

Netflix is a dynamic website, with most of its dynamic content only appearing after you log in. However, web scraping Netflix focuses on public pages that are not dynamic. This makes it possible to scrape data from Netflix using HTTP requests; this tutorial will guide you through the process.
The tutorial shows you how to scrape Netflix data with Python using two libraries: Python requests and BeautifulSoup.
Note: This article covers scraping movie details, not the movies themselves. Extracting movies from Netflix without permission is illegal as it violates copyright laws.
Data Scraped from Netflix
This tutorial will help you extract details of movies and series. Initially, it extracts the links to movies and series from these URLs:
- For series: https://www.netflix.com/us/browse/genre/83
- For movies: https://www.netflix.com/us/browse/genre/34399
You can use F12 to inspect the webpage to identify the tags containing the links to movies/series.
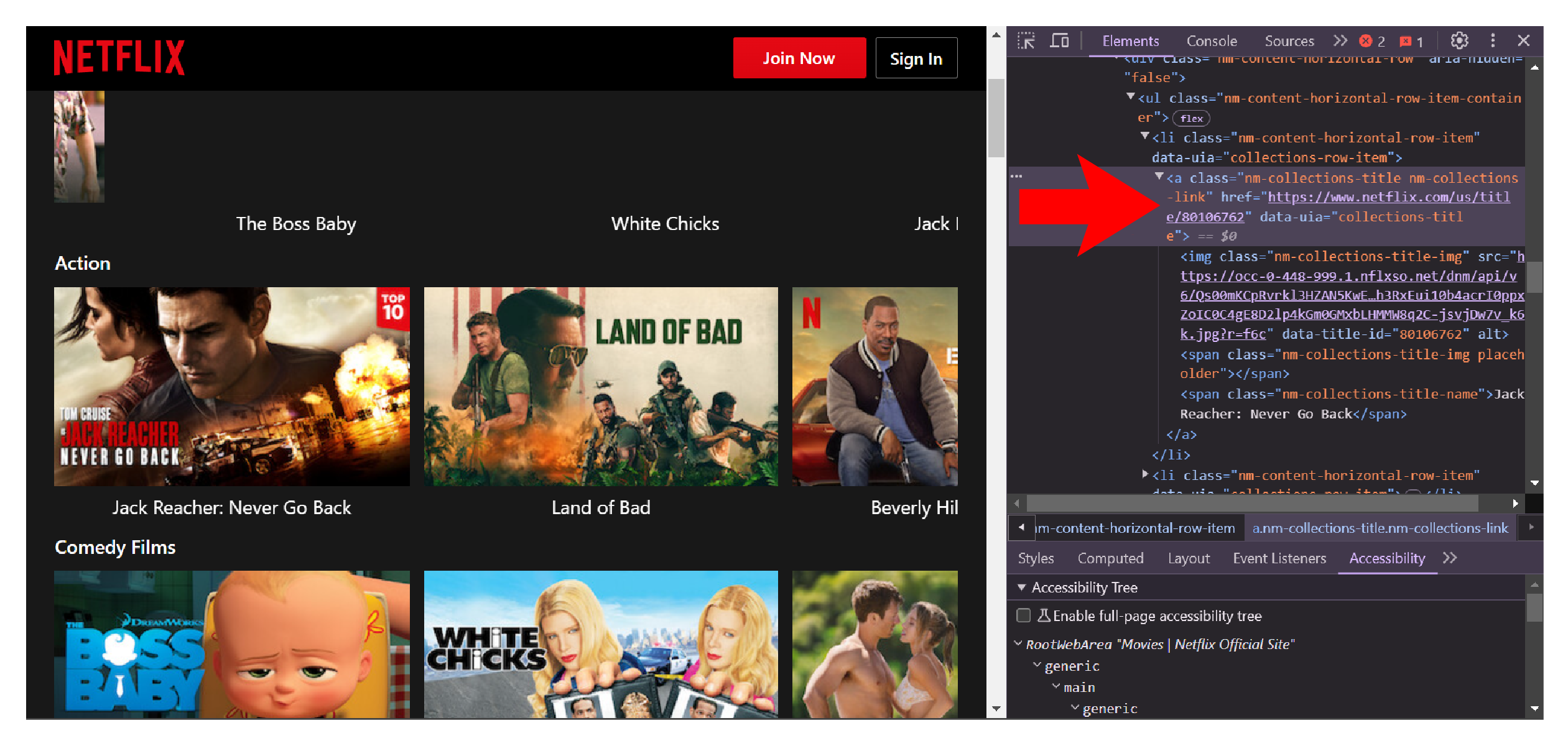
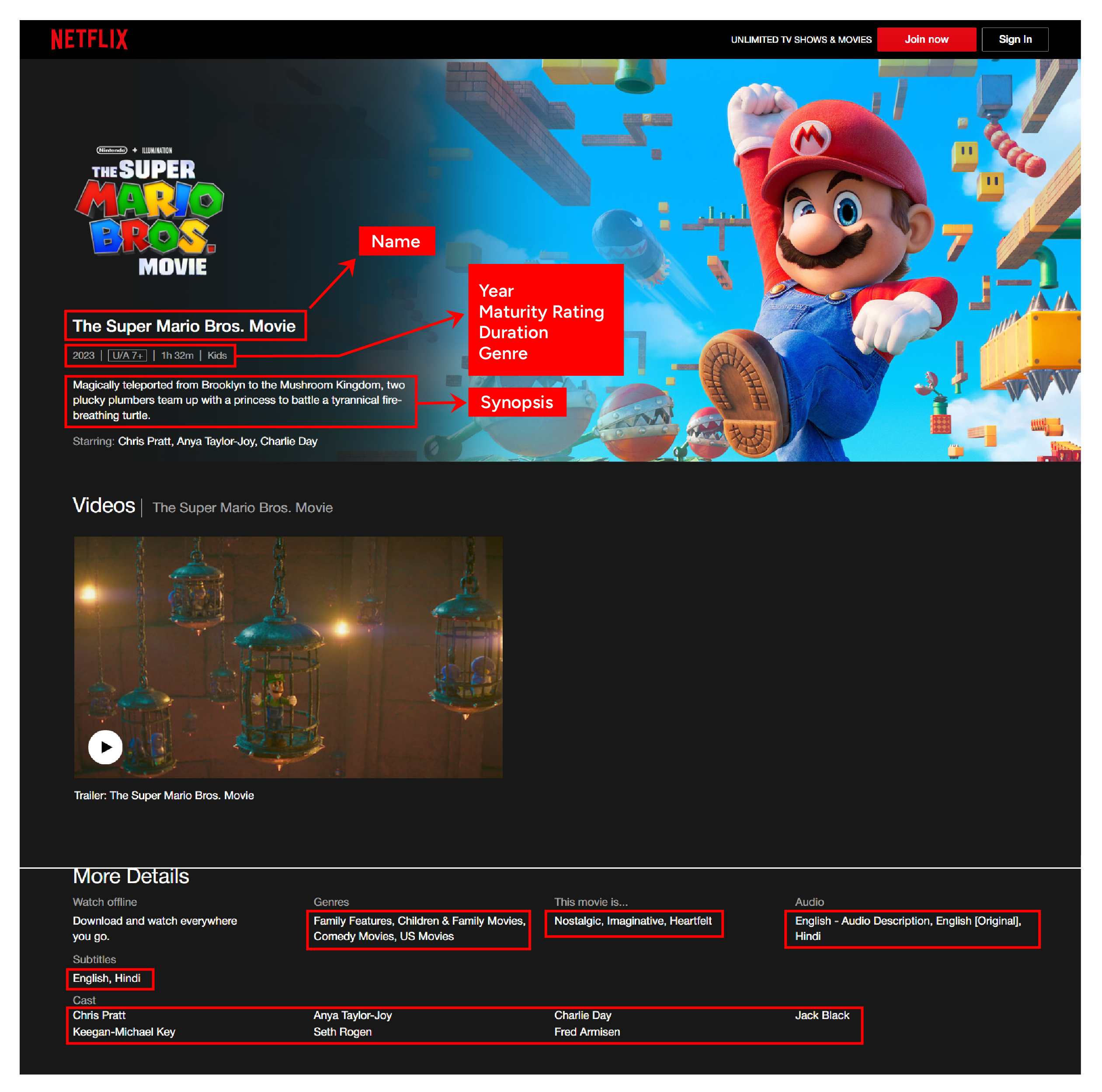
Once the code extracts the URLs, it extracts specific details from each one. Here is what it collects:
- Name
- Genre
- Synopsis
- Related Genres
- Audio
- Subtitles
- Release Date
- Rating
- Mood
- Duration/Seasons
- Cast
- URL
Web Scraping Netflix: The Environment
This code requires two external packages, which you need to install:
Python requests fetches the HTML source code of the target web page. Meanwhile, BeautifulSoup helps you parse and extract the required data.
You can install these packages using the Python package manager pip.
pip install bs4 requestsAdditionally, the code also uses the json module to save the extracted data to a JSON file.
