

This article outlines methods for scraping Tripadvisor reviews. This process effectively exports Tripadvisor review data to Excel or other formats for easier access and use.
There are three methods to scrape Tripadvisor reviews:
- Scrape Tripadvisor reviews with coding: Building a web scraper in Python or JavaScript
- Scrape Tripadvisor reviews without coding: Using the ScrapeHero Cloud’s Tripadvisor Reviews Scraper, a no-code scraping tool
ScrapeHero Cloud offers you ready-made web crawlers and real-time APIs, which are the easiest way to extract data from websites and download it into spreadsheets with a few clicks.

Building a Tripadvisor Reviews Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Tripadvisor reviews using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One key advantage of this approach is its ability to bypass standard blocks to prevent scraping. However, familiarity with the Playwright API is necessary for practical use.
You could also use Python Requests, LXML, or BeautifulSoup to build a Tripadvisor reviews scraper without using a browser or a browser automation library. However, bypassing the anti-scraping mechanisms can be challenging and is beyond the scope of this article.
Here are the steps to scrape Tripadvisor review data using Playwright:
Step 1: Choose either Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
JavaScript
npm install playwright
Python
pip install playwright
# to download the necessary browsers
playwright installStep 3: Write your code to emulate browser behavior and extract the review data from Tripadvisor using the Playwright API. You can use the code provided below:
JavaScript
const playwright = require('playwright');
const fs = require('fs');
(async () => {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
const url = "https://www.tripadvisor.com/Hotel_Review-g1234567-d123456-Reviews-Hotel_Name.html";
await page.goto(url);
const reviews = await page.evaluate(() => {
return Array.from(document.querySelectorAll('div[data-reviewid]')).map(review => {
const username = review.querySelector('div.info_text div')?.textContent.trim();
const ratingClass = review.querySelector('span.ui_bubble_rating')?.className;
const rating = ratingClass ? parseInt(ratingClass.split('_').pop()) / 10 : null;
const title = review.querySelector('a.title')?.textContent.trim();
const reviewText = review.querySelector('q.IRsGHoPm span')?.textContent.trim();
return { username, rating, title, reviewText };
});
});
fs.writeFileSync('tripadvisor_reviews.json', JSON.stringify(reviews, null, 2));
console.log('Reviews saved to tripadvisor_reviews.json');
await browser.close();
})();Python
import requests
from lxml import html
import json
def clean(text):
return text.strip() if text else ''
def parse_reviews(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
parser = html.fromstring(response.content)
reviews = []
for review in parser.xpath('//div[@data-reviewid]'):
username = clean(review.xpath('.//div[@class="info_text"]/div/text()')[0])
rating = clean(review.xpath('.//span[contains(@class, "ui_bubble_rating")]/@class')[0])
rating = int(rating.split('_')[-1]) // 10
title = clean(review.xpath('.//a[@class="title"]/text()')[0])
review_text = clean(review.xpath('.//q[@class="IRsGHoPm"]/span/text()')[0])
reviews.append({
'username': username,
'rating': rating,
'title': title,
'review_text': review_text
})
return reviews
if __name__ == '__main__':
url = "https://www.tripadvisor.com/Hotel_Review-g1234567-d123456-Reviews-Hotel_Name.html"
reviews = parse_reviews(url)
print(json.dumps(reviews, indent=2))This code shows how to scrape Tripadvisor reviews from Google using the Playwright library in Python and JavaScript. The scripts have two main functions:
- run function: This function initializes a browser instance using Playwright and navigates to the specified Tripadvisor page. It waits for the reviews to load and calls the extract_data function to collect and store data in a JSON file.
- extract_data function: This function takes a Playwright page object and extracts review details. The extracted details include username, rating, title, and review text for each review.
Finally, the main function uses the async Playwright context manager to execute the run function. A JSON file, tripadvisor_reviews.json, will be created containing the scraped Tripadvisor reviews.
Step 4: Run your code and collect the scraped data from Tripadvisor.
Disclaimer: The XPath selectors used in this tutorial may vary depending on the layout or version of the Tripadvisor website. Ensure that the provided selectors match the structure of the page you are accessing.
