

Google Search now requires JavaScript. Consequences? You can’t use HTTP requests to scrape data from its search results page. However, there is a workaround. You can use browser automation libraries like Selenium or Puppeteer for scraping Google’s dynamic search results.
This article discusses scraping dynamic content from Google SERP using JavaScript (Node.js) and Python.
Data Extracted In Real Time
This tutorial shows you how to scrape Google’s dynamic search results by monitoring the real-time share price of a company. That means you only need to focus on one data point: the stock price.
By analyzing the SERP’s HTML, you can see that the stock price is inside a div element with the attribute ‘data-attrid=”Price.”
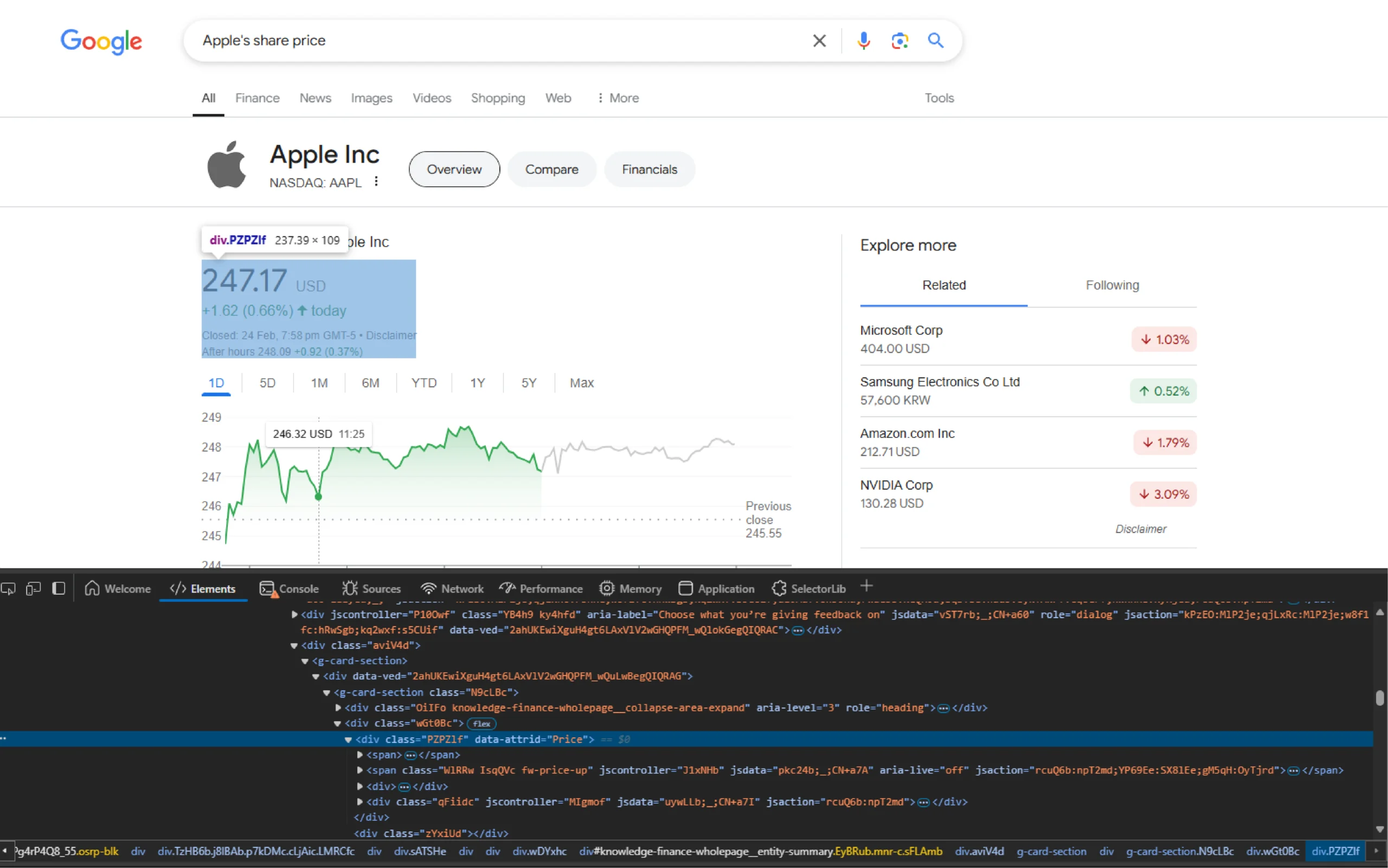
Therefore, you can use the CSS selector ‘div[data-attrid=”Price”]’ to locate it. This selector will work with both JavaScript and Python.

