
Extract search rank, product name, ASIN, pricing, and more in Real-Time by searching a specific keyword, ASIN, GTIN, ISBN, or product name from the Amazon search results page.
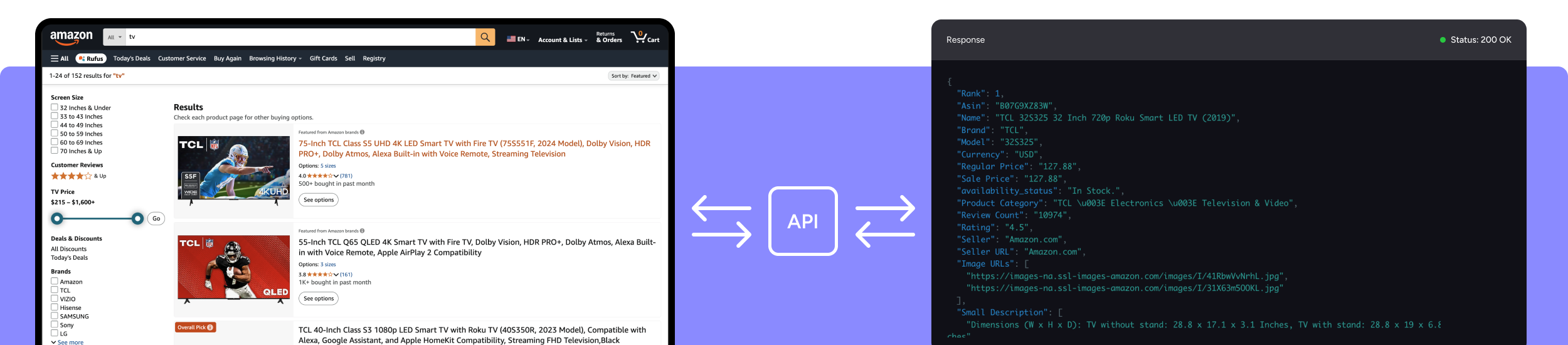
{
"query": {
"domain": "com",
"country_code": "US",
"keyword": "smart watches",
"page": 1
},
"search_results": [
{
"name": "Smart Watch Fitness Tracker,Body Temperature Monitor Blood pressure measurement Bluetooth Smartwatch Touchscreen Wrist Watch, Fitness Tracker with Camera Pedometer for Android iPhone iOS for Men Women",
"sale_price": "35.97",
"regular_price": null,
"currency": "USD",
"asin": "B0881MDMKH",
"review_count": "50",
"rating": "4.8",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/610OZ+klgjL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Temperature-measurement-Bluetooth-Smartwatch-Touchscreen/dp/B0881MDMKH/ref=sr_1_1_sspa?dchild=1",
"rank": "1",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Smart Watch Sport Smart Watch Fitness Tracker for Android and iOS Phone Activity Tracker with 1.3\" Full Touch Screen, Camera Music Control IP68 Waterproof Smartwatch,Ultra-Long Battery Life, Grey",
"sale_price": "45.99",
"regular_price": null,
"currency": "USD",
"asin": "B08735Q7LS",
"review_count": "10",
"rating": "3.8",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/71aQX7aryWL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Fitness-Activity-Waterproof-Smartwatch-Ultra-Long/dp/B08735Q7LS/ref=sr_1_2_sspa?dchild=1",
"rank": "2",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "YAMAY Smart Watch for Android and iOS Phone IP68 Waterproof, Fitness Tracker Watch with Heart Rate Monitor Step Sleep Tracker, Smartwatch Compatible with iPhone Samsung, Watch for Men Women",
"sale_price": "40.99",
"regular_price": null,
"currency": "USD",
"asin": "B07SK1SF81",
"review_count": "5,872",
"rating": "4.1",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/61VQOaRpwWL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/YAMAY-Waterproof-Pedometer-Smartwatch-Compatible/dp/B07SK1SF81/ref=sr_1_3?dchild=1&qid=1594196578&sr=8-3",
"rank": "3",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "LETSCOM Smart Watch Fitness Tracker Heart Rate Monitor Step Calorie Counter Sleep Monitor Music Control IP68 Water Resistant 1.3\" Color Touch Screen Activity Tracking Pedometer for Women Men",
"sale_price": "35.99",
"regular_price": null,
"currency": "USD",
"asin": "B085VRQHFR",
"review_count": "429",
"rating": "4.2",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/61sjThBRuOL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/LETSCOM-Resistant-Activity-Tracking-Pedometer/dp/B085VRQHFR/ref=sr_1_4?dchild=1&qid=1594196578&sr=8-4",
"rank": "4",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Samsung Galaxy Watch smartwatch (46mm, GPS, Bluetooth) – Silver/Black (US Version with Warranty)",
"sale_price": "239.00",
"regular_price": "269.99",
"currency": "USD",
"asin": "B07FTKJCMT",
"review_count": "6,163",
"rating": "4.4",
"badge": "Best Seller",
"image_url": "https://m.media-amazon.com/images/I/81ZKNYBwYlL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Samsung-Galaxy-Silver-Bluetooth-SM-R800NZSAXAR/dp/B07FTKJCMT/ref=sr_1_5?dchild=1&qid=1594196578&sr=8-5",
