

According to Grand View Research, the NFT marketplace might reach around 211 billion by 2030. That’s not a small number. One way to stay updated with this growing market is by web scraping NFT marketplaces.
This article explores how you can scrape NFT listings using Playwright and BeautifulSoup.
The Environment for Web Scraping NFT Marketplaces
This tutorial uses three external Python libraries:
- Playwright: An automated browser that interacts with dynamic web pages.
- BeautifulSoup: A parsing library that has intuitive methods to parse HTML code.
- lxml: A low-level HTML parser used by BeautifulSoup in this code.
Install these packages using PIP.
pip install requests selenium beautifulsoup4
The Data Extracted from NFT Marketplaces
The code in this tutorial extracts details of the
- Trending NFT collections from OpenSea’s homepage
- Latest NFT drops (newly released NFTs) from Rarible’s homepage
Data Extracted from OpenSea
The details extracted from the trending NFT collections on OpenSea include:
- URL
- Rank
- Name
- Floor Price
- 24-h volume
Use your browser’s inspect features to locate the elements holding these data points. Knowing their attributes allows you to determine which BeautifulSoup selectors to use.
To use the inspect feature, right-click on a data point and click ‘Inspect’ from the context menu.
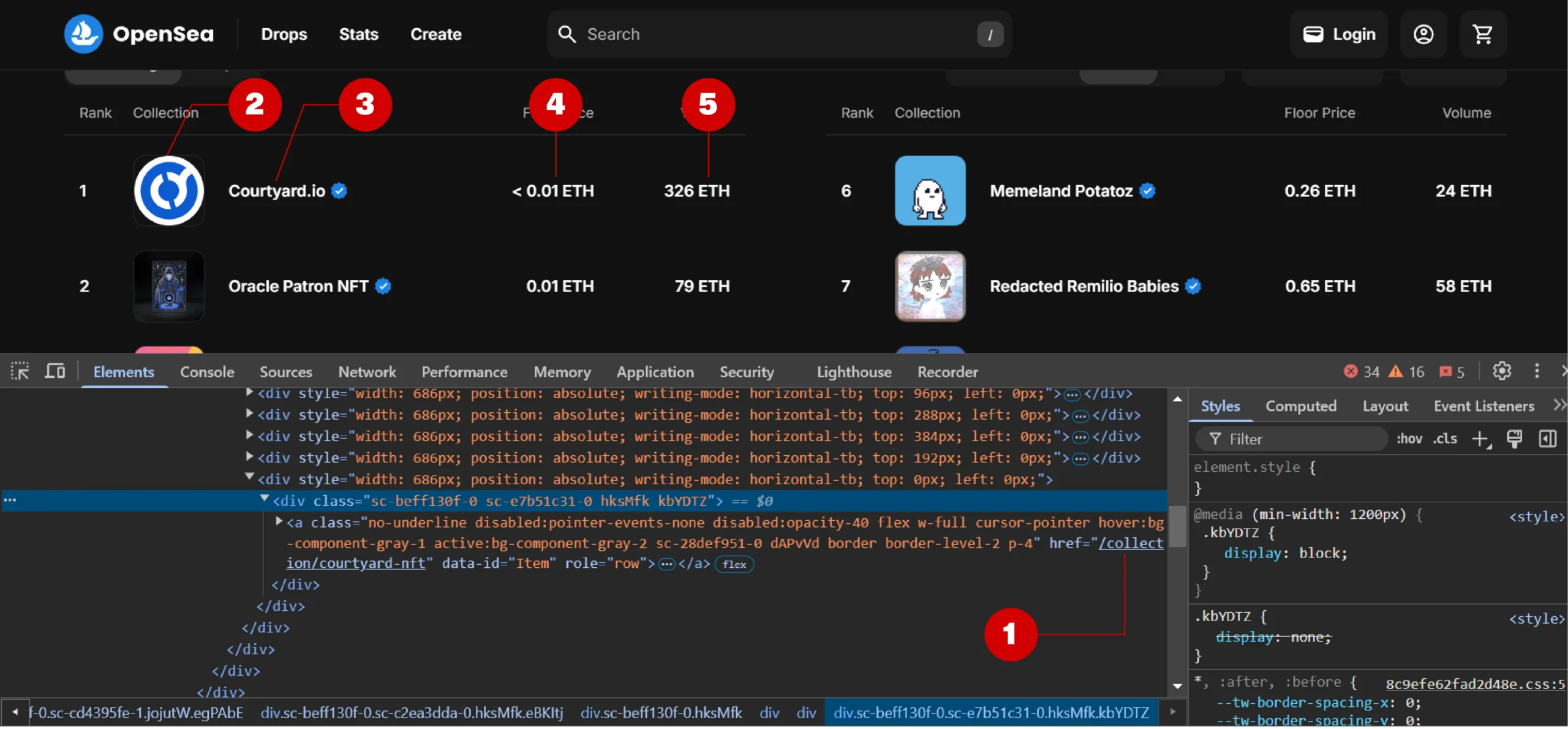
In the above figure, you can see that an anchor tag holds the collection details, and it has an attribute ‘role= “row”’
So, using BeautifulSoup’s find_all() method, you can select all rows using this code:
soup.find_all(‘a’,{‘role’= ‘row’})Here, soup is a BeautifulSoup object.
