
If you want reliable tourist data, Tripadvisor is a great resource. However, copying data manually can be a real hassle, which is where Tripadvisor scraping comes in. Here’s how to scrape Tripadvisor using Python.
Tripadvisor Scraping: Setting Up Your Environment
You’ll need two key Python libraries for Tripadvisor data scraping:
-
- Selenium: To control the browser and perform actions like clicking buttons.
- lxml: To parse HTML and locate the data points
- requests: To handle HTTP requests
Just use Python’s pip to install these packages.
pip install selenium lxml requestsNow, that you have everything set up, you’re ready to plan your scraper. And the first step is to know what you’ll scrape.
Tripadvisor Scraping: Data Scraped
The scraper pulls six data points from Tripadvisor:
- Rank
- Hotel Name
- Price
- URL
- Review Count
- Tripadvisor Rating
You’ll spot the HTML tags holding this data by using your browser’s inspect feature.
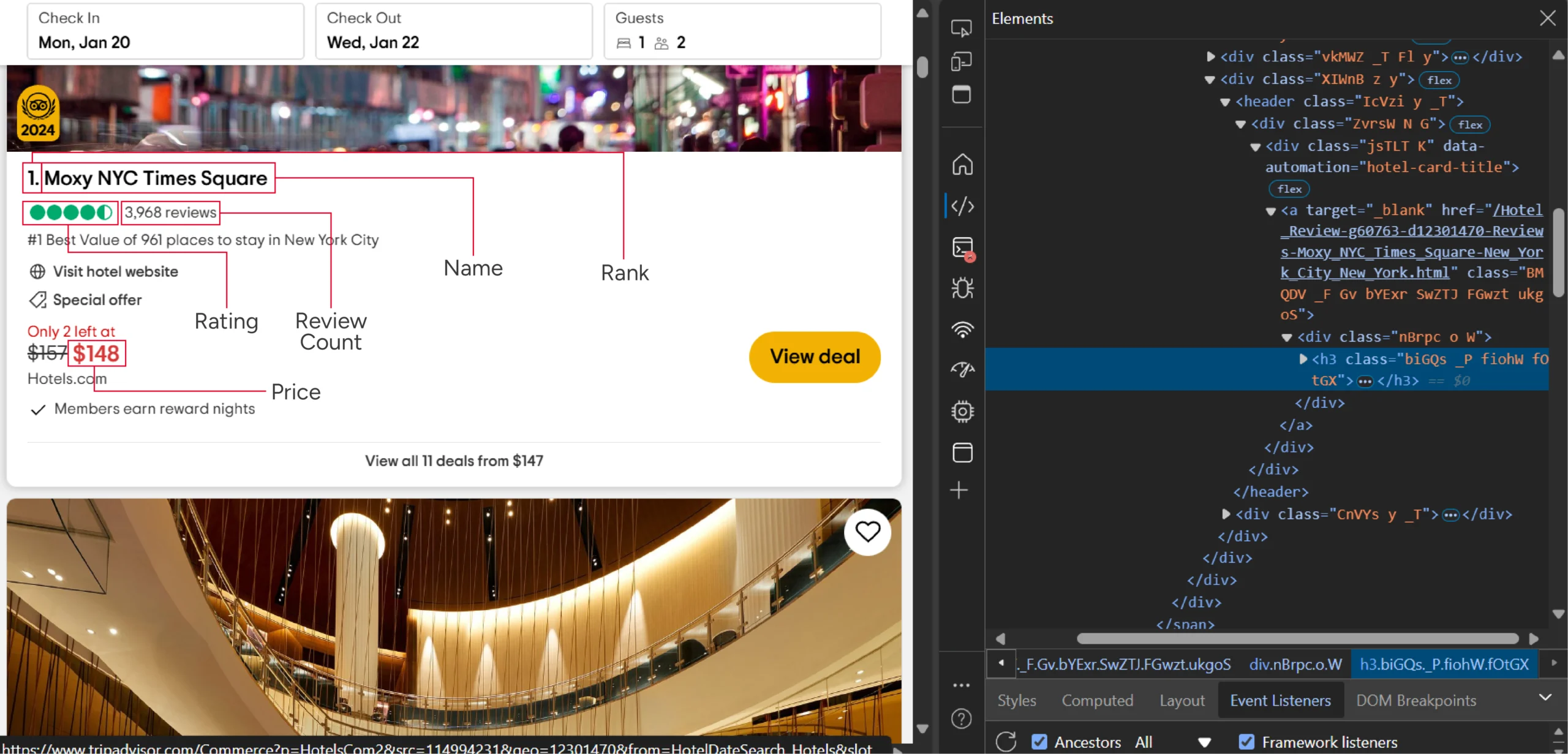
By using the ‘Inspect’ feature you can build XPaths. If you don’t know how to do that, here’s a nice XPath cheat sheet that’ll get you going.
