

The quality of analysis increases with the size of the available data, but large datasets suffer from two problems. First, they need a large amount of RAM, and second, the analysis itself becomes slow. You can overcome these challenges by performing data analysis using Dask.
Dask solves the above-mentioned problems using two methods: chunking and parallelism.
Chunking refers to breaking down large datasets into several smaller datasets. Dask can then limit the number of chunks loaded according to the available RAM, which avoids overloading RAM.
Parallelism increases the processing speed by processing chunks simultaneously. Dask can implement parallelism using multiple cores in a single system and using multiple systems in a cluster.
This article discusses how to use Dask for data analysis.
Data Analysis Using Dask: Installation
To begin using Dask for data analysis, you need to install it along with its dependencies. You can do this using pip:
pip install 'dask[complete]'Once installed, you can start using Dask in your Python scripts or Jupyter notebooks.
Data Analysis Using Dask Collections
Dask has high-level abstractions called Dask Collections to facilitate parallelism. These collections allow you to use familiar methods of popular libraries for data manipulation while implementing parallelism in the background. There are four core collections in Dask:
- Arrays
- Bags
- DataFrames
- Delayed
1. Arrays
Dask arrays are parallel versions of numpy. With Dask arrays, you can use the familiar numpy syntax to create and manipulate data.
You can create a random Dask array using the random() method.
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))The above code creates a random Dask array of 10000×10000 size. The argument chunks specify the size of the chunk, meaning there are 100 chunks in this case (10000/1000 X 10000/1000), and each chunk is a numpy array.
Now, you can use numpy syntax to manipulate the array. For example,
- To calculate mean, use
mean = x.mean()- To calculate sum, use
sum = x.sum()However, the above code snippets only create a task graph that tells the actions to perform. You need to use the compute() method to get the results of the computation.
result_mean = mean.compute()
result_sum = sum.compute()2. Bags
Dask bags enable you to manipulate unstructured or semi-structured data like JSON files, text data, etc.
You can create a Dask bag from a Python iterable. Use the from_sequence() method for that.
import dask.bag as db
daskBag = db.from_sequence([1,2,4,5,5,5])To read text data, you can use the read_text method
bag = db.read_text('data.txt')The read_text() method will load each line of the text document as a separate element of an array, which is convenient for text analysis. You can verify this by calling the compute() method.
bag.compute()You can also read a line-delimited JSON file using the read_text() method by calling the map() method with json. loads as the argument.
file = b.read_text('file.jsonl').map(json.loads)Once you load the file, you can perform various operations on it. Some of the command operations are
1. Filtering Data: Use the filter() method to filter those records containing a particular key-value pair.
filtered = file.filter(lambda x: x[‘key’]===’value’)2. Mapping: Use the map() method to select all the values of a particular key from every record.
mapped file.map(lambda x: x[‘key’])3. Counting: Counting the total number records.
filtered.count().compute()
mapped.count().compute()Similar to Dask Arrays, you need to use the compute() method to get the results in each case.
After performing all the required operations, you can save the transformed data using the to_textfiles() method.
filtered.map(json.dumps).to_textfiles()You had to map the json.dumps() method to convert the data to a JSON string before saving to a file.
3. DataFrames
Dask DataFrames are essentially parallelized versions of Pandas, operating with Pandas under the hood. You can use the same methods as in Pandas for most tasks, including reading files.
Dask supports various file formats for loading data, including CSV, Parquet, and SQL databases. Here’s how to load a CSV file into a Dask DataFrame:
import dask.dataframe as dd
# Load a CSV file
df = dd.read_csv('large_dataset.csv')You can also load several CSV files at once using the read_csv() method of dask.dataframe. Use ‘*’ as the wildcard while reading similar files. For instance, to read all the files named ‘file1.csv’, ‘file2.csv’, etc., use ‘file*.csv’ as the argument for read_csv().
df = dd.read_csv(‘file*.csv’)This operation will read all the CSV files and load them as a single DataFrame.
Apart from CSV files, Dask also supports these formats:
- Parquet: A columnar storage format optimized for analytics.
