

Amazon Fresh is an online grocery store. Its fast delivery time has made it one of the best and highly popular. So what better way to find online grocery market data than to scrape Amazon Fresh?
Here’s how to perform Amazon grocery data scraping for product prices and reviews.
Data Scraped From Amazon Fresh
Web scraping Amazon Fresh starts with deciding what data to pull. While you can extract all kinds of data, this tutorial gets the following data points from Amazon Fresh’s deals page:
- Name: Name of the product displayed on the deal
- Price to Pay: The discounted price you need to pay
- Price Per Unit: The price of each unit, which could be per piece, pound, liter, etc.
- Link: URL of the product page.
- Reviews: These would include the reviewer’s name, review title, text, review date, and rating of top reviews on the product page.
After you have decided what to grab from Amazon Fresh’s website, analyze its page to figure out the XPaths—they tell your HTML parser where the data points are.
You can use your browser’s inspect feature to analyze the HTML and figure out XPaths. For reference, here are the XPaths used in this tutorial to scrape Amazon Fresh:
- Price to Pay: .//div[contains(@class,”priceToPay”)]//text()
- Price per Unit: .//span[contains(@class,”pricePerUnit”)]//text()
- Link: .//a/@href
- Name: .//a//text()
- Review Elements: ‘//div[contains(@id,”customer_review-“)]
- Review Title: .//h5/a/span[not(@*)]/text()
- Rating: .//i/span/text()
- Date: .//span[contains(@data-hook,”review-date”)]/text()
- Author: .//span[contains(@class,”a-profile-name”)]/text()
- Text: .//div[@data-hook=”review-collapsed”]/span/text()
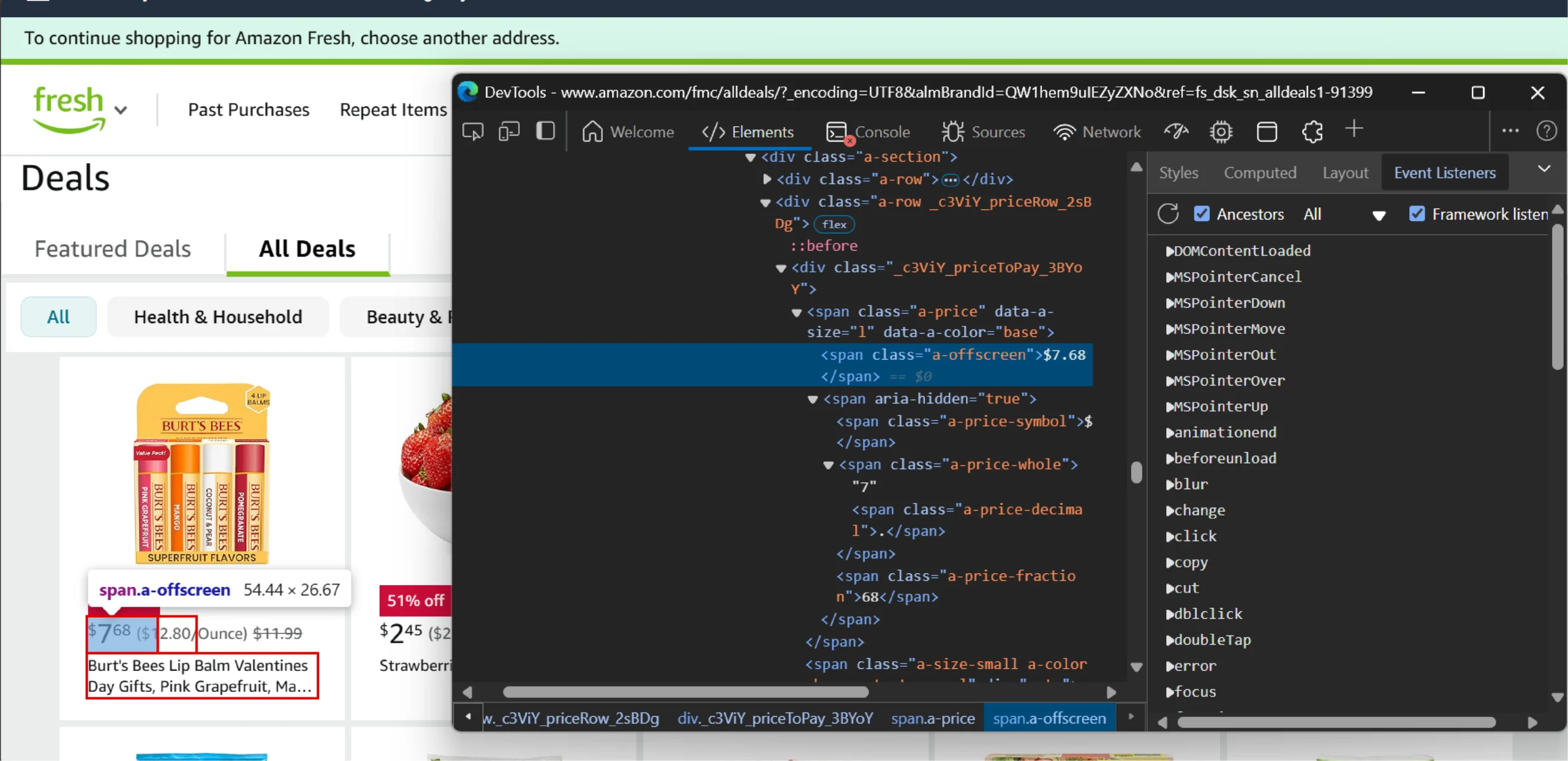
Want to learn how these XPaths work? Read this XPath cheat sheet.