You can figure out the selectors of the other data points in a similar way.
Data Extracted from Rarible
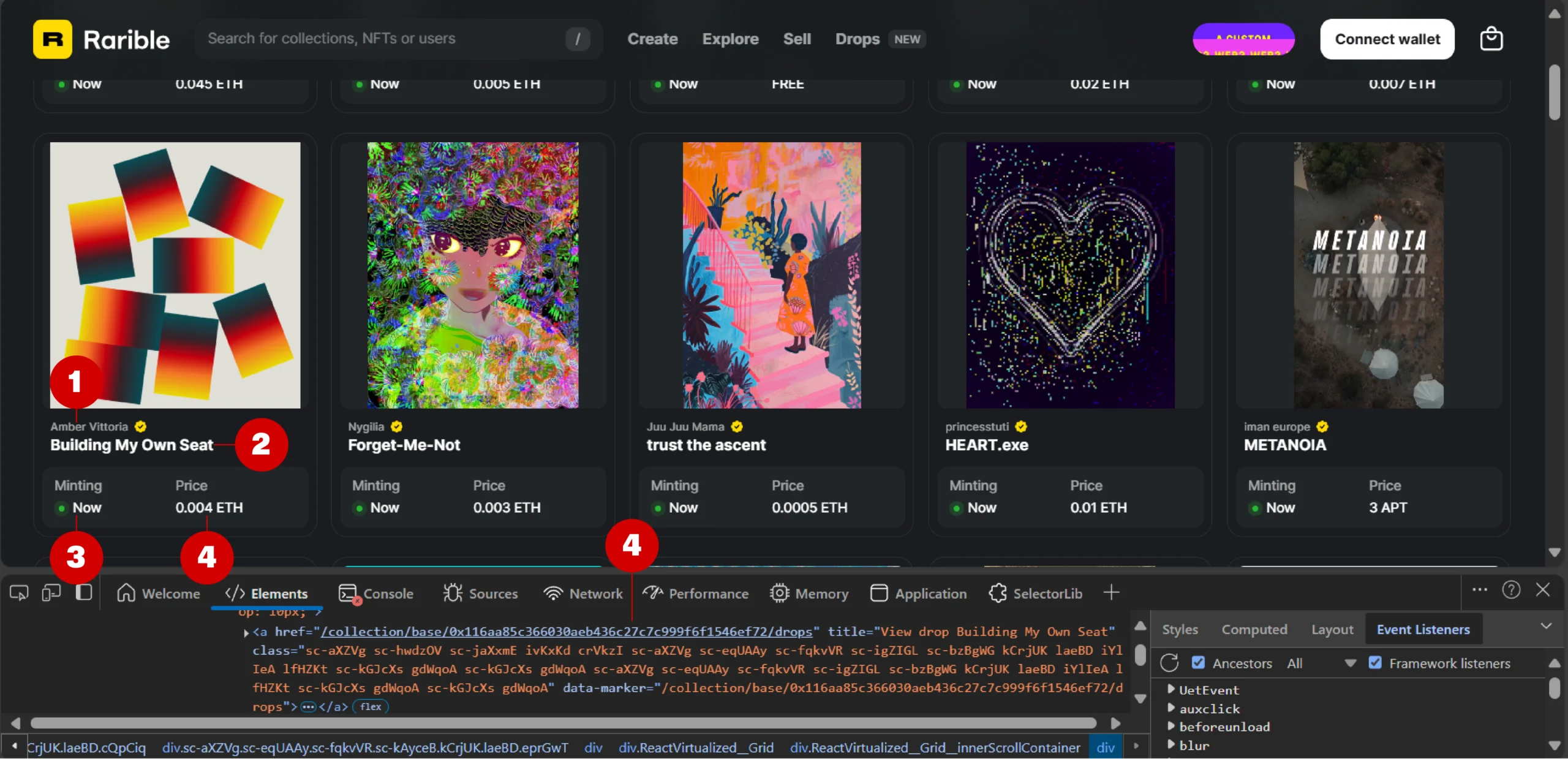
The details in the latest drops from Rarible include:
- Creator
- Name
- Status
- Price
- URL

The Code for Web Scraping NFT Marketplaces
Start your code for web scraping NFT data by importing the necessary packages:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import json, reThe above code also imports json, which enables you to handle JSON data.