Web Scraping Netflix: The Code
Start the code for web scraping Netflix by importing the necessary packages.
import requests
import json
from bs4 import BeautifulSoup
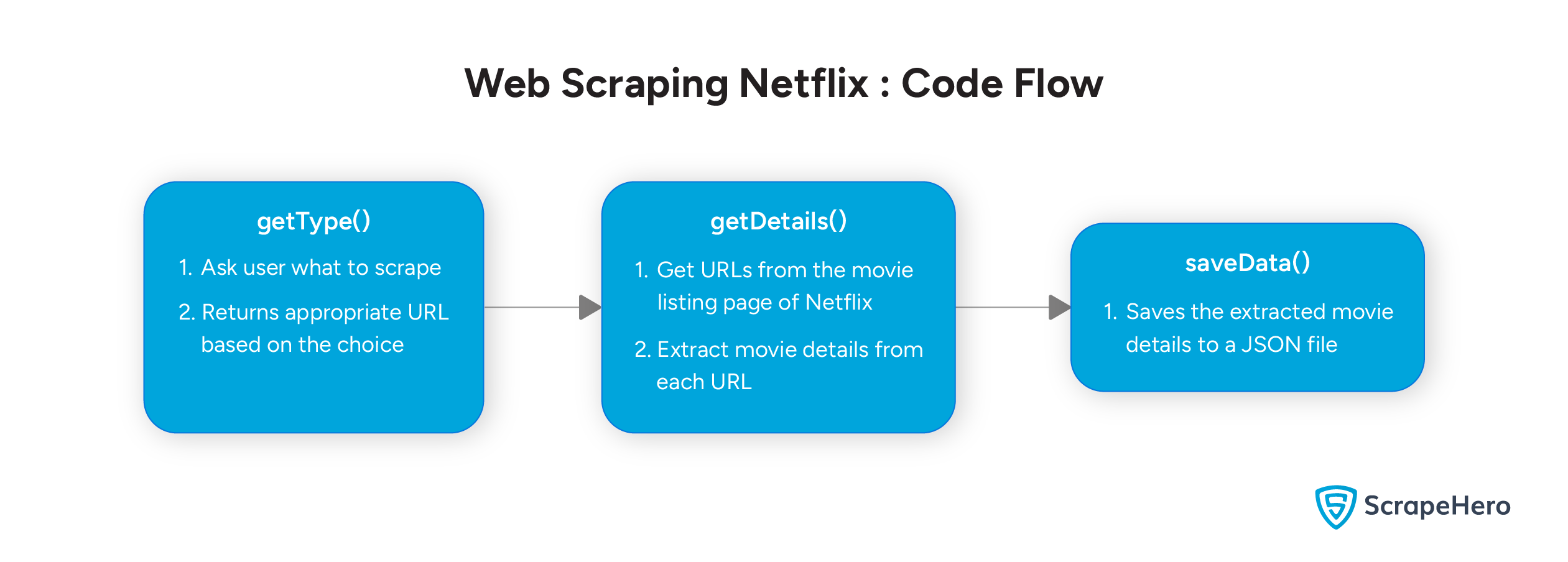
The code can scrape both series and movie details, but it doesn’t do both at the same time. Users will see a prompt asking whether they want to scrape series or movies.
The input function allows you to display such a prompt.
searchType = input("Enter \n1) for series\n2) for movies")Based on the user’s choice, the function picks the correct URL from the dict variable.
selector = {
"1": series_url,
"2": movies_url
}
try:
url = selectvor[searchType]
except:
print("Wrong entry. Enter either 1 or 2.")
getType()
The try-except block prevents errors if you enter an invalid character. In that case, the function notifies you and calls itself again, making getType() a recursive function.
Once you have the correct URL, you can start extracting the data.
Create a function getDetails() that accepts a URL as input and scrapes the details of the movies/series available on that page. Begin by sending an HTTP request to the URL using Python requests.
response = requests.get(url)Next, parse the response, but only if the status code is 200.
if response.status_code == 200:
soup = BeautifulSoup(response.text,'lxml')
else:
return {"Error":"Server blocked your scraper or the URL is not correct."}
Netflix organizes movies in various sections, so it’s easier to extract each section separately.
You can select the sections using the find_all method of BeautifulSoup.
sections = soup.find_all('section',{'class':'nm-collections-row'})Loop through the sections and extract the details. Before the loop, define an empty dict all_sections to store the extracted details.
all_sections = {}While looping, use try-except blocks to avoid errors.
Start by extracting the section name. This is a bit tricky as some sections use the span tag while others use the h2 tag.