Packages Required
This tutorial uses six packages to scrape Amazon Fresh:
- requests: Makes HTTP requests to get web page content
- dateparser: Parses various date formats into a standardized format
- json: Handles JSON data operations
- lxml: Parses HTML content and enables XPath queries
- selenium: Automates browser interactions
- time.sleep: Adds delays to prevent overwhelming the server
Except Selenium, lxml, and dateparser, all the other packages come with the Python standard library. You can install these external packages using pip:
pip install selenium dateparser lxmlCode to Scrape Amazon Fresh
Begin by importing the necessary packages.
import requests, dateparser, json
from lxml import html
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleepFor convenience, the above code imports webdriver and By separately from Selenium:
- The webdriver module provides methods to control the browser
- The By class has methods to specify the type of selectors
Next, define three key functions:
- scrape()
- get_deals()
- save_to_json()
scrape()
The scrape() function handles collecting review data. It starts by defining headers to use while sending requests.
def scrape(link):
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36..."
}The headers are crucial as they make our requests appear more like a regular browser. The user-agent string, in particular, helps prevent the request from being blocked.
The function then defines XPath expressions to locate specific elements:
XPATH_REVIEWS = '//div[contains(@id,"customer_review-")]'
XPATH_TITLE = './/h5/a/span[not(@*)]/text()'
XPATH_RATING = './/i/span/text()'
# similarly for other XPaths mentioned aboveThe review extraction process works by:
1. Making a request to the product page
source = requests.get(link,headers=headers)2. Parsing the HTML content
parser = html.fromstring(source.text)3. Finding all review elements
reviews = parser.xpath(XPATH_REVIEWS)4. Extracting specific data (author, rating, title, date, text) from each review.
all_reviews = []
for review in reviews:
raw_review_author = review.xpath(XPATH_AUTHOR)
raw_review_rating = review.xpath(XPATH_RATING)
raw_review_header = review.xpath(XPATH_TITLE)
raw_review_posted_date = review.xpath(XPATH_DATE)
raw_review_text = review.xpath(XPATH_REVIEW_TEXT)
review_author = ''.join(raw_review_author)
review_rating = ''.join(raw_review_rating).replace(' out of 5 stars','')
review_header = ''.join(raw_review_header)
review_posted_date = dateparser.parse(''.join(raw_review_posted_date).split('on ')[1]).strftime('%d %b %Y')
review_text = ''.join(raw_review_text)
review_dict = {
'review_author': review_author,
'review_rating': review_rating,
'review_header': review_header,
'review_text': review_text,
'review_posted_date': review_posted_date,
}
all_reviews.append(review_dict)Want a no-code solution to scrape reviews? Read this article: How to scrape Amazon reviews.
get_deals()
The get_deals() function handles the dynamic loading of deal content:
def get_deals(url):
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
deals = driver.find_elements(By.XPATH,'//div[contains(@id,"gridCell")]')
while len(deals) < 50:
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
deals = driver.find_elements(By.XPATH,'//div[contains(@id,"gridCell")]')
page_souce = driver.page_source
driver.quit()
return page_souceThis function uses Selenium because Amazon Fresh loads deals dynamically with JavaScript. It:
- Opens a Chrome browser
- Loads the deals page
- Scrolls down until it finds at least 50 deals
- Returns the page source for further processing
Next, the main execution block ties everything together:
It calls get_deals() to get the HTML code of the deas page, and extracts all the elements containing the information about the deal using lxml.
if __name__ == '__main__':
page_source = get_deals('https://www.amazon.com/fmc/alldeals/?...')
