product details:
- Locate the product-list
- Locate all the products
- Extract details of individual products
Finding Product-List
The product list will be inside a ‘div’ element with the class ‘product-list grid.’ Locate it using BeautifulSoup’s find() method.
productGrid = soup.find('div',{'class':'product-list grid'})Locating All the Products
Use BeautifulSoup’s find_all() method to locate all the products separately, giving you a list.
This list will have the ‘div’ tags containing the product details.
products = productGrid.find_all('div',{'class':'product'})Extracting Details of Individual Products
Define an empty array that will hold the product details.
productDetails = []Using the re module, create a RegEx pattern to find the anchor tag containing the product link. This pattern matches the ‘automation-id’ of each product. Using RegEx is necessary as the ‘automation-id’ has a number associated with it that is different for each product.
autoId = re.compile(r"productDescriptionLink_\d")Iterate through the list, and in each iteration:
- Use the RegEx pattern mentioned above to find the required anchor tag.
link = product.find('a',{'automation-id':autoId}) - Extract
- The product link from the ‘href’ attribute of the anchor tag.
url = link['href'] - The name from the tag text.
name = link.text - The price from the text of a ‘div’ tag with the class ‘price.’
price = product.find('div',{'class':'price'}).text - The features from the product page
- The product link from the ‘href’ attribute of the anchor tag.
- Append the extracted details to an array.
productDetails.append( { "Name": name.strip(), "Price": price.strip(), "Features": featuresAsJson, "URL":url }
In the second step, extracting features from the product page requires making an HTTP request to the extracted URL.
productResponse = requests.get(url,headers=headers).textYou can then extract the features from the response:
- Pass the response text to BeautifulSoup.
productSoup = BeautifulSoup(productResponse,"lxml") - Locate the ‘div’ containing features; it will have the class ‘product-info-description.’
featuresDiv = productSoup.find('div',{'class':'product-info-description'}) - Locate an unordered list if the above ‘div’ exists; the list will contain the features.
features = featuresDiv.find('ul').text.split('\n') if featuresDiv.find('ul') else None - Iterate through the list if the features are not None. In each iteration, extract the key-value pairs and store them in a dict featuresAsJson.
if features != None: for line in features: if line !="": keyNValue = line.split(':') if len(keyNValue) == 2: featuresAsJson[keyNValue[0].strip()] = keyNValue[1].strip()
All products may not have product-info-description. However, all of them have product-info-specs.
Therefore, if the code couldn’t get product-info-description, locate the div tag with the class ‘product-info-specs,’ extract key-value pairs from each row, and store them in the dict.
if featuresAsJson == {}:
specs = productSoup.find('div',{'class':'product-info-specs'})
keyNValues = specs.find_all('div',{'class':'row'})
for keyValue in keyNValues:
divs = keyValue.find_all('div')
featuresAsJson[divs[0].text.strip()] = divs[1].text.strip()saveToJson()
This function accepts the extracted product details and saves them to a JSON file. It uses the dump() method of the json module to do so.
with open("costcoProducts.json","w") as f:
json.dump(productDetails,f,indent=4,ensure_ascii=False)getAvailablePages()
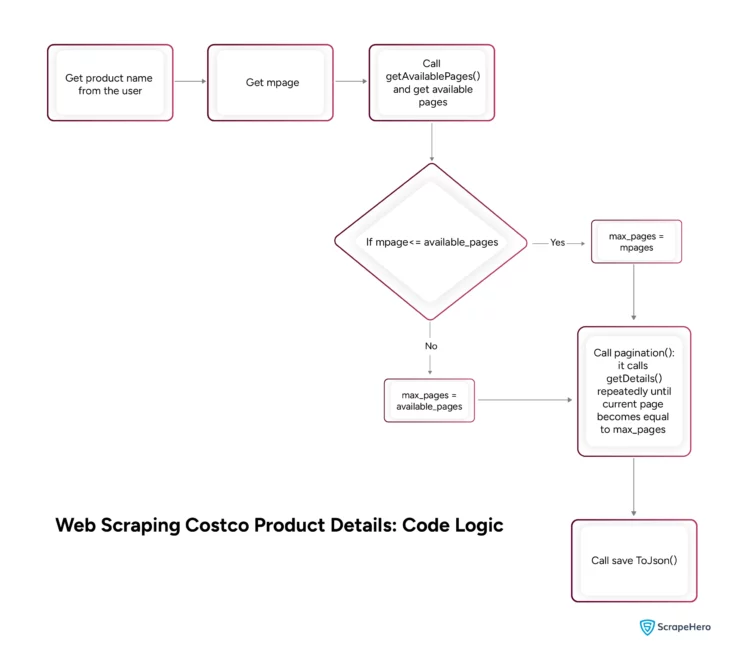
The code in this tutorial for web scraping Costco can scrape details of all the products from all the pages, but you need to know the number of available pages. This function extracts that number.