So, use an extra try-except block to handle both cases.
try:
section_name = section.find('span',{'class':'nm-collections-row-name'}).text
except:
section_name = section.find('h2',{'class':'nm-collections-row-name'}).textNext, find the URLs that lead to the movies/series pages.
movie_urls = [item.a['href'] for item in section.ul.find_all('li')]Now, loop through the URLs to extract movie details. Store the extracted information in an empty dict all_details.
Inside the loop, the function will:
- Send an HTTP request to each URL using Python requests
movie_response = requests.get(url) - Parse the response using BeautifulSoup
movie_soup = BeautifulSoup(movie_response.text,'lxml') - Extract the required data using the find or find_all method of BeautifulSoup:
- Audio from a span tag with the class ‘item-audio’
audio = movie_soup.find('span',{'class':'item-audio'}) - Subtitles from span tags with the class ‘item-subtitle’
subtitles = movie_soup.find_all('span',{'class':'item-subtitle'}) - Synopsis from a div tag with the class ‘title-info-synopsis’
synopsis = movie_soup.find('div',{'class':'title-info-synopsis'}) - Date from a span tag with the attribute data-uia ‘item-year’
date = movie_soup.find('span',{'data-uia':'item-year'}) - Rating from a span tag with the class ‘maturity-number’
rating = movie_soup.find('span',{'class':'maturity-number'}) - Moods from span tags with the class ‘item-mood-tag’
moods = movie_soup.find_all('span',{'class':'item-mood-tag'}) - Duration/Seasons from a span tag with the class ‘duration’
duration = movie_soup.find('span',{'class':'duration'}) - Cast from span tags with the class ‘item-cast’
cast = movie_soup.find_all('span',{'class':'item-cast'}) - Genre from a span tag with the class ‘item-genre’
genre = movie_soup.find('a',{'data-uia':'item-genre'}) - Related genres from span tags with the class ‘item-genres’
related_genres = movie_soup.find_all('a',{'class':'item-genres'})
- Audio from a span tag with the class ‘item-audio’
- Add the extracted details to the dict all details with the movie name as the key.
all_details[movie_soup.h1.text] = {
"Genre":genre.text if genre else "Unknown",
"Synopsis":synopsis.text if synopsis else "Unknown",
"Related Genres": [sub_genre.text for sub_genre in related_genres] if related_genres else "Unknown",
"Audio":audio.text if audio else "Unknown",
"Subtitles":[subtitle.text for subtitle in subtitles] if subtitles else "Unknown",
"Release Date":date.text if date else "Unknown",
"Rating":rating.text if rating else "Unknown",
"Mood":[mood.text for mood in moods] if moods else "Unknown",
"Duration/Seasons":duration.text if duration else "Unknown",
"Cast":[item.text for item in cast] if cast else "Unknown",
"URL":url
}And outside the loop, add the extracted details of all the movies/series in a section to the dict all_sections. Use the section name as the key.
all_sections[section_name] = all_detailsFinally, this function returns the dict all_sections.
return all_sectionsAfter extracting data, it’s time to save it. The saveData() function does this for you. It accepts the extracted data as the argument and uses the json.dump() method to save it to a JSON file.
def saveData(data):
with open("netflix.json","w",encoding="utf-8") as f:
json.dump(data,f,indent=4,ensure_ascii=False)Now, put it all together:
- Define variables holding the URLs for listing pages of movies and series.
series_url = "https://www.netflix.com/in/browse/genre/83" movies_url = "https://www.netflix.com/in/browse/genre/34399" - Call getType() to get the URL based on the user’s input
url = getType() - Call getDetails() with the URL as the argument to retrieve movie details.
movieDetails = getDetails(url) - Call saveData() to save the extracted data.
saveData(movieDetails)
Code Limitations
You can use this code to make your own Netflix scraper. But there are some limitations to keep in mind:
- HTML Structure Changes: The code relies on Netflix.com’s current HTML structure to find data. If Netflix changes the structure, the scraper might break. You’ll then need to update the code to adapt to the changes.
- Anti-Scraping Measures: This code isn’t built to scrape without getting blocked. It lacks techniques to bypass anti-scraping measures, which could be a problem if you send too many requests. Netflix may block your IP; this also makes it unsuitable for large-scale web scraping.
Wrapping Up: Why Use a Web Scraping Service?
You saw how to scrape Netflix using Python requests and BeautifulSoup. These tools allow you to fetch HTML source code and extract details of movies and series.
However, the limitations mentioned, like the need to handle anti-scraping measures and continuous monitoring, can make web scraping Netflix challenging. So, if you only need data, why not avoid the hassle by using a web scraping service like ScrapeHero?
ScrapeHero is a full-service web scraping service provider. we can build enterprise-grade web scrapers according to your specifications. This will let you focus on using the data rather than worrying about technical details.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