Using No-Code Tripadvisor Reviews Scraper by ScrapeHero Cloud
The Tripadvisor reviews scraper by ScrapeHero Cloud is a convenient method for scraping reviews from Google. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the Tripadvisor reviews scraper.
1. Sign up or log in to your ScrapeHero Cloud account.
2. Go to the Tripadvisor reviews scraper by ScrapeHero Cloud in the marketplace.
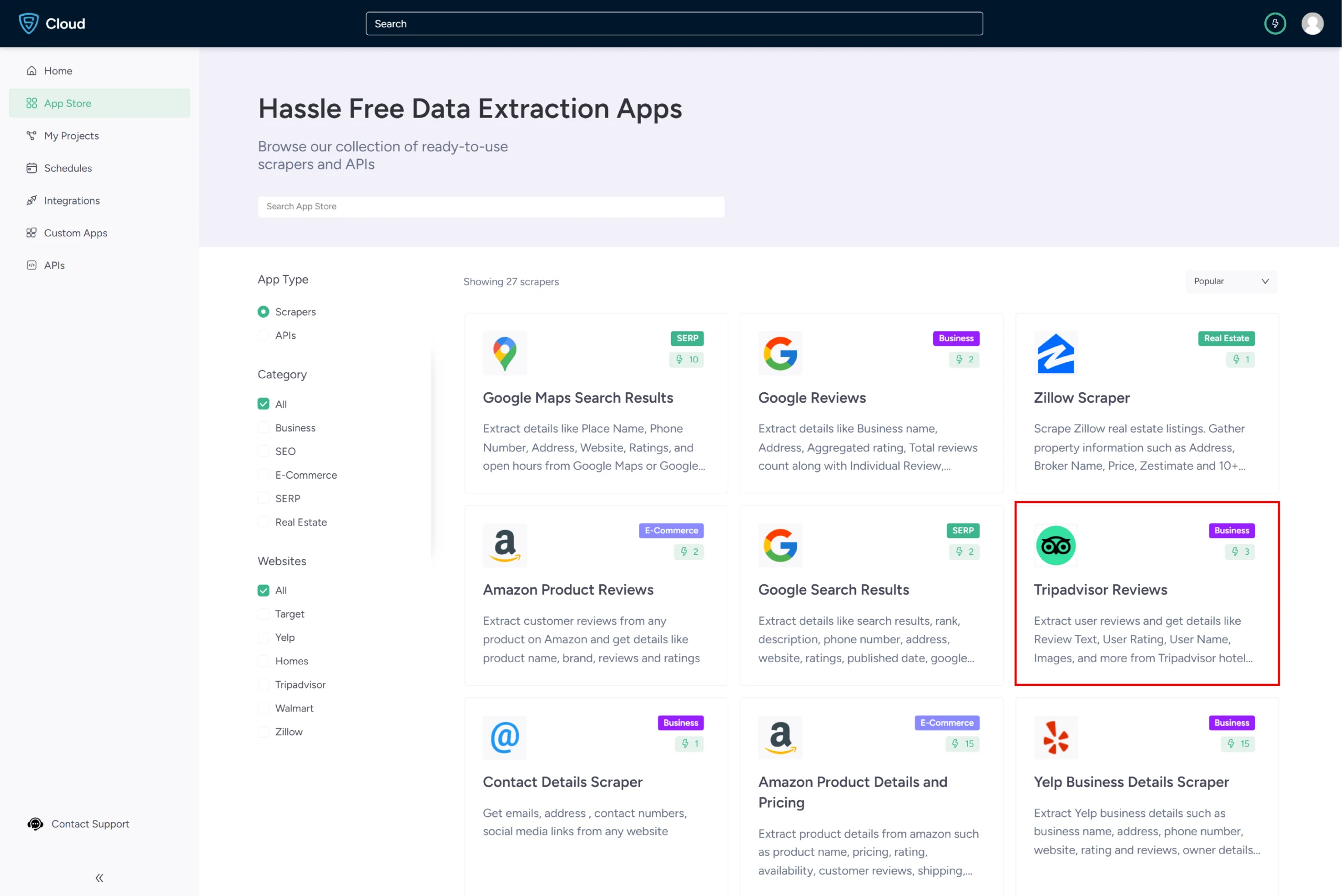
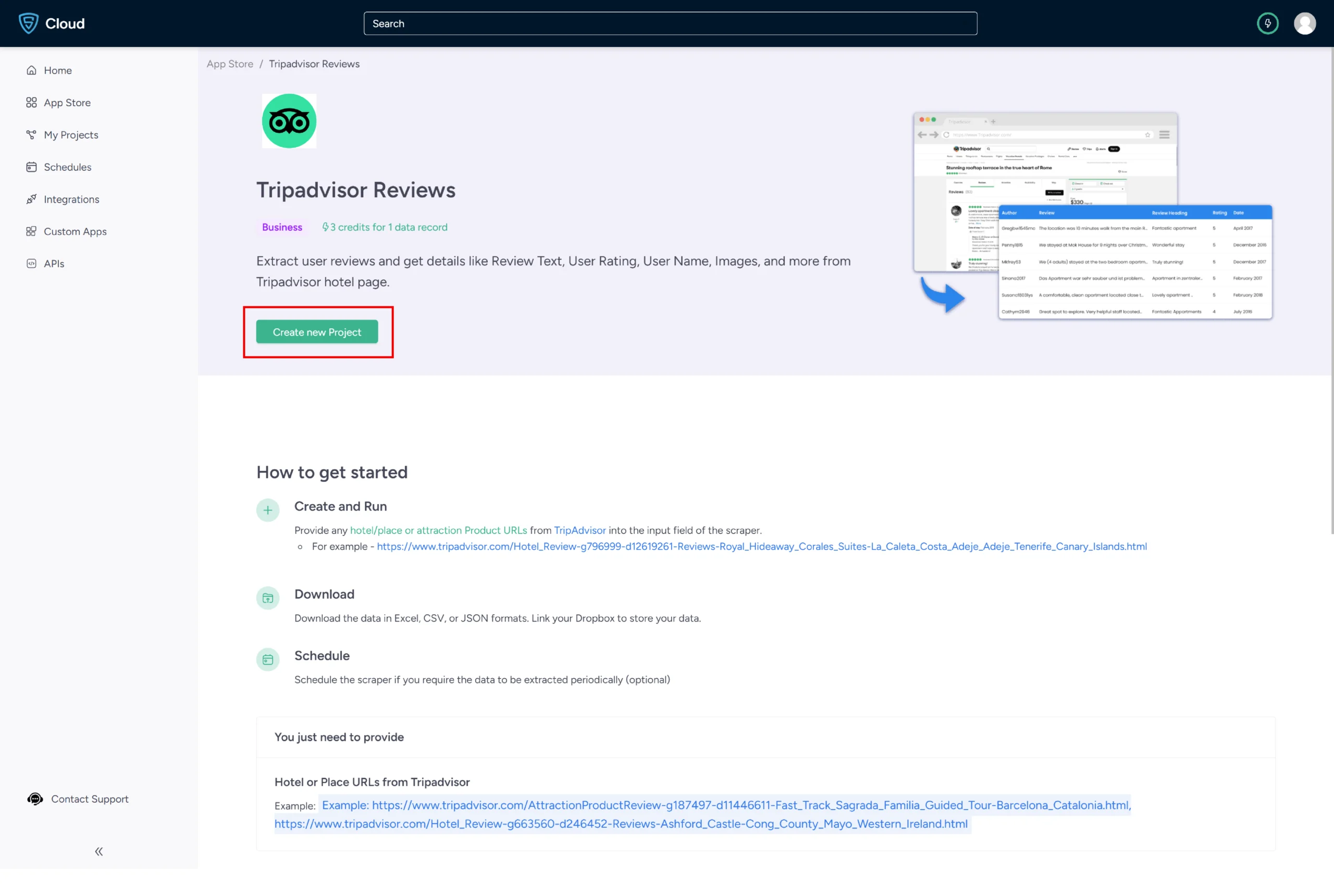