The function accepts a query and builds the URL of Costco SERP.
url = f"https://www.costco.com/CatalogSearch?dept=All&keyword={query}"It then makes an HTTP request to the URL and passes the response text to BeautifulSoup for parsing. This response will contain the homepage’s HTML code, which you can use to find the number of available pages.
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text)The pagination link that takes you to the last page gives the number of available pages. This link comes just before the link that takes you to the next page and has the class ‘forward.’
Therefore, locate the ‘li’ tag with the class ‘forward’ and get its previous sibling.
If the code can’t locate such an element, it initializes available_pages with one.
try:
availablePages = int(soup.find('li',{'class':'forward'}).previous_sibling.previous_sibling.text.strip()[0])
except:
availablePages = 1
Note: You can avoid this function, but you need to handle the error whenever the current page number exceeds the number of available pages.
paginate()
This function accepts three arguments:
- allDetails: a dict to save the extracted data from each page.
- max_pages: a variable that limits the number of pages scraped.
- query: a variable that holds the query obtained from the user input.
The paginate() function starts by initializing ‘page = 1.’ This variable stores the page the code is currently scraping.
Then, the paginate() function runs a while loop as long as ‘page’ is less than ‘max_pages.’
In each loop, the function:
- Builds a URL using ‘page’ and ‘query’
url = f"https://www.costco.com/CatalogSearch?currentPage={page}&dept=All&pageSize=24&keyword={query}" - Increments the page variable by one
page = page +1 - Makes an HTTP request to the URL and creates a BeautiufulSoup object using the response
response = requests.get(url,headers=headers) soup = BeautifulSoup(response.text) - Calls getDetails() with the object as an argument
productDetails= getDetails(soup) - Saves the extracted details, which will be a list, in the allDetails dict.
if productDetails !=[]: allDetails[f"Page {page-1}"] = productDetails
Now, you can integrate all the functions.
Start by accepting the user’s search query. For queries containing multiple words, split each word and join them using the ‘+’ sign.
product = input("What do you want to buy?")
query = "+".join(product.split())You can use this query to check for the available pages. Call getAvailablePages() with the query as the argument, which will return the number of available pages. Store it in the variable available_pages.
availablePages = getAvailablePages(query)Next, accept the maximum number of pages to scrape from the user and store it in the variable mpage.
mpage = int(input("How many pages do you want to scrape?"))You can now check if mpage is less than or equal to the available_pages.
If so, initialize a variable max_pages with mpage. Otherwise, initialize the variable with available_pages.
max_pages = mpage if mpage <= availablePages else availablePagesnbsp;Define an empty dict to store the extracted product details from each page. This way, you can store the product details from each page separately; the keys will be the page numbers, and the values will be the product details.
allDetails = {}You can now call paginate() with allDetails, max_pages, and query as arguments. The function will update the declared allDetails dict.
paginate(allDetails,max_pages,query)Finally, call the saveToJson() with allDetails as the argument to save extracted data as a JSON file.
saveToJson(allDetails)The extracted Costco product details will look like this.
"Page 1": [
{
"Name": "Kirkland Signature 10-Gallon Wastebasket Liner, Clear, 500-count",
"Price": "$13.99",
"Features": {
"Brand": "Kirkland Signature",
"Capacity": "10 Gallon",
"Quantity": "500 Bag(s)"
},
"URL": "https://www.costco.com/kirkland-signature-10-gallon-wastebasket-liner%2c-clear%2c-500-count.product.100224137.html"
},
{
"Name": "Kirkland Signature 18-Gallon Compactor & Kitchen Trash Bag, 70-count",
"Price": "$17.99",
"Features": {
"Capacity": "18 Gallon",
"Thickness": "2.0 mil",
"Dimensions": "25.625” x 28”"
},
"URL": "https://www.costco.com/kirkland-signature-18-gallon-compactor-%2526-kitchen-trash-bag%2c-70-count.product.4000234602.html"
},
{
"Name": "Kirkland Signature Flex-Tech 13-Gallon Kitchen Trash Bag, 200-count",
"Price": "$19.99",
"Features": {
"Brand": "Kirkland Signature",
"Capacity": "13 Gallon",
"Quantity": "200 Bag(s)"
},
"URL": "https://www.costco.com/kirkland-signature-flex-tech-13-gallon-kitchen-trash-bag%2c-200-count.product.4000101524.html"
},
And here is the complete code for web scraping Costco product details.