- JSON: Useful for hierarchical data
- Excel: For spreadsheet data.
- SQL Databases: Connect directly to databases like PostgreSQL or MySQL.
Once you load the file, you can perform various operations on a Dask DataFrame. Here are some common tasks:
- Filtering Data: You can filter rows based on specific conditions.
filtered_df = df[df['column_name'] > value]- Grouping Data: Grouping data and calculating aggregates is straightforward.
grouped_df = df.groupby('group_column').mean()
result = grouped_df.compute() # Trigger computation- Descriptive Statistics: Dask provides methods for generating summary statistics.
stats = df.describe().compute()4. Delayed
Sometimes you may want to perform operations on a dataset not available in Arrays, Bags, or DataFrames. In such situations, you can use Dask delayed. It allows you to parallelize any parallelizable.
Consider this Python code that doesn’t use delayed.
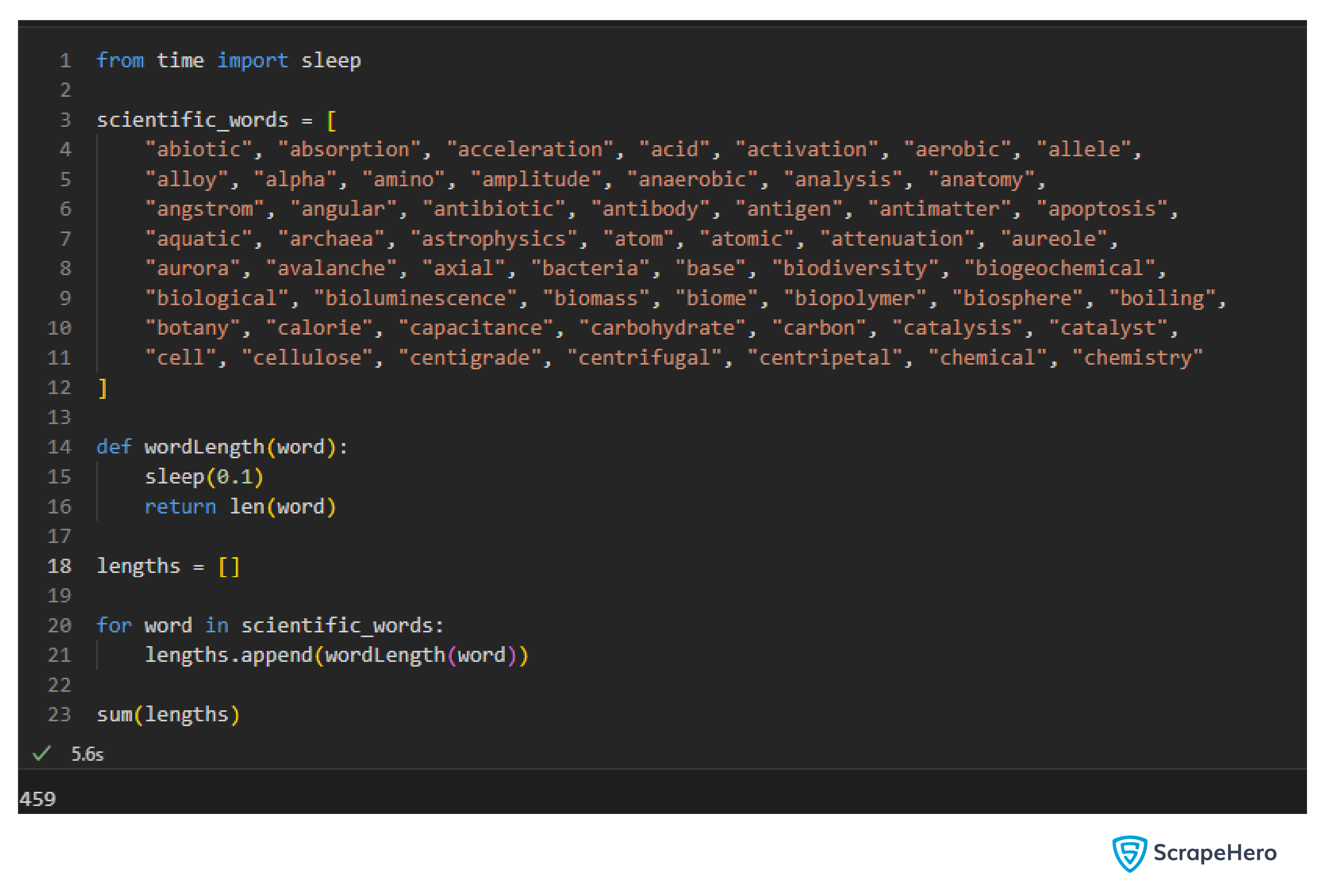
This code took 5.6s to complete.