Next, define separate functions to extract data from each marketplace:
- get_trending(): Gets details of the trending NFT collections from Opensea.io
- get_latest_drops(): Gets details of the latest NFT drops from Rarible
get_trending()
This function uses Playwright synchronous API to navigate to OpenSea’s homepage and extract the trending data.
It starts by launching a headless Chromium browser.
def get_trending():
with sync_playwright() as playwright:
browser = playwright.chromium.launch()Next, it creates a new context using the ‘new_context()’ method, allowing Playwright to add custom headers to avoid detection.
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
context = browser.new_context(extra_http_headers=headers)The function then uses Playwright’s new_page() method to create a new page and the goto() method to navigate to the target page.
page = context.new_page()
page.goto('https://opensea.io/',timeout=60000)Since the elements will take some time to load, Playwright waits for the target selector (div element with role= “table”) to load before proceeding to the next step.
page.wait_for_selector('//div[@role="table"]',timeout=60000)After the target element loads, the function parses HTML source extracts all the elements holding the collection details.
soup = BeautifulSoup(page.content(), 'lxml')
stats_table = soup.find('div',{'data-testid':'Home--statsTable'})
rows = stats_table.find('div',{'role':'table'}).find_all('a',{'role':'row'})Now, you can iterate through the elements and extract the required data points. Analyzing the HTML code will show that all the data points are inside span elements. Therefore, in each iteration, the function:
- Gets all the span elements
- Extracts the required data points
- Appends them to a list defined outside the loop
trending_collections = []
for row in rows:
spans = row.find_all('span')
trending_collections.append(
{
'url':'https://opensea.io'+row['href'],
'rank':spans[0].text,
'name':spans[2].text,
'floor_price':spans[3].text,
'24h_volume':spans[4].text,
}
)The extracted details will not be in any order. So, use the sorted() function to order them in the increasing order of the rank.
sorted_collections = sorted(trending_collections, key=lambda x: int(x['rank']))with open('trending_collections.json','w', encoding='utf-8') as f:
json.dump(sorted_collections, f, ensure_ascii=False, indent=4)
get_latest_drops()
This function also uses Playwright to fetch the HTML source code.
def get_latest_drops():
with sync_playwright() as playwright:
page = browser.new_page()
page.goto('https://rarible.com/drops')
page.wait_for_selector('//a[contains(@title,"View drop")]')
source = page.content()As before, it uses BeautifulSoup to parse.
soup = BeautifulSoup(source, 'lxml')However, it uses a RegEx pattern to locate the element holding the details of the NFT drops. You need to use RegEx because the target elements contain ‘View drop’ in their title attribute; this partial matching requires you to use a RegEx pattern.
drop_pattern = re.compile(r'View drop')
drops = soup.find_all('a',{'title':drop_pattern})Once the function locates all the elements holding the NFT drop details, it iterates through them and extracts the required data points.
for drop in drops:
spans = drop.find_all('span')
if len(spans) == 9:
latest_drops.append(
{
'Creator':spans[2].text,
'Name':spans[3].text,
'Status':spans[4].text,
'Price':spans[8].text,
'URL':'https://rarible.com'+drop['href']
}
)
else:
latest_drops.append(
{
'Creator':spans[2].text,
'Name':spans[3].text,
'Status':spans[5].text,
'Price':spans[7].text,
'URL':'https://rarible.com'+drop['href']
}
)After NFT-data extraction, save the results into a JSON file, as before.
with open('latest_drops.json','w', encoding='utf-8') as f:
json.dump(latest_drops, f, ensure_ascii=False, indent=4)You can now call these functions directly or give the user a choice. To do so, use input() to get the user’s preference and call the function accordingly.