Here you’ll need the following XPaths:
- URL: ‘.//div[@data-automation=”hotel-card-title”]//a/@href’
- Review Count: ‘.//span/span[contains(text(),”reviews”)]//text()’
- Rating: ‘.//div[contains(@aria-label,”reviews”)]/@aria-label’
- Name: ‘.//div[@data-automation=”hotel-card-title”]//h3/text()’
- Price: ‘.//span[contains(@data-automation,”Price”)]/text()’
There’s no need for an XPath for getting the rank as you can get it from the hotel name.
After understanding the XPaths, you can start coding.

Tripadvisor Scraping: Building The Scraper
Start by importing the modules you need:
- time: to get the current time
- sleep: to pause script execution
- unicodecsv: to write the extracted data into a CSV file
- argparse: to create a command-line interface (CLI) for your script
- datetime: to change date formats
- selenium.webdriver: to control the browser
- selenium.webdriver.common.by: to specify the selectors for finding elements
from time import time, sleep
import json
import argparse, requests
from datetime import datetime
from lxml import html
from selenium import webdriver
from selenium.webdriver.common.by import ByNext, organize the code by breaking it down into functions, This code uses three key functions:
- get_json(): Gets the URL for the list of hotels of a particular location
- get_response(): Pulls the HTML source code of the page holding the hotel list
- parse(): calls the above two functions and extracts the data points
get_json()
First, you’ll need to grab the appropriate Tripadvisor URL for a given locality; you can get that from the site’s Content API. This API returns a JSON containing the required URL. So the get_json() function:
- Takes the API endpoint URL as input
- Makes an HTTP request to this URL using Python requests
- Parses the response
- Returns the JSON data
def get_json(url):
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers, verify=False)
json_data = json.loads(response.text)
with open("geo_url.json", "w") as f:
json.dump(json_data, f, indent=4)
return json_dataget_response()
The get_response() function fetches the HTML source code of a URL. This function:
- Accepts a URL
- Launches the Selenium browser
- Navigates to the URL
- Extracts and returns the HTML source code
def get_response(url,checkin,checkout):
driver = webdriver.Chrome()
driver.get(url)
sleep(3)
checkin = checkin.strftime('%B %d, %Y')
checkout = checkout.strftime('%B %d, %Y')
driver.find_element(By.XPATH,'//div[contains(@data-automation,"checkin")]')
sleep(1)
while True:
try:
driver.find_element(By.XPATH, f'//div[contains(@aria-label,"{checkin}")]').click()
break
except:
driver.find_element(By.XPATH, '//button[contains(@aria-label,"Next month")]').click()
sleep(1)
sleep(2)
while True:
try:
driver.find_element(By.XPATH, f'//div[contains(@aria-label,"{checkout}")]').click()
break
except:
driver.find_element(By.XPATH, '//button[contains(@aria-label,"Next month")]').click()
sleep(1)
sleep(10)
response = driver.page_source
with open("page.scraped.html", "w", encoding="utf-8") as f:
f.write(response)
return responseYou can see that the code sets the check-in and check-out dates before grabbing the HTML source code. This is necessary or the page won’t load the hotel prices.