You can parallelize this code, as calculating the length of each word is an independent task.
To parallelize this code, add the ‘@dask.delayed’ decorator just above the function wordLength(). Then use the dask.delayed() method to call sum().
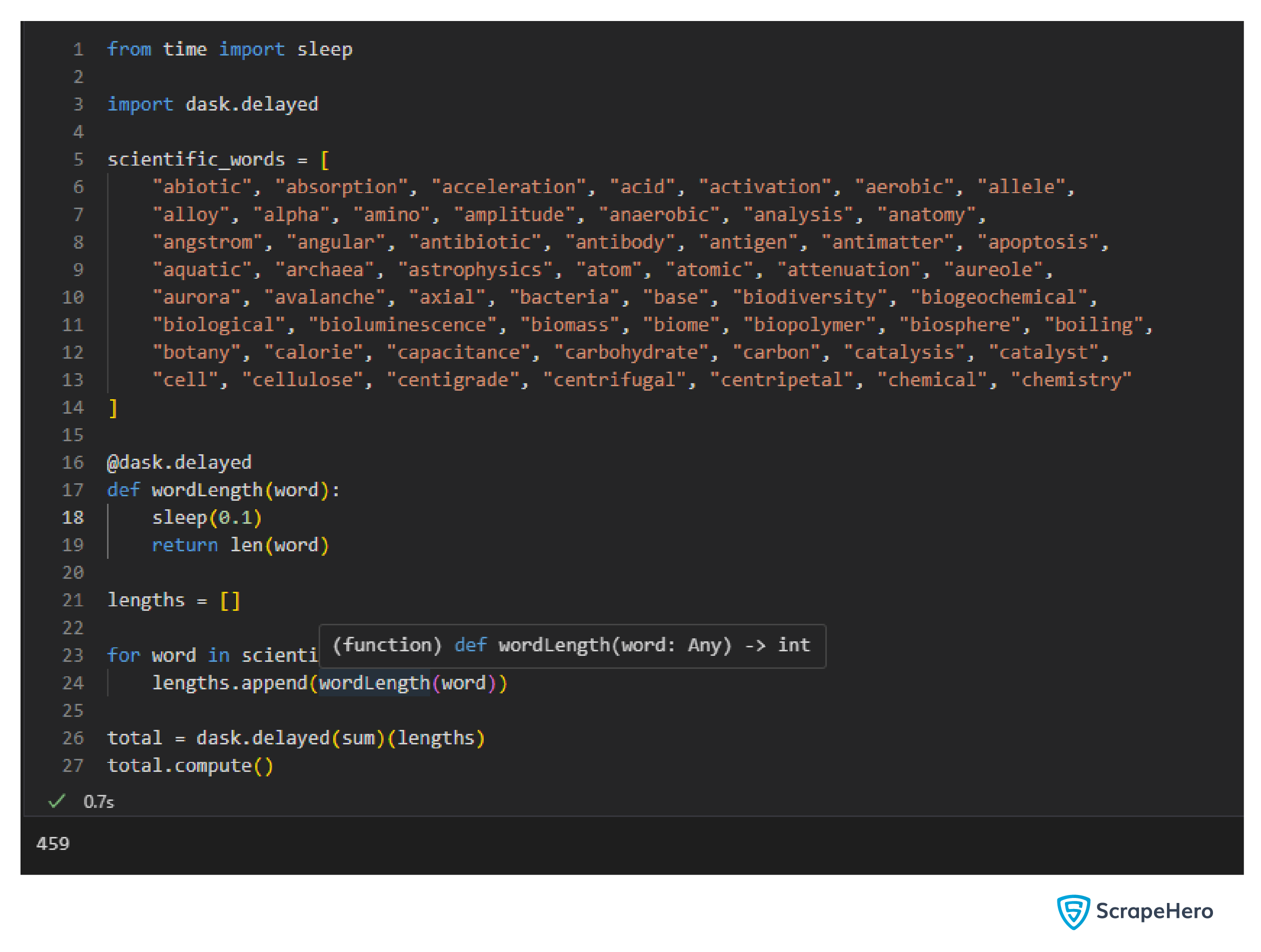
After using dask.delayed, the code execution time was reduced to 0.7s, which is an 87.5% reduction.