3. Click the Create New Project button.
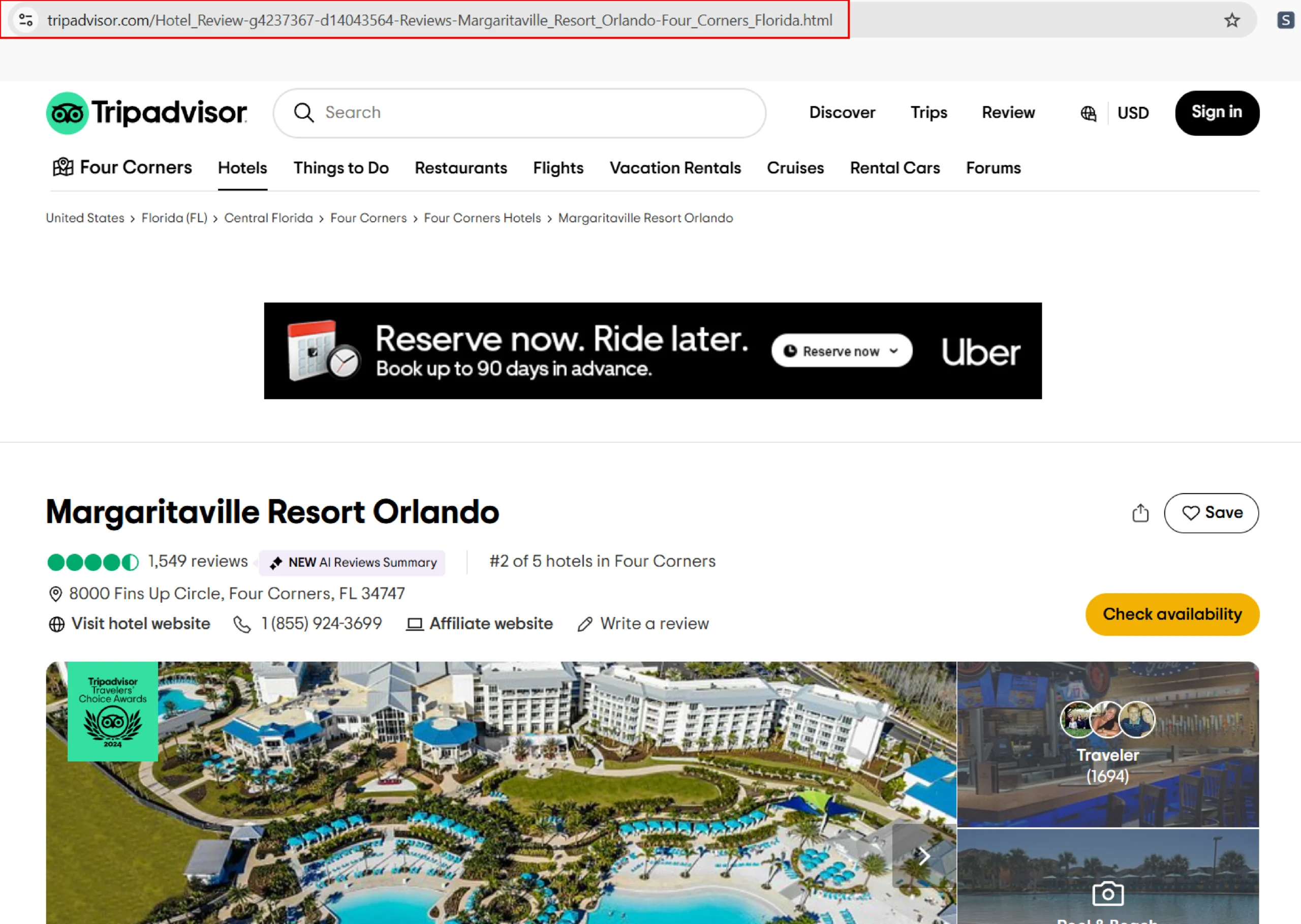
4. To get the reviews, you need to provide a Tripadvisor review URL. You can get the Tripadvisor review URL from the search bar when you search for a query.
