

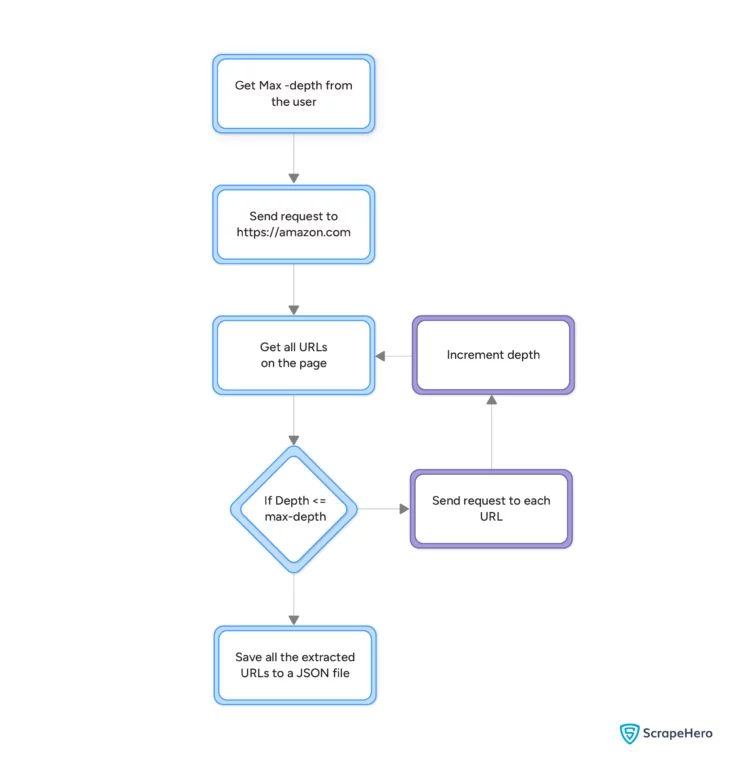
Amazon web crawling requires a script that hunts for only links, meaning you don’t have to worry about the website’s structure. The script will visit a URL, extract URLs on the page, and repeat the process for each extracted URL. You can use Python to build such a script.
This tutorial shows you how to build an Amazon web crawler using Python requests and BeautifulSoup.
Amazon Web Crawler: The Environment
You need four Python packages to run the code shown in this tutorial:
- Python requests
- BeautifulSoup
- The json module
- The urllib.parse module
The code uses Python requests to send HTTP requests to the Amazon server and BeautifulSoup to extract links.
These are external libraries, so you need to install them. You can do that using the package manager pip.
pip install requests beautifulsoupIt uses urllib.parse to make the extracted links absolute. This process is necessary because the ‘href’ attribute may contain relative links, which are uncrawlable. You don’t have to install urllib.parse as it comes with the Python standard library.
The code uses the json module to save the extracted URLs as a JSON file. This package also comes with the Python standard library.
Amazon Web Crawler: The Code
Import the four packages mentioned above to use in the code.
import requests, json
from bs4 import BeautifulSoup
from urllib.parse import urljoinAmazon does not prohibit crawling explicitly but will block any request via Python requests; therefore, define headers to make your request appear legitimate. You can specify headers using a JSON object.
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
The code uses a max_depth variable to prevent the crawler from continuing indefinitely. The crawler accepts the value for this variable from the user and crawls until the current depth equals the max_depth.
A recursive function crawlPage() allows you to perform the crawling process.
The function crawlPage()
This function accepts four arguments.
- url: URL of the webpage to be crawled
- depth: The current depth of the crawler
- mdepth: The maximum depth upto which the crawler will crawl
- visited: Already crawled URLs
The crawler starts by checking if the current depth is less than the max depth and if the current URL has yet to be visited. If the condition is true, the crawler adds the current URL to the visited set and starts crawling.
if depth <= mdepth and url not in visited:
# begin crawling by adding the url to the crawled list
visited.add(url)
crawlPage() then sends an HTTP request to the URL with the above headers.
response = requests.get(url,headers=headers)It parses the response text using BeautifulSoup and finds all the anchor tags. The anchor tags contain the required URL as the ‘href’ attribute, which you can also extract using BeautifulSoup.
soup = BeautifulSoup(response.text)
tags = soup.find_all('a')To store the URLs, create an empty dict.
newUrls = {}Next, crawlPage() iterates through the tags, and in each loop it
- Extracts the link from the ‘href’ attribute and make the extracted link absolute.
url = urljoin("https://amazon.com",tag['href']) - Calls itself with four arguments
- Newly extracted URL
- Depth incremented by one
- The mdepth variable
- The visited variable
urls = crawlPage(url, depth+1, mdepth,visited)
- Updates the empty dict defined above
- With the URLs returned in the second step
if urls: newUrls.update({" ".join(tag.text.split()):{"link":url,"subUrls":urls}}) - With the current URL, if the second step did not return any URLs
elif url !="https://amazon.com" and url !="javascript:void(0)": newUrls.update({" ".join(tag.text.split()):url})
- With the URLs returned in the second step
After the loop ends, crawlPage() returns the collected URLs.
