Walmart is a multinational chain of Hypermarkets, discount stores, and grocery stores. Knowing the Walmart store locations will help you understand market saturation, which will help you place your stores strategically. However, physically getting the details of Walmart stores is impractical; web scraping Walmart store locations is the practical alternative.
In this tutorial, you will learn how web scraping Walmart using Python works.
Set Up The Environment for Web Scraping Walmart Store Locations
This tutorial uses two external Python libraries: selenium and pandas. You can use pip, Python’s package manager, to install these packages.
Use this code to install Selenium and Pandas.
pip install selenium pandasSelenium can automate the browser to visit Walmart’s page and get the location details, and Pandas will enable you to save the extracted data to a CSV file.
Data Scraped from Walmart
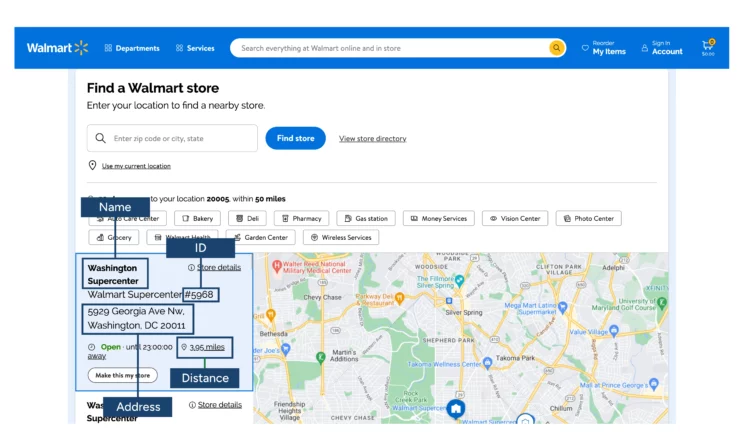
This tutorial for web scraping Walmart store locations will extract four data points:
- Store name
- ID
- Address
- Distance from the zip code.
The code will get the zipcode from the user via command line arguments, visit the Walmart website, extract data, clean it, and save it to a CSV file.
The Code for Web Scraping Walmart Store Locations
You will first import the necessary packages for Scraping Walmart:
- Argparse, for enabling the script to accept arguments from the command line
- Selenium, for visiting the Walmart store location page and extracting the data
- Pandas, for saving the extracted data into a CSV file
import argparse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import pandasYou must have noticed that you don’t directly import selenium. Instead, you only import the various modules from the Selenium library, which is more convenient.
Creating a separate function for visiting the link and extracting the data will be cleaner; therefore, you will make a function locate_stores() that will accept the zip code as an argument and return the scraped data as an object.
def locate_stores(zip_code):Walmart doesn’t like bots scraping their data, so you will likely encounter their anti-scraping measures. They may detect that you are using an automated browser to visit the website and block you, making it necessary to take steps to bypass their detection.
This code uses one such method to scrape without getting blocked; it deactivates the flags telling websites that the browser is automation-controlled. You can turn this off by adding the appropriate argument in the options() method.
options = Options()
options.add_argument("start-maximized")
options.add_argument('--disable-blink-features=AutomationControlled')After that, you can start the browser instance with options as an argument and visit the website.
driver = webdriver.Chrome(options=options)
driver.get(url)Examining the HTML code will show you that the data points are inside a div element with the attribute aria-label=’results-list.’ You can locate this div element using its XPath.
results = driver.find_element(By.XPATH,"//div[@aria-label='results-list']")There are two ways for web scraping Walmart store locations: You can get all the text from the section and clean it for required data or find the XPaths of each data point. This code uses the first method to scrape Walmart.
You will extract all the text from the section, then use the split() method to separate the store details. split() will separate the values in a string and store them in an array. It takes a string as an argument, which it uses as the separator.
For example, consider the string “grapes, oranges, apples, strawberries.” You will get [grapes, oranges, apples, strawberries] using the split() method with a comma as the argument.
The screenshot above shows you a “make this my store” text at the end of each store section. You will use this text as the argument for the split() method.
stores = results.text.split("\nMake this my store")Now, you have store details as separate items in an array.