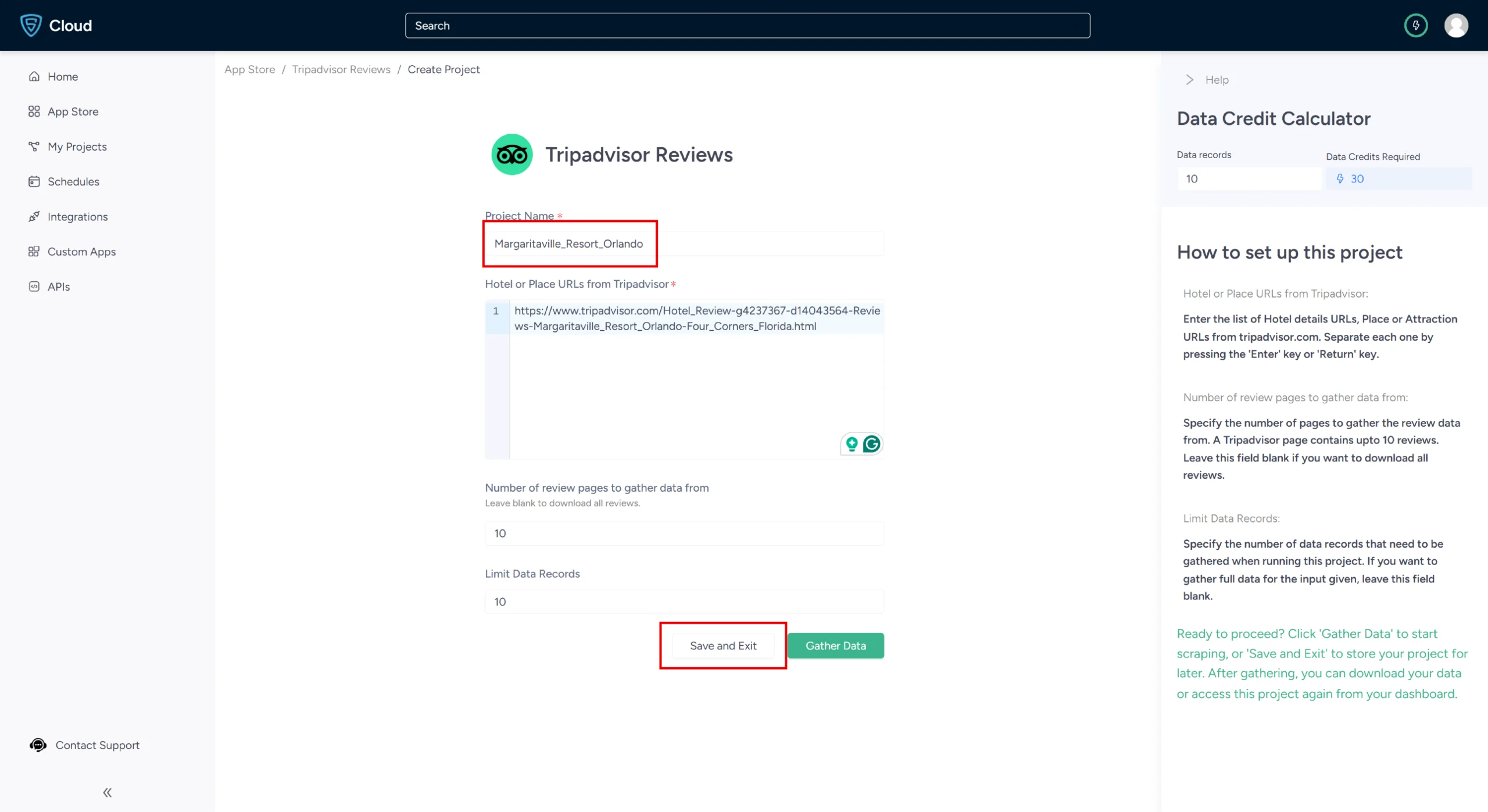
5. In the field provided, enter a project name, Tripadvisor review URL, the maximum number of records and review pages you want to gather. Then, click the Gather Data button to start the scraper.