parser = html.fromstring(page_source)
deal_elements = parser.xpath('//div[contains(@id,"gridCell")]')For each deal found, the script extracts:
- Price to pay
- Price per unit
- Product link
- Product name
- Customer reviews (by calling the scrape function)
for element in deal_elements[:10]:
priceToPay = element.xpath('.//div[contains(@class,"priceToPay")]//text()')[0]
pricePerUnit = element.xpath('.//span[contains(@class,"pricePerUnit")]//text()')[0].replace('(','').replace(')','')
link = 'https://amazon.com'+element.xpath('.//a/@href')[0]
product = element.xpath('.//a//text()')[0]
reviews = scrape(link)The data is structured into a dictionary:
fresh_data.append({
"product": product,
"priceToPay": priceToPay,
"pricePerUnit": pricePerUnit,
"link": link,
"reviews": reviews
})save_to_json()
Finally, the save_to_json() function saves all collected data:
def save_to_json(data):
with open('amazon_deals.json','w',encoding='utf-8') as f:
json.dump(data,f,indent=4,ensure_ascii=False)Some important considerations about this script:
- The 2-second sleep between requests (sleep(2)) helps prevent getting blocked by Amazon’s rate-limiting
- The script only processes the first 10 deals (deal_elements[:10]) to avoid excessive requests
The data scraped from Amazon Fresh will look like this:
{
"product": "Strawberries, 1 Lb",
"priceToPay": "$3.48",
"pricePerUnit": "$3.48/lb",
"link": "https://amazon.com/Fresh-Produce-Brands-May-Vary/dp/B000P6J0SM?pd_rd_w=CFE4m&content-id=amzn1.sym.106a17c1-a8a1-4763-a45b-aceb262b7469&pf_rd_p=106a17c1-a8a1-4763-a45b-aceb262b7469&pf_rd_r=DVPZCGGR4M6GATJQ7X1N&pd_rd_wg=OzFan&pd_rd_r=07872b20-1a3d-4017-a99c-cbabced6e6fa&pd_rd_i=B000P6J0SM&fpw=alm&almBrandId=QW1hem9uIEZyZXNo&ref_=pd_alm_md_dsk_dl_adl_dfyg_sg_1_1_i",
"reviews": [
{
"review_author": "Valeria",
"review_rating": "5.0",
"review_header": "Fresh and good",
"review_text": "These were sweet. large and tasty and I am so glad I didn't have to buy more than a pound. Not one strawberry was in bad shape.",
"review_posted_date": "09 Jan 2025"
},
{
"review_author": "EvEv",
"review_rating": "5.05.0",
"review_header": "Very Fresh!",
"review_text": "I ordered three packs, and all of them were fresh and tasted great! I took the photo the next day, but they were even fresher when they arrived the evening before. So much better than searching for fresh ones in the markets!",
"review_posted_date": "22 Jan 2025"
},
{
"review_author": "It's sheer and stained ",
"review_rating": "5.0",
"review_header": "Not too sweet maybe it's real",
"review_text": "Never know what's real and not bio-engineered anymore but these tasted familiar. Took me back to when my mother used to make jam's for breakfast every Sunday morning and we'd watch Maggie and the Ferocious Beast.10/10 Thank you for that trip down memory lane",
"review_posted_date": "19 Jul 2024"
},
{
"review_author": "Olharleypurrs",
"review_rating": "5.0",
"review_header": "Signs and Wonders !",
"review_text": "Purchasing strawberries from Amazon stores, is worth every single penny because not one berry has a blemish, smushed, melted, discoloration or even reduction in bunch size. Going om, the quality, taste, texture, firmness, juice factor are the signs I look for and attest to till time ends.",
"review_posted_date": "28 Dec 2024"
},
{
"review_author": "robbidobb",
"review_rating": "4.0",
"review_header": "Tasty but a tad over ripe",
"review_text": "Would have been fine if we could eat the whole box in one day but they started to mold after just a couple of days",
"review_posted_date": "28 Aug 2024"
},
{
"review_author": "Royal Juno",
"review_rating": "5.0",
"review_header": "Fresh and good",
"review_text": "These are absolutely fresh and taste absolutely good. they are big and juicy as well. worth the money. i plan to order this again. i was skeptical at first but happy with purchase.",
"review_posted_date": "14 Nov 2024"
},
{
"review_author": "Andrea",
"review_rating": "5.0",
"review_header": "Great Strawberries",
"review_text": "I recently had the pleasure of trying the most incredible strawberries , and I must say, they are truly exceptional. These strawberries are a testament to the beauty and deliciousness of nature's bounty.First and foremost, the freshness of these strawberries is undeniable. Each berry is plump, vibrant, and bursting with flavor. You can tell that they were picked at the peak of ripeness, ensuring that every bite is a delightful explosion of sweetness. It's rare to find strawberries that are this fresh, and it makes all the difference in the world.The taste of these strawberries is simply divine. They are incredibly juicy, with a perfect balance of sweetness and acidity. Each bite is like a little taste of heaven, leaving you craving more. Whether you enjoy them on their own, in a salad, or as a topping for desserts, these strawberries will elevate any dish to new heights.One of the things that impressed me the most