return newUrlsIn the main part of the program, initialize the visited variable with a set() object. This set keeps track of the visited URLs; the crawler updates the set whenever it encounters unvisited URLs.
visited = set()Initialize the start URL with “https://amazon.com.” This URL will be the starting point of the crawling; in other words, the crawler first gets all the links from this page.
start_url = "https://amazon.com"Get the user’s depth and store it in a max_depth variable. This variable limits the crawler’s operation; you can get the value for this variable using the input() function.
max_depth = int(input("Enter the maximum depth: "))Call crawlPage() and store the returned URLs in crawled_urls.
crawled_urls = crawlPage(start_url, 1, max_depth,visited)Finally, save the URLs in a JSON file using json.dump().
with open("crawled.json","w",encoding="utf-8") as f:
json.dump(crawled_urls,f,indent=4,ensure_ascii=False)The JSON file would be similar to this.
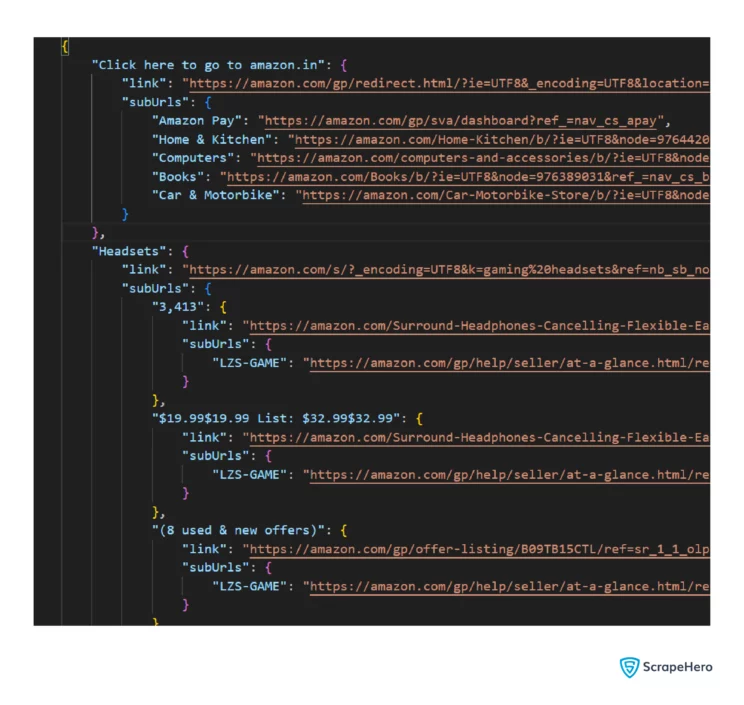
The keys in the JSON file would be the anchor text of the scraped URLs, and the values would be the page URL and the URLs on that page.
Here is the complete code for the Amazon Web Crawler using Python.
import requests, json
from bs4 import BeautifulSoup
from urllib.parse import urljoin
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
def crawlPage(url, depth, mdepth,visited):
if depth <= mdepth and url not in visited:
visited.add(url)
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text)
tags = soup.find_all('a')
newUrls = {}
for tag in tags[20:25]:
#use a try except block to avoid errors when the crawler detects links without an href tag
try:
url = urljoin("https://amazon.com",tag['href'])
urls = crawlPage(url, depth+1, mdepth,visited)
if urls:
newUrls.update({" ".join(tag.text.split()):{"link":url,"subUrls":urls}})
elif url !="https://amazon.com" and url !="javascript:void(0)":
newUrls.update({" ".join(tag.text.split()):url})
except Exception as e:
continue
return newUrls
if __name__ == "__main__":
visited = set()
start_url = "https://amazon.com"
max_depth = int(input("Enter the maximum depth: "))
crawled_urls = crawlPage(start_url, 1, max_depth,visited)
with open("crawled.json","w",encoding="utf-8") as f:
json.dump(crawled_urls,f,indent=4,ensure_ascii=False)
Code Limitations
This Amazon web crawler using Python will get URLs from Amazon, but it does have some limitations:
- Does not extract dynamic links
- Not suitable for large-scale crawling
- Does not index the links
Does not extract dynamic links
The code does not get the URLs that are available after executing JavaScript. That means you can not get dynamic links with this code; for that, you need to scrape using Playwright.
Not suitable for large-scale crawling
The crawler is not suitable for large-scale projects because of anti-scraping measures. These measures become apparent in large-scale crawling because the volume of HTTP requests increases, making your scraper more discoverable.
You need techniques like rotating proxies to overcome the measures.
Does not index the links
After crawling, it is necessary to index the links. Indexing stores the links in categories for later use, which is especially necessary if you want to build an Amazon products web crawler.
Wrapping Up
You can build an Amazon crawler using Python requests and BeautifulSoup. However, you can’t extract dynamic links using this code. Moreover, you need to add additional code to negotiate anti-scraping measures.
If you want to avoid coding or plan to scrape at a large scale, contact ScrapeHero and forget about learning how to crawl Amazon yourself.
ScrapeHero is a full-service, enterprise-grade web scraper capable of building high-quality web crawlers. ScrapeHero services include large-scale web scraping and crawling, brand and price monitoring, and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