Scraping Google’s Dynamic Results Using JavaScript
Start by creating a folder for your JavaScript scraping project.
mkdir my_javascript_projectLocally install Puppeteer using npm.
npm install puppeteerCreate a file with .js and start writing the code. The code begins by importing the required packages, namely puppeteer, fs, and path.
const puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
const readline = require('readline');Puppeteer is a browser automation library that allows you to control a browser programmatically. The other packages (path and fs) enable you to interact with directories, including creating files.
Next, create a function monitorElement() that accepts Puppeteer’s page object, a selector, and a CSV file’s path.
async function monitorElement(page, selector, csvPath) {
// the code
}This function will
- Monitor an element
- Extract stock prices in real-time
- Save prices in a CSV file
Start the function by locating the element using page.waitForSelector(). The method waitForSelector() ensures that Puppeteer waits until the element is loaded before moving on to the next step.
const elementHandle = await page.waitForSelector(selector, { timeout: 50000 });Sometimes, the element may not be present. Therefore, use an if statement to handle the absence of the element; here, the function throws an error.
if (!elementHandle) {
throw new Error(`Element with selector "${selector}" not found`);
}The next step is to create a CSV file to store prices and timestamps. However, you only need to create a new CSV file if it doesn’t already exist, so use an if block.
if (!fs.existsSync(csvPath)) {
fs.writeFileSync(csvPath, 'timestamp,price\n');
}To extract data from Google’s search-results page, you need to evaluate a script in the browser’s context. To do so, use the evaluate() method of Puppeteer’s page object. This method takes a script and the selector that targets the stock price.
await page.evaluate((selector) => {
//script
},selector)The code will execute the script within the browser’s context and detect changes in the element targeted by the selector.
Here’s what the script does:
1. Initializes a variable lastValue that’ll store the last observed price.
let lastValue = null;2. Creates an object of the MutationObserver class and initializes it with a function that runs when the object detects changes in HTML code.
const observer = new MutationObserver(() => {
const targetNode = document.querySelector(selector);
if (!targetNode) return;
const currentValue = targetNode.textContent.trim();
// Only log if the value has actually changed
if (currentValue !== lastValue) {
// Send both value and timestamp to Node.js context
console.log(JSON.stringify({
type: 'price_change',
price: currentValue,
timestamp: new Date().toISOString()
}));
lastValue = currentValue;
}
});3. Selects the element holding the price—stops the execution if the element is absent.
const targetNode = document.querySelector(selector);
if (!targetNode) {
console.error(`Element with selector "${selector}" not found.`);
return;
}4. Gets the initial price and passes it to the variable lastValue.
lastValue = targetNode.textContent.trim();5. Logs this price and the timestamp in the browser’s console.
console.log(JSON.stringify({
type: 'price_change',
price: lastValue,
timestamp: new Date().toISOString()
}));6. Calls the observe() method of the MutationObserver object created earlier.
observer.observe(targetNode, {
characterData: true,
childList: true,
subtree: true
});When the script calls the observe() method, it starts looking for changes in the targeted element. When it detects a change—either in the text content or the child elements—it executes the function passed to it in the second step, which
- Logs the current price if it is different from the value in the variable lastValue.
- Replaces the value of lastValue with the current price.