import requests, re, json
from bs4 import BeautifulSoup
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
def getDetails(soup):
if soup.find('h1',{"automation-id":"noResultsFound"}):
raise Exception("No items found")
productGrid = soup.find('div',{'class':'product-list grid'})
products = productGrid.find_all('div',{'class':'product'})
productDetails = []
autoId = re.compile(r"productDescriptionLink_\d")
for product in products:
try:
link = product.find('a',{'automation-id':autoId})
url = link['href']
print(url)
name = link.text
price = product.find('div',{'class':'price'}).text
productResponse = requests.get(url,headers=headers).text
productSoup = BeautifulSoup(productResponse,"lxml")
featuresDiv = productSoup.find('div',{'class':'product-info-description'})
features = featuresDiv.find('ul').text.split('\n') if featuresDiv.find('ul') else None
featuresAsJson = {}
if features != None:
for line in features:
if line !="":
keyNValue = line.split(':')
if len(keyNValue) == 2:
featuresAsJson[keyNValue[0].strip()] = keyNValue[1].strip()
if featuresAsJson == {}:
specs = productSoup.find('div',{'class':'product-info-specs'})
keyNValues = specs.find_all('div',{'class':'row'})
for keyValue in keyNValues:
divs = keyValue.find_all('div')
featuresAsJson[divs[0].text.strip()] = divs[1].text.strip()
productDetails.append(
{
"Name": name.strip(),
"Price": price.strip(),
"Features": featuresAsJson,
"URL":url
}
)
except Exception as e:
print(e)
continue
return productDetails
def saveToJson(productDetails):
with open("costcoProducts.json","w") as f:
json.dump(productDetails,f,indent=4,ensure_ascii=False)
def getAvailablePages(query):
url = f"https://www.costco.com/CatalogSearch?dept=All&keyword={query}"
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text)
try:
availablePages = int(soup.find('li',{'class':'forward'}).previous_sibling.previous_sibling.text.strip()[0])
except:
availablePages = 1
return availablePages
def paginate(allDetails,max_pages,query):
page=1
while page <= max_pages:
print(page)
url = f"https://www.costco.com/CatalogSearch?currentPage={page}&dept=All&pageSize=24&keyword={query}"
print(url)
page = page +1
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text)
try:
productDetails= getDetails(soup)
except Exception as e:
print(e)
continue
if productDetails !=[]:
allDetails[f"Page {page-1}"] = productDetails
if __name__ == "__main__":
product = input("What do you want to buy?")
query = "+".join(product.split())
availablePages = getAvailablePages(query)
mpage = int(input("How many pages do you want to scrape?"))
max_pages = mpage if mpage <= availablePages else availablePages
allDetails = {}
paginate(allDetails,max_pages,query)
saveToJson(allDetails)Code Limitations
The code in this tutorial can scrape product details from Costco SERP. However, keep the following limitations in mind:
- The code lacks techniques to bypass anti-scraping measures; hence, it is not suitable for large-scale web scraping.
- Costco may change its website structure, and the code may fail to locate the product details.
- Some search queries on Costco redirect to specific pages, making it necessary to add additional code.
Wrapping Up
You can scrape Costco product details using Python requests and BeautifulSoup. The process involves making HTTP requests, parsing, and locating the HTML tags holding the required data.
However, the code in this tutorial has some limitations; you need to alter it for large-scale web scraping or when Costco changes its website structure.
If you don’t want to alter the code yourself or want to scrape at a large scale, contact ScrapeHero now.
ScrapeHero is a full-service web scraping service provider. We can build you enterprise-grade web scrapers and crawlers according to your specifications. ScrapeHero services also include monitoring and custom RPA services.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