Create a mapping dict with options as key-value pairs.
nft_mapping = {
'1':get_trending,
'2':get_latest_drops
}Next, create a recursive function that
- Prompts the user to enter either 1 or 2
- Uses the choice as the key in the mapping dict
- Calls itself when the user inputs a number other than 1 or 2
def get_pref():
try:
pref = input('Enter:\n\t1) For trending NFT collections from Opensea\n\t2) For latest NFT drops on Rarible')
nft_mapping[pref]()
except KeyboardInterrupt:
return
except KeyError:
print('Wrong Choice! Enter either 1 or 2')
get_pref()
except Exception as e:
print(e)Finally, call this recursive function.
Here’s the complete code for web scraping NFT details.
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import json, re
def get_trending():
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False)
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
context = browser.new_context(extra_http_headers=headers)
page = context.new_page()
page.goto('https://opensea.io/',timeout=60000)
page.wait_for_selector('//div[@role="table"]',timeout=60000)
soup = BeautifulSoup(page.content(), 'lxml')
stats_table = soup.find('div',{'data-testid':'Home--statsTable'})
rows = stats_table.find('div',{'role':'table'}).find_all('a',{'role':'row'})
trending_collections = []
for row in rows:
spans = row.find_all('span')
trending_collections.append(
{
'url':'https://opensea.io'+row['href'],
'rank':spans[0].text,
'name':spans[2].text,
'floor_price':spans[3].text,
'24h_volume':spans[4].text,
}
)
sorted_collections = sorted(trending_collections, key=lambda x: int(x['rank']))
with open('trending_collections.json','w', encoding='utf-8') as f:
json.dump(sorted_collections, f, ensure_ascii=False, indent=4)
# define a function to g et latest drops from rarible.com
def get_latest_drops():
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://rarible.com/drops')
page.wait_for_selector('//a[contains(@title,"View drop")]')
source = page.content()
soup = BeautifulSoup(source, 'lxml')
drop_pattern = re.compile(r'View drop')
drops = soup.find_all('a',{'title':drop_pattern})
latest_drops = []
for drop in drops:
spans = drop.find_all('span')
if len(spans) == 9:
latest_drops.append(
{
'Creator':spans[2].text,
'Name':spans[3].text,
'Status':spans[4].text,
'Price':spans[8].text,
'URL':'https://rarible.com'+drop['href']
}
)
else:
latest_drops.append(
{
'Creator':spans[2].text,
'Name':spans[3].text,
'Status':spans[5].text,
'Price':spans[7].text,
'URL':'https://rarible.com'+drop['href']
}
)
with open('latest_drops.json','w', encoding='utf-8') as f:
json.dump(latest_drops, f, ensure_ascii=False, indent=4)
if __name__ == '__main__':
nft_mapping = {
'1':get_trending,
'2':get_latest_drops
}
def get_pref():
try:
pref = input('Enter:\n\t1) For trending NFT collections from Opensea\n\t2) For latest NFT drops on Rarible')
nft_mapping[pref]()
except KeyboardInterrupt:
return
except KeyError:
print('Wrong Choice! Enter either 1 or 2')
get_pref()
except Exception as e:
print(e)
get_pref()Code Limitations
The code can perform NFT-marketplace scraping, but
- Extracts Limited Data Points: The code only gets trending collections and the latest drops. If you want other details, you need to figure out the selectors and alter the code yourself.
- May Break Upon a Change in HTML Structure: Both OpenSea and Rarible may change the HTML structure, requiring you to figure out new selectors.
- Can’t Bypass Advanced Anti-Scraping Measures: The code won’t bypass advanced anti-scraping measures, like CAPTCHA or IP blocking, which makes it unsuitable for large-scale projects.
Wrapping Up: Why Use a Web Scraping Service
You can certainly begin web scraping NFT marketplaces using the code shown in this tutorial. However, if your goal is to merely get data, it’s better to use a web scraping service.
That is because the limitations—including the need for continuous monitoring and lack of techniques to bypass anti-scraping measures—can be an unnecessary burden.
A web scraping service like ScrapeHero can lift that burden off of you. Our experts at ScrapeHero can build high-quality scrapers that’ll overcome all limitations.
We are an enterprise-grade web scraping service that can fulfill all your data needs, from extracting data to creating custom AI solutions for analysis. Just tell us the data you need, and we’ll take care of the rest.