Now, you need to get the console messages logged by page.evaluate(). For that, you can use page.on().
page.on('console', msg => {
try {
const data = JSON.parse(msg.text());
if (data.type === 'price_change') {
const csvLine = `${data.timestamp},${data.price.replace(',','')}\n`;
fs.appendFileSync(csvPath, csvLine);
console.log(`Recorded: ${data.price} at ${data.timestamp}`);
}
} catch (e) {
// Ignore non-JSON console messages
}
});
The above code gets a console message with the type ‘price_change’ and saves it to the CSV file created previously.
Your monitorElement() function is now complete. To call it, use a function main(), which will:
1. Get the stock name from the user using the readline package.
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const stock = await new Promise((resolve) => {
rl.question('Enter the stock name: ', (answer) => {
resolve(answer);
rl.close();
});
});2. Use that name to create a CSV file path.
const csvPath = path.join(__dirname, `${stock}_prices_${new Date().toISOString().replace(/:/g, '-')}.csv`);3. Launch the Puppeteer browser.
const browser = await puppeteer.launch({
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});4. Create a new page.
const page = await browser.newPage();5. Navigate to the SERP and waits until there’s no network activity.
await page.goto(`https://www.google.com/search?q=${stock}+stock+price`, {
waitUntil: 'networkidle0'
});6. Call monitorElement() with the page, selector, and the CSV path as arguments.
await monitorElement(page, 'div[data-attrid="Price"]>span', csvPath);7. Create a new Promise that never resolves, essentially keeps MutationObserver() working.
await new Promise(() => {});Finally, call main().
Here’s the complete JavaScript code for scraping Google’s dynamic search results.
const puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
const readline = require('readline');
async function monitorElement(page, selector, csvPath) {
try {
const elementHandle = await page.waitForSelector(selector, { timeout: 50000 });
if (!elementHandle) {
throw new Error(`Element with selector "${selector}" not found`);
}
// Create CSV file with headers if it doesn't exist
if (!fs.existsSync(csvPath)) {
fs.writeFileSync(csvPath, 'timestamp,price\n');
}
await page.evaluate((selector) => {
let lastValue = null;
const observer = new MutationObserver(() => {
const targetNode = document.querySelector(selector);
if (!targetNode) return;
const currentValue = targetNode.textContent.trim();
// Only log if the value has actually changed
if (currentValue !== lastValue) {
// Send both value and timestamp to Node.js context
console.log(JSON.stringify({
type: 'price_change',
price: currentValue,
timestamp: new Date().toISOString()
}));
lastValue = currentValue;
}
});
const targetNode = document.querySelector(selector);
if (!targetNode) {
console.error(`Element with selector "${selector}" not found.`);
return;
}
lastValue = targetNode.textContent.trim();
// Log initial value
console.log(JSON.stringify({
type: 'price_change',
price: lastValue,
timestamp: new Date().toISOString()
}));
observer.observe(targetNode, {
characterData: true,
childList: true,
subtree: true
});
}, selector);
// Handle console messages to write to CSV
page.on('console', msg => {
try {
const data = JSON.parse(msg.text());
if (data.type === 'price_change') {
const csvLine = `${data.timestamp},${data.price.replace(',','')}\n`;
fs.appendFileSync(csvPath, csvLine);
console.log(`Recorded: ${data.price} at ${data.timestamp}`);
}
} catch (e) {
// Ignore non-JSON console messages
}
});
} catch (error) {
console.error('Error in monitorElement:', error);
throw error;
}
}
async function main() {
let browser;
try {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const stock = await new Promise((resolve) => {
rl.question('Enter the stock name: ', (answer) => {
resolve(answer);
rl.close();
});
});
const csvPath = path.join(__dirname, `${stock}_prices_${new Date().toISOString().replace(/:/g, '-')}.csv`);
browser = await puppeteer.launch({
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
const page = await browser.newPage();
await page.goto(`https://www.google.com/search?q=${stock}+stock+price`, {
waitUntil: 'networkidle0'
});
await monitorElement(page, 'div[data-attrid="Price"]>span', csvPath);
await new Promise(() => {});
} catch (error) {
console.error('Error in main:', error);
} finally {
if (browser) {
await browser.close();
}
}
}
main();
Web Scraping Google’s Dynamic Pages Using Python
The JavaScript code explained above showed how to get the price whenever it changed. However, there is another method. You can also keep checking whether the value changed; this is called polling.