Need data to test Dask? Use ScrapeHero Cloud. Its no-code web scrapers can retrieve data from various sources, including e-commerce and real-estate websites.
Advanced Capabilities of Dask
Dask is a powerful parallel computing library that extends beyond its core functionalities of arrays, data frames, bags, and delayed computations.
Here are some advanced features you need to consider while performing data analysis using Dask:
- Distributed Workloads: Dask allows you to distribute your data analysis workloads among several systems in a cluster using the dask.distributed module.
- Dashboard: You can start a Dask dashboard to visualize the operations performed.
from dask.distributed import Client, progress
client = Client(processes=False, threads_per_worker=4,
n_workers=1, memory_limit='2GB')
client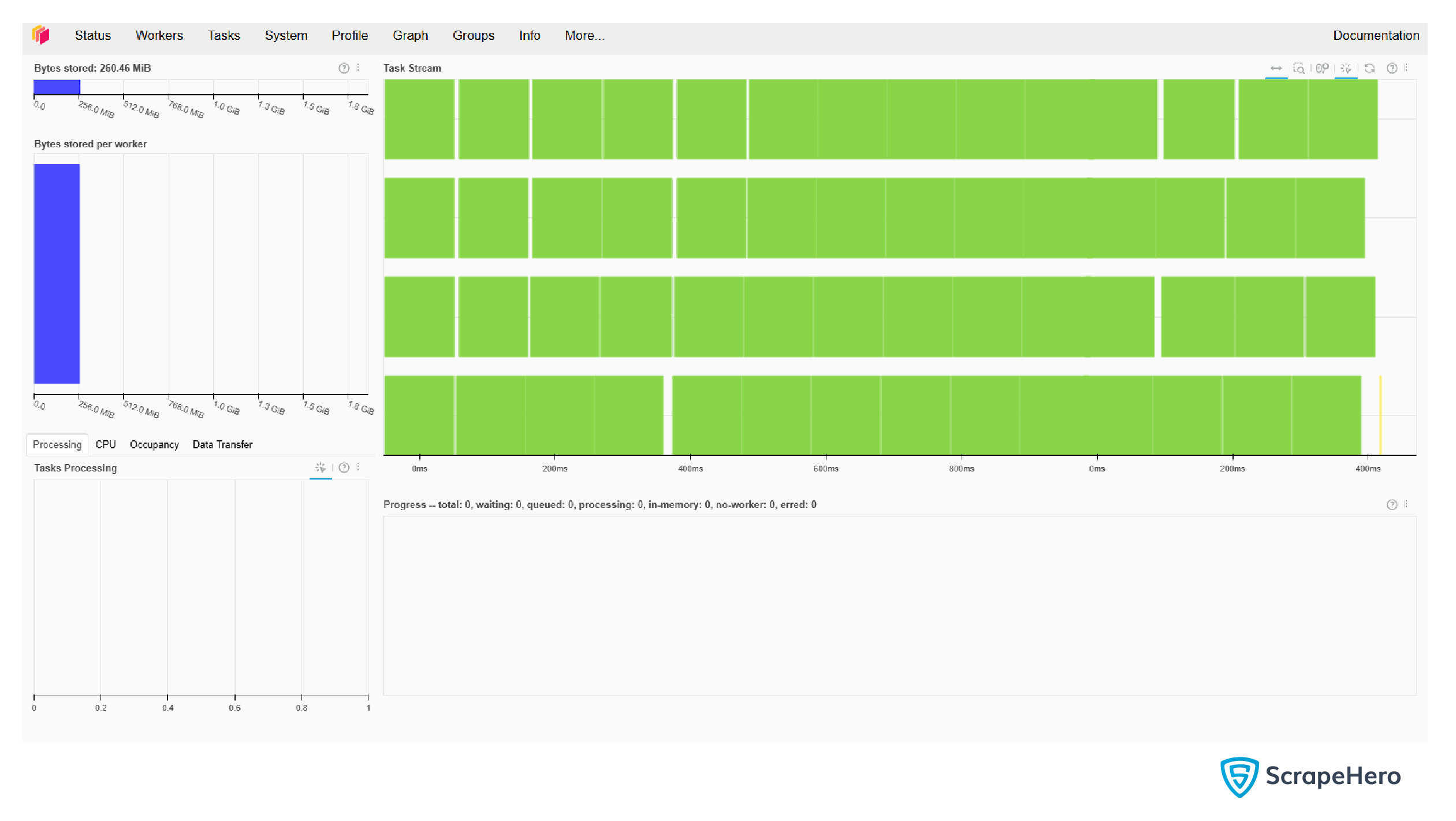
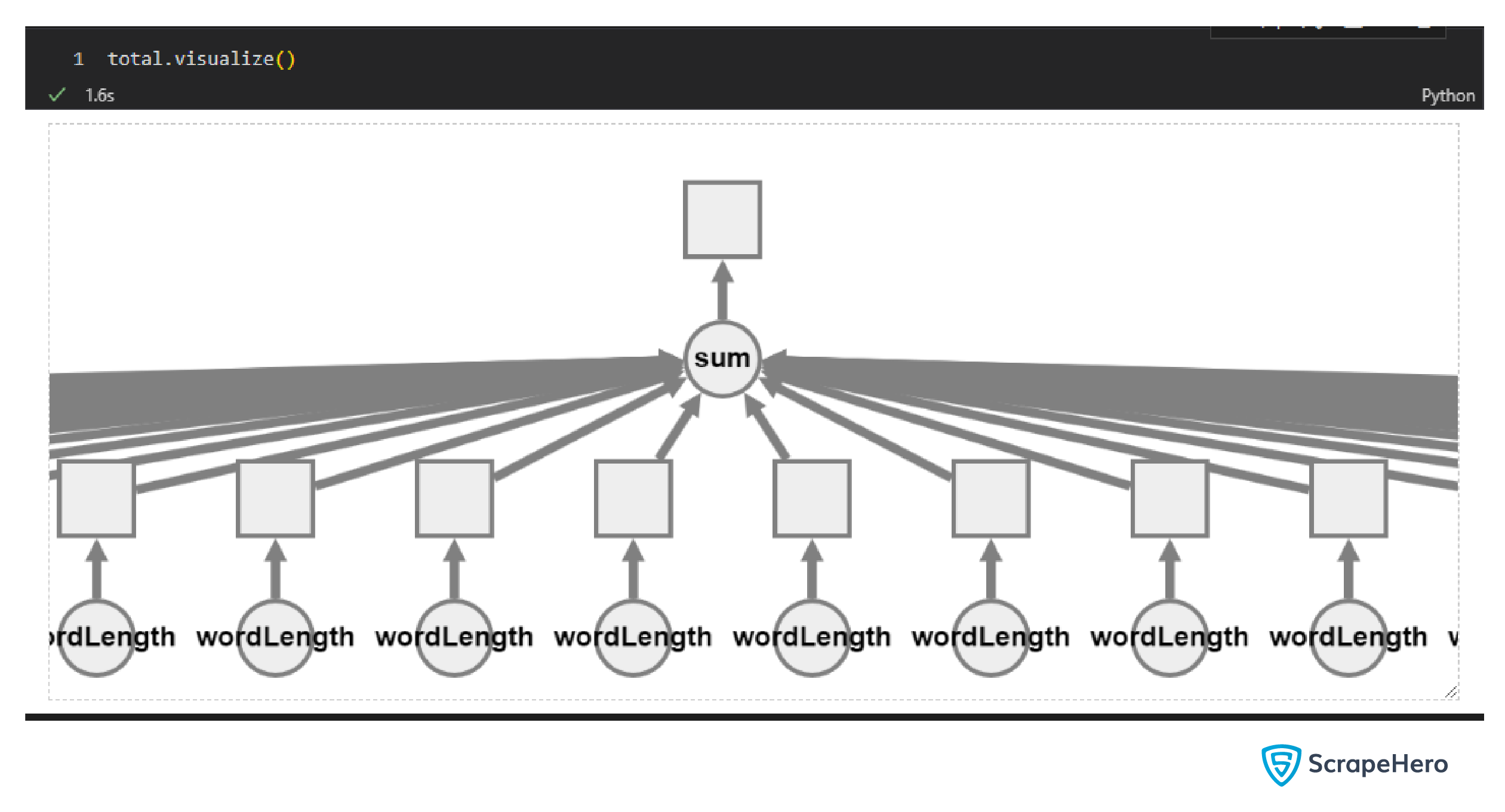
- Task Visualization: You can visualize the tasks after creating a Dask delayed object. For example, consider the above example where you find the length of words. You can visualize the delayed object ‘total’ using the visualize method.
- Machine Learning: Dask can help you parallelize machine learning workloads. The dask_ml library has methods that can handle larger-than-memory datasets. Moreover, the methods mimic familiar machine learning libraries, including scikit-learn.
Real-World Applications of Dask