The function uses a loop to find the correct dates and select them. Then, it downloads the HTML after the page loads the new hotel list that includes the prices
parse()
This function integrates the above functions. It accepts a locality, and:
- Constructs a URL using the locality
- Calls get_json() with the constructed endpoint
- Forms the required URL from the returned JSON data
- Calls get_response() with the URL
- Parses the returned HTML source code using lxml
- Locates all the span elements that hold the hotel details
- Loops through the span elements
- Locates the required data using the XPaths mentioned previously.
- Appends the data to a list
- Returns the list
def parse(locality, checkin_date, checkout_date):
print("Scraper Inititated for Locality:%s" % locality)
# TA rendering the autocomplete list using this API
print("Finding search result page URL")
geo_url = "https://www.tripadvisor.com/TypeAheadJson?action=API&startTime="+ str(int(time()))+ "&uiOrigin=GEOSCOPE&source=GEOSCOPE&interleaved=true&types=geo,theme_park&neighborhood_geos=true&link_type=hotel&details=true&max=12&injectNeighborhoods=true&query="+ locality
print(geo_url)
api_response = get_json(geo_url)
# getting the TA url for th equery from the autocomplete response
url_from_autocomplete = (
"http://www.tripadvisor.com" + api_response["results"][0]["url"]
)
print("URL found %s" % url_from_autocomplete)
print("Downloading search results page")
page_response = get_response(url_from_autocomplete,checkin_date,checkout_date)
print("Parsing results ")
parser = html.fromstring(page_response)
hotel_lists = parser.xpath('//span[@class="organic"]')
hotel_data = []
for hotel in hotel_lists:
XPATH_HOTEL_LINK = './/div[@data-automation="hotel-card-title"]//a/@href'
XPATH_REVIEWS = './/span/span[contains(text(),"reviews")]//text()'
XPATH_RATING = './/div[contains(@aria-label,"reviews")]/@aria-label'
XPATH_HOTEL_NAME = './/div[@data-automation="hotel-card-title"]//h3/text()'
XPATH_HOTEL_PRICE = './/span[contains(@data-automation,"Price")]/text()'
raw_hotel_link = hotel.xpath(XPATH_HOTEL_LINK)
raw_no_of_reviews = hotel.xpath(XPATH_REVIEWS)
raw_rating = hotel.xpath(XPATH_RATING)
raw_hotel_name = hotel.xpath(XPATH_HOTEL_NAME)
raw_hotel_price = hotel.xpath(XPATH_HOTEL_PRICE)
url = 'http://www.tripadvisor.com'+raw_hotel_link[0] if raw_hotel_link else None
reviews = raw_no_of_reviews[0].replace("reviews","").replace(",","").strip() if raw_no_of_reviews else 0
rank = raw_hotel_name[0].split('.')[0].strip() if raw_hotel_name else None
rating = raw_rating[0].replace('of 5 bubbles','').split()[0].strip() if raw_rating else None
name = raw_hotel_name[0].split('.')[1].strip() if raw_hotel_name else None
price = raw_hotel_price[0] if raw_hotel_price else 'Not Available'
data = {
'rank':rank,
'hotel_name':name,
'price':price,
'url':url,
'review count':reviews,
'tripadvisor_rating':rating,
}
hotel_data.append(data)
return hotel_dataNow, it’s time to call these functions.
Since the script will ask the user for location, check-in date, and check-out date when it runs, set up a command-line interface (CLI) using argparse. This lets users easily interact with the script through the terminal:
- Initialize the ArgumentParser() object
- Add argument for locality, check-in date, and check-out date
- Parse the arguments and store them in a variable
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('checkin_date',help = 'Hotel Check In Date (Format: YYYY/MM/DD')
parser.add_argument('checkout_date',help = 'Hotel Chek Out Date (Format: YYYY/MM/DD)')
parser.add_argument("locality", help="Search Locality")
args = parser.parse_args()
locality = args.locality
checkin_date = datetime.strptime(args.checkin_date,"%Y/%m/%d")
checkout_date = datetime.strptime(args.checkout_date,"%Y/%m/%d")You can then call parse() with the locality, checkin_date, and checkout_date as the arguments.
data = parse(locality, checkin_date, checkout_date)Finally, save the data as a JSON file.
with open("tripadvisor_data.json", "w",encoding='utf-8') as jsonfile:
json.dump(data,jsonfile,indent=4,ensure_ascii=False)The results of scraping Tripadvisor will look like this.