You can read how to use polling with Python in this section. You’ll need two Python packages:
- Selenium: A browser automation library
- Pandas: A data analysis library
Begin by importing the necessary packages:
- webdriver and By from Selenium: The webdriver module controls the browser, and By allows you to specify how you want to locate an element (by xpath, CSS selectors, etc.).
- Pandas: To save the extracted data to a CSV file
- sleep from time: To pause script execution when needed
- datetime: To get the current date and time
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import pandas as pd
import datetimeNext, use input() to get a stock name from. The code willcode’ll use this to build the SERP’s URL.
stock = input('Enter the stock name: ')You can then launch a Selenium browser and navigate to the URL. While several browsers are available, this tutorial uses a Chrome instance.
browser = webdriver.Chrome()
browser.get(f'https://www.google.com/search?q={stock}+stock+price')To store the prices extracted using the browser, define an empty Pandas DataFrame.
prices = pd.DataFrame(columns=['Time','Price'])Since you only want to store the price if it changes, initialize a variable last_price that stores the last observed price. This allows you to compare the current price with the previously observed price.
last_price = NoneTo periodically extract prices, you can use a loop. In a try-except block, start a while loop that runs until there is an error. In the loop,
1. Select the stock price using a CSS selector.
price = browser.find_element(By.CSS_SELECTOR, 'div[data-attrid="Price"]>span')2. Get the current time using datetime.
dt = datetime.datetime.now()3. Check if the current price is equal to the last price:
- If they are, skip the block.
- Else, replace the value of last_price with the current price and add the value and the current time to the DataFrame.
if last_price != price.text:
last_price = price.text
print(price.text)
prices.loc[len(prices)] = [dt.strftime("%H:%M:%S"), price.text] 4. Pause script execution for 10 seconds.
sleep(10)Finally, if the code encounters an error, it writes all the extracted prices to a CSV file using Pandas’ to_csv() method. And quits the browser.
prices.to_csv(f'{stock}_share_prices_{dt.strftime("%Y-%m-%d")}.csv', index=False)
browser.quit()Here’s the complete Python script for scraping Google’s dynamic search results.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import pandas as pd
import datetime
if __name__ == '__main__':
stock = input('Enter the stock name: ')
browser = webdriver.Chrome()
browser.get(f'https://www.google.com/search?q={stock}+stock+price')
sleep(25)
prices = pd.DataFrame(columns=['Time','Price'])
last_price = None
try:
while True:
price = browser.find_element(By.CSS_SELECTOR, 'div[data-attrid="Price"]>span')
dt = datetime.datetime.now()
if last_price != price.text:
last_price = price.text
print(price.text)
prices.loc[len(prices)] = [dt.strftime("%H:%M:%S"), price.text]
sleep(10)
except:
prices.to_csv(f'{stock}_share_prices_{dt.strftime("%Y-%m-%d")}.csv', index=False)
browser.quit()
Code Limitations
Your scraper may encounter a CAPTCHA. That means you need to solve the CAPTCHA before starting the monitoring task. This is not a problem if you only want to monitor one or two data points because you can do it manually. However, for large-scale monitoring, you need to figure out automated methods to solve CAPTCHAs.
Moreover, Google may periodically change the HTML structure. That means you need to figure out new selectors if Google changes the HTML structure.
Wrapping it Up: Why Use a Web Scraping Service
You can use the code in this tutorial to handle scraping Google’s dynamic search results, but you must deal with the limitations yourself. Instead, why not consider a web scraping service if you only need the data?
With a web scraping service like ours at ScrapeHero, you don’t have to worry about CAPTCHAs or structural changes.
At ScrapeHero, we provide enterprise-grade web scraping services. We also cover custom robotic process automation and AI solutions. You only need to provide data requirements; we’ll take care of everything else.