Many organizations leverage Dask for various applications across different industries:
- Finance: Dask can help analyze the cash flow generated by lenders and predict the profitability of various customer segments.
- Telecom: Implementing a new mobile networking technology is expensive. Therefore, you first need to simulate mobile networks at the scale of a city and test it, which requires immense computing power. Distributed computing provided by Dask can significantly reduce the time needed for such modeling.
- Healthcare: Dask’s parallel processing capabilities can speed up the analysis and prediction of the healthcare system’s needs. For instance, predicting future patient volume in a region allows hospitals to have sufficient healthcare supplies.
Best Practices When Using Dask
To maximize the benefits of using Dask for your data analysis tasks, consider the following best practices:
- Chunk Your Data Wisely: When working with large datasets, ensure that you chunk your data appropriately so that each partition fits into memory without causing performance bottlenecks.
- Use .persist() Method: If you plan to use the same dataset multiple times during your analysis, consider persisting it in memory using the .persist() method. This avoids recomputing the same results multiple times.
df_persisted = df.persist()- Monitor Resource Usage: Utilize tools like the Dask dashboard to monitor resource usage and optimize performance dynamically.
How Can a Web Scraping Service Help You?
In conclusion, Dask provides familiar methods to parallelize your code, making it an invaluable tool for data analysis. Its collections, including Dask DataFrame and Dask Delayed, significantly speed up data analysis workflows.
However, you still need data, and ScrapeHero web scraping service can help you with that.
ScrapeHero is a fully managed web scraping service provider capable of building high-quality scrapers and crawlers. By leaving the data collection part to us, you can fully concentrate on data analysis.
Frequently Asked Questions (FAQs)
Dask is specifically designed to handle larger-than-memory datasets efficiently through parallel computing and lazy evaluation.
Yes! Dask’s API is similar to that of Pandas, allowing you to integrate it into your existing workflows with minimal changes.
Dask supports various formats, including CSV, Parquet, JSON, Excel files, and SQL databases.
Lazy evaluation means that Dask builds a task graph representing the operations but only executes them when you call .compute(), optimizing performance by avoiding unnecessary calculations.
Dask is open-source and free to use; however, if you opt for cloud-based solutions or clusters for distributed computing, there may be associated costs.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