6. The scraper will start fetching data for your queries, and you can track its progress under the Projects tab.
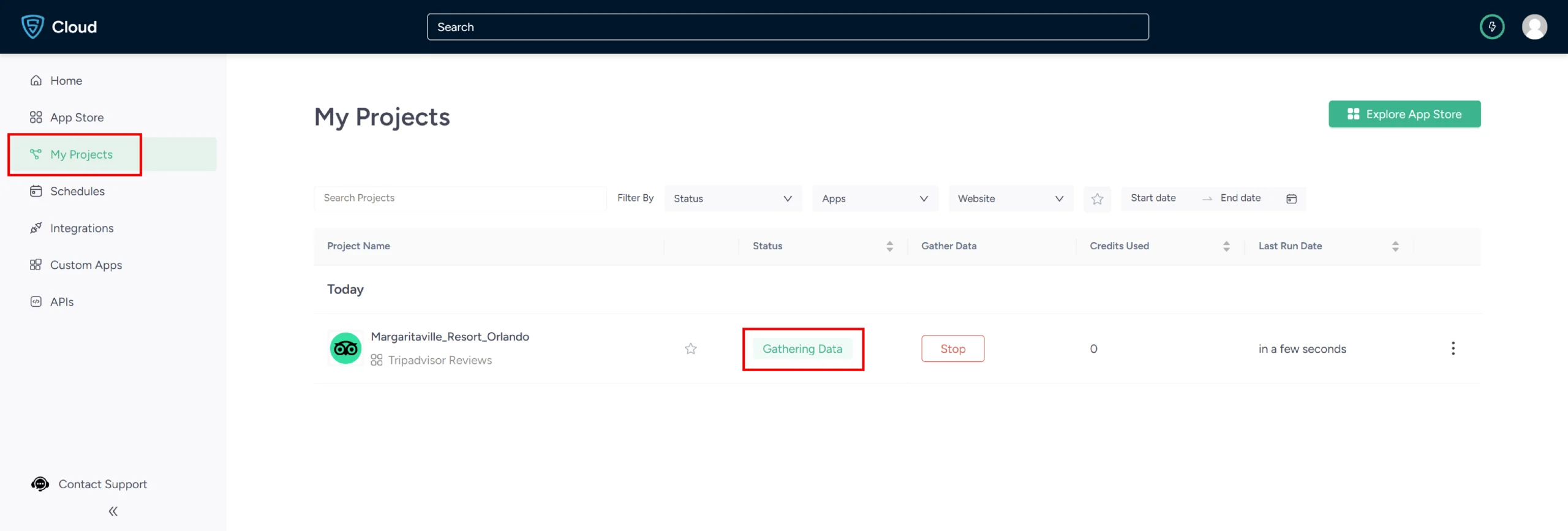
7. Once it is finished, you can view the data by clicking on the project name. A new page will appear, and under the Overview tab, you can see and download the data.

8. You can also pull Tripadvisor reviews data into a spreadsheet from here. Just click on Download Data, select Excel, and open the downloaded file using Microsoft Excel.
Use Cases of Tripadvisor Reviews Data
If you’re unsure why you should scrape reviews from Tripadvisor, here are some use cases where this data would be helpful:
-
Customer Sentiment Analysis
Organizations can analyze customer sentiments and opinions to identify areas of satisfaction and dissatisfaction, helping improve services and customer experiences.
-
Competitor Analysis
By examining competitors’ Tripadvisor reviews, businesses can identify gaps in the market and opportunities to differentiate themselves.
-
Business Strategy
Customer feedback from Tripadvisor reviews highlights strengths to capitalize on and weaknesses to address, aiding in long-term strategic planning.
-
Market Trends
Tripadvisor reviews can reveal market trends and preferences, enabling businesses to stay ahead of the curve.
Frequently Asked Questions
You can easily scrape Tripadvisor review data in bulk using ScrapeHero Tripadvisor review scraper.
To scrape Tripadvisor in Python, use libraries like BeautifulSoup and requests, ensuring compliance with their terms of service.
ScrapeHero provides a comprehensive pricing plan for both Scrapers and APIs. To know more about the pricing, visit our pricing page.
The legality of web scraping depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.