{
"rank": "1",
"hotel_name": "Moxy NYC Times Square",
"price": "$335",
"url": "http://www.tripadvisor.com/Hotel_Review-g60763-d12301470-Reviews-Moxy_NYC_Times_Square-New_York_City_New_York.html",
"review count": "3968",
"tripadvisor_rating": "4.5"
}Here’s the complete code to scrape Tripadvisor:
#!/usr/bin/env python
from time import time, sleep
import json
import argparse, requests
from datetime import datetime
from lxml import html
from selenium import webdriver
from selenium.webdriver.common.by import By
def get_response(url,checkin,checkout):
driver = webdriver.Chrome()
driver.get(url)
sleep(3)
checkin = checkin.strftime('%B %d, %Y')
checkout = checkout.strftime('%B %d, %Y')
driver.find_element(By.XPATH,'//div[contains(@data-automation,"checkin")]')
sleep(1)
while True:
try:
driver.find_element(By.XPATH, f'//div[contains(@aria-label,"{checkin}")]').click()
break
except:
driver.find_element(By.XPATH, '//button[contains(@aria-label,"Next month")]').click()
sleep(1)
sleep(2)
while True:
try:
driver.find_element(By.XPATH, f'//div[contains(@aria-label,"{checkout}")]').click()
break
except:
driver.find_element(By.XPATH, '//button[contains(@aria-label,"Next month")]').click()
sleep(1)
sleep(10)
response = driver.page_source
with open("page.scraped.html", "w", encoding="utf-8") as f:
f.write(response)
return response
def get_json(url):
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers, verify=False)
json_data = json.loads(response.text)
with open("geo_url.json", "w") as f:
json.dump(json_data, f, indent=4)
return json_data
def parse(locality, checkin_date, checkout_date):
print("Scraper Inititated for Locality:%s" % locality)
# TA rendering the autocomplete list using this API
print("Finding search result page URL")
geo_url = "https://www.tripadvisor.com/TypeAheadJson?action=API&startTime="+ str(int(time()))+ "&uiOrigin=GEOSCOPE&source=GEOSCOPE&interleaved=true&types=geo,theme_park&neighborhood_geos=true&link_type=hotel&details=true&max=12&injectNeighborhoods=true&query="+ locality
print(geo_url)
api_response = get_json(geo_url)
# getting the TA url for th equery from the autocomplete response
url_from_autocomplete = (
"http://www.tripadvisor.com" + api_response["results"][0]["url"]
)
print("URL found %s" % url_from_autocomplete)
print("Downloading search results page")
page_response = get_response(url_from_autocomplete,checkin_date,checkout_date)
print("Parsing results ")
parser = html.fromstring(page_response)
hotel_lists = parser.xpath('//span[@class="organic"]')
hotel_data = []
for hotel in hotel_lists:
XPATH_HOTEL_LINK = './/div[@data-automation="hotel-card-title"]//a/@href'
XPATH_REVIEWS = './/span/span[contains(text(),"reviews")]//text()'
XPATH_RATING = './/div[contains(@aria-label,"reviews")]/@aria-label'
XPATH_HOTEL_NAME = './/div[@data-automation="hotel-card-title"]//h3/text()'
XPATH_HOTEL_PRICE = './/span[contains(@data-automation,"Price")]/text()'
raw_hotel_link = hotel.xpath(XPATH_HOTEL_LINK)
raw_no_of_reviews = hotel.xpath(XPATH_REVIEWS)
raw_rating = hotel.xpath(XPATH_RATING)
raw_hotel_name = hotel.xpath(XPATH_HOTEL_NAME)
raw_hotel_price = hotel.xpath(XPATH_HOTEL_PRICE)
url = 'http://www.tripadvisor.com'+raw_hotel_link[0] if raw_hotel_link else None
reviews = raw_no_of_reviews[0].replace("reviews","").replace(",","").strip() if raw_no_of_reviews else 0
rank = raw_hotel_name[0].split('.')[0].strip() if raw_hotel_name else None