about these strawberries is their size. They are larger than your average strawberry, which means you get more bang for your buck. Not only are they visually stunning, but they also provide a satisfying mouthful with every bite.The quality of the strawberries is unmatched. It's evident that they take great care in cultivating and harvesting these berries. From the moment you lay eyes on them, you can see the attention to detail and the love that goes into growing these strawberries.I highly recommend strawberries to anyone who appreciates the beauty of fresh, delicious, and tasteful fruit. These strawberries are a true culinary delight that will leave you wanting more. Treat yourself to the exquisite experience of savoring these amazing strawberries, and you won't be disappointed.",
"review_posted_date": "06 May 2024"
},
{
"review_author": "Frank Phillips",
"review_rating": "5.0",
"review_header": "Its Amazon, Fast delivery, always best price, and always fresh.",
"review_text": "Its Amazon, Fast delivery, always best price, and always fresh.",
"review_posted_date": "02 Jan 2025"
}
]
}And here’s the complete code to scrape Amazon Fresh:
import requests, dateparser, json
from lxml import html
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
def scrape(link):
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
XPATH_REVIEWS = '//div[contains(@id,"customer_review-")]'
XPATH_TITLE= './/h5/a/span[not(@*)]/text()'
XPATH_RATING= './/i/span/text()'
XPATH_DATE= './/span[contains(@data-hook,"review-date")]/text()'
XPATH_AUTHOR= './/span[contains(@class,"a-profile-name")]/text()'
XPATH_REVIEW_TEXT = './/div[@data-hook="review-collapsed"]/span/text()'
source = requests.get(link,headers=headers)
parser = html.fromstring(source.text)
reviews = parser.xpath(XPATH_REVIEWS)
all_reviews = []
for review in reviews:
raw_review_author = review.xpath(XPATH_AUTHOR)
raw_review_rating = review.xpath(XPATH_RATING)
raw_review_header = review.xpath(XPATH_TITLE)
raw_review_posted_date = review.xpath(XPATH_DATE)
raw_review_text = review.xpath(XPATH_REVIEW_TEXT)
review_author = ''.join(raw_review_author)
review_rating = ''.join(raw_review_rating).replace(' out of 5 stars','')
review_header = ''.join(raw_review_header)
review_posted_date = dateparser.parse(''.join(raw_review_posted_date).split('on ')[1]).strftime('%d %b %Y')
review_text = ''.join(raw_review_text)
review_dict = {
'review_author': review_author,
'review_rating': review_rating,
'review_header': review_header,
'review_text': review_text,
'review_posted_date': review_posted_date,
}
all_reviews.append(review_dict)
return all_reviews
def save_to_json(data):
with open('amazon_deals.json','w',encoding='utf-8') as f:
json.dump(data,f,indent=4,ensure_ascii=False)
def get_deals(url):
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
deals = driver.find_elements(By.XPATH,'//div[contains(@id,"gridCell")]')
while len(deals) < 50:
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
deals = driver.find_elements(By.XPATH,'//div[contains(@id,"gridCell")]')
page_souce = driver.page_source
driver.quit()
return page_souce
if __name__ == '__main__':
page_souce = get_deals('https://www.amazon.com/fmc/alldeals/?_encoding=UTF8&almBrandId=QW1hem9uIEZyZXNo&ref=fs_dsk_sn_alldeals1-91399')
parser = html.fromstring(page_souce)
deal_elements = parser.xpath('//div[contains(@id,"gridCell")]')
fresh_data = []
for element in deal_elements[:10]:
priceToPay = element.xpath('.//div[contains(@class,"priceToPay")]//text()')[0]
pricePerUnit = element.xpath('.//span[contains(@class,"pricePerUnit")]//text()')[0].replace('(','').replace(')','')
link = 'https://amazon.com'+element.xpath('.//a/@href')[0]
product = element.xpath('.//a//text()')[0]
reviews = scrape(link)
fresh_data.append(
{
"product": product,
"priceToPay": priceToPay,
"pricePerUnit": pricePerUnit,
"link": link,
"reviews": reviews
}
)
sleep(2)
save_to_json(fresh_data)Code Limitations
You can perform a basic Amazon Fresh data scraping using the code explained. However,
- Error handling could be improved to make the script more robust
- The script assumes certain HTML structures that might change if Amazon Fresh updates its website
- Alter the script to bypass anti-scraping measures, which is necessary for large-scale scraping.
Why Use a Web Scraping Service
You can use this code to scrape Amazon fresh deals as long as Amazon doesn’t change the website structure. When that happens, change the XPaths accordingly. You also need to alter this code if you want more data about products, such as descriptions.
But why scrape yourself when you can delegate that part to a web scraping service? A web scraping service, like ScrapeHero, can take care of HTML structure changes and anti-scraping measures.
ScrapeHero is a fully-managed web scraping service that provides customized data solutions. Our services include handling your complete data pipeline and creating custom AI solutions.