However, the details of each store are still in a string with newline characters separating them. Therefore, you must use the newline character as the split() argument to separate each detail, giving you an object.
store_details = []
for store in stores:
store_details.append(store.split('\n'))
The next step is to clean the object. You can do that with Pandas:
- Convert the object into a Pandas DataFrame
df = pandas.DataFrame(store_details) - Drop unwanted columns.
df2 = df.drop(df.columns[0],axis=1) df3 = df2.drop(df.columns[1],axis=1) - Drop rows with null values.
df4 = df3.dropna()
The function also transforms a column. You use regular expressions to extract the distance from the string.
df4[5] = df4[5].str.extract(r'\.(\d+)',expand=False)Finally, it returns the extracted and cleaned data.
Essentially, the code performs three tasks:
- Use the argparse module to enable the script to access arguments from the command line
argparser = argparse.ArgumentParser() argparser.add_argument('zip_code',help = 'zip code to search') args = argparser.parse_args() zip_code = args.zip_code - Call the locate_stores() function
scraped_data = locate_stores(zip_code) - Save the extracted data as a CSV file using Pandas
scraped_data.to_csv("walmart.csv")
Here is the complete code for web scraping Walmart locations.
import argparse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import pandas
def locate_stores(zip_code):
options = Options()
options.add_argument("start-maximized")
options.add_argument('--disable-blink-features=AutomationControlled')
url = "https://www.walmart.com/store-finder?location=%s&distance=500"%(zip_code)
driver = webdriver.Chrome(options=options)
driver.get(url)
results = driver.find_element(By.XPATH,"//div[@aria-label='results-list']")
stores = results.text.split("\nMake this my store")
store_details = []
for store in stores:
store_details.append(store.split('\n'))
df = pandas.DataFrame(store_details)
df2 = df.drop(df.columns[0],axis=1)
df3 = df2.drop(df.columns[1],axis=1)
df4 = df3.dropna()
df4[5] = df4[5].str.extract(r'\.(\d+)',expand=False)
new_names = ['Name','ID','Address','Distance']
df4 = df4.set_axis(new_names, axis=1)
return df4
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('zip_code',help = 'zip code to search')
args = argparser.parse_args()
zip_code = args.zip_code
scraped_data = locate_stores(zip_code)
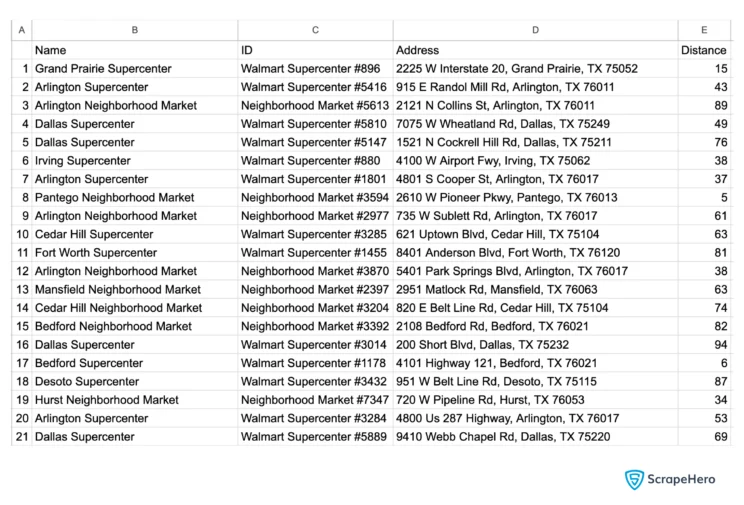
scraped_data.to_csv("walmart.csv")And here are the Walmart store locations.
Code Limitations
This code can go online and scrape Walmart store locations data for a specific zip code, but it has some limitations.
Walmart uses strict anti-scraping measures, and this code does not use advanced techniques like proxy rotation to get around them.
Therefore, the code needs tweaking for large-scale data extraction from Walmart.
Another issue is that XPaths depend on the site structure, so you must determine XPaths each time Walmart changes its structure.
Wrapping Up
You can scrape Walmart store data using Python Selenium, but you must watch Walmart.com for any changes in its HTML code. And whenever that happens, you must analyze their webpage again and figure out the new XPaths.
If you want to avoid zip coding yourself, try ScrapeHero. ScrapeHero can help you in two ways.
You can use our no-code ScrapeHero Walmart Scraper from ScrapeHero Cloud. It is a prebuilt, affordable web scraper you can try for free. With just a few clicks, you can get the Walmart location data as JSON, or CSV.
You can also use ScrapeHero services if you want large-scale data extraction. We are an enterprise-grade web scraping service provider capable of building custom web scrapers. You only have to mention the data specifications; we will cover everything else.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