rating = raw_rating[0].replace('of 5 bubbles','').split()[0].strip() if raw_rating else None
name = raw_hotel_name[0].split('.')[1].strip() if raw_hotel_name else None
price = raw_hotel_price[0] if raw_hotel_price else 'Not Available'
data = {
'rank':rank,
'hotel_name':name,
'price':price,
'url':url,
'review count':reviews,
'tripadvisor_rating':rating,
}
hotel_data.append(data)
return hotel_data
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('checkin_date',help = 'Hotel Check In Date (Format: YYYY/MM/DD')
parser.add_argument('checkout_date',help = 'Hotel Chek Out Date (Format: YYYY/MM/DD)')
parser.add_argument("locality", help="Search Locality")
args = parser.parse_args()
locality = args.locality
checkin_date = datetime.strptime(args.checkin_date,"%Y/%m/%d")
checkout_date = datetime.strptime(args.checkout_date,"%Y/%m/%d")
data = parse(locality, checkin_date, checkout_date)
print('extracted data',data)
print("Writing to output file tripadvisor_data.json")
with open("tripadvisor_data.json", "w",encoding='utf-8') as jsonfile:
json.dump(data,jsonfile,indent=4,ensure_ascii=False)
Using the Code
To use this code, copy and paste it into a file with a ‘.py’ extension, then run it from a terminal.
python yourpythoncode.py 2025/05/15 2025/05/20 bostonThe code above scrapes details of hotels in Boston for a check-in date of January 15, 2025, and a check-out date of January 20, 2025
Code Limitations
The code can grab hotel details of a particular locality from Tripadvisor, but it has some limitations:
- The code relies on the API endpoint. If that changes, the code will break.
- It locates data points using XPaths, which relies on HTML structure; the code will fail if the structure changes.
- This scraper doesn’t use any advanced techniques to avoid anti-scraping measures, so it is unsuitable for large-scale scraping.
- The code won’t work for all the pages; you need to alter it to scrape other travel, airline, and hotel data from Tripadvisor.
Want to Get Tripadvisor Reviews Instead? Use ScrapeHero Tripadvisor Scraper
ScrapeHero Tripadvisor Ratings and Review Scraper is a no-code scraper from ScrapeHero Cloud. Within a few clicks, you can get ratings and reviews from any hotel’s page.
Try for free:
- Log in or sign up for a ScrapeHero Cloud account
- Create a Project and Add details
- Enter the Tripadvisor URLs from which you want to scrape data
- Click ‘Gather data’
Wait for the scraper to finish, and you can get the downloaded data from the ‘My Projects’ section.
Advanced Features
Besides giving you a no-code way to get Tripadvisor reviews, you can also
- Schedule your scraper to run and pull reviews periodically.
- Get the reviews delivered to your preferred cloud storage.
- Integrate this review scraper with your workflow using APIs.
Bottom Line
You can scrape Tripadvisor using the code shown in this tutorial. However, you need to maintain the code yourself; this includes replacing the API endpoint and altering the XPaths. Moreover, you need to alter the code if you intend to perform scraping on a large scale.
But with a web scraping service, you can avoid coding yourself. A service like ScrapeHero can take care of all the technicalities, including dealing with anti-scraping measures.
ScrapeHero is a fully-managed web scraping service capable of building enterprise-grade scrapers customized to your needs. Contact ScrapeHero now and get all your data needs covered.