"rank": "5",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Fossil Gen 5 Carlyle Stainless Steel Touchscreen Smartwatch with Speaker, Heart Rate, GPS, NFC, and Smartphone Notifications",
"sale_price": "295.00",
"regular_price": null,
"currency": "USD",
"asin": "B07SRVV8V4",
"review_count": "2,935",
"rating": "4.2",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/71XWG48C-NL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Fossil-Carlyle-Stainless-Touchscreen-Smartwatch/dp/B07SRVV8V4/ref=sr_1_6?dchild=1&qid=1594196578&sr=8-6",
"rank": "6",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Smart Watch Sport Smart Watch Fitness Tracker for Android and iOS Phone Activity Tracker with 1.3\" Full Touch Screen, Camera Music Control IP68 Waterproof Smartwatch,Ultra-Long Battery Life, Red",
"sale_price": "43.99",
"regular_price": null,
"currency": "USD",
"asin": "B0878TKXHW",
"review_count": "3",
"rating": "5.0",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/71FIr5H7KiL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Fitness-Activity-Waterproof-Smartwatch-Ultra-Long/dp/B0878TKXHW/ref=sr_1_7_sspa?dchild=1",
"rank": "7",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Garmin vívoactive 3, GPS Smartwatch Contactless Payments Built-In Sports Apps, Black/Slate",
"sale_price": "152.59",
"regular_price": "279.99",
"currency": "USD",
"asin": "B074K9HNXD",
"review_count": "6,832",
"rating": "4.3",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/51E19y80s1L._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/vívoactive-inteligente-Smartwatch-Estándar-pulgadas/dp/B074K9HNXD/ref=sr_1_8?dchild=1&qid=1594196578&sr=8-8",
"rank": "8",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "YAMAY Smart Watch 2020 Ver. Watches for Men Women Fitness Tracker Blood Pressure Monitor Blood Oxygen Meter Heart Rate Monitor IP68 Waterproof, Smartwatch Compatible with iPhone Samsung Android Phones",
"sale_price": "48.99",
"regular_price": "69.99",
"currency": "USD",
"asin": "B0855JDXGD",
"review_count": "453",
"rating": "4.3",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/51g0J2ZLH1L._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/YAMAY-Pressure-Waterproof-Smartwatch-Compatible/dp/B0855JDXGD/ref=sr_1_9?dchild=1&qid=1594196578&sr=8-9",
"rank": "9",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Fitbit Versa 2 Health and Fitness Smartwatch with Heart Rate, Music, Alexa Built-In, Sleep and Swim Tracking, Bordeaux/Copper Rose, One Size (S and L Bands Included)",
"sale_price": "198.95",
"regular_price": null,
"currency": "USD",
"asin": "B07TWFWJDZ",
"review_count": "23,152",
"rating": "4.4",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/71jiGaztijL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Fitbit-Versa-Special-inteligente-seguimiento/dp/B07TWFWJDZ/ref=sr_1_10?dchild=1&qid=1594196578&sr=8-10",
"rank": "10",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Samsung Galaxy Watch Active2 W/ Enhanced Sleep Tracking Analysis, Auto Workout Tracking, and Pace Coaching (44mm, GPS, Bluetooth), Pink Gold - US Version with Warranty",
"sale_price": "249.00",
"regular_price": "299.99",
"currency": "USD",
"asin": "B07VKQ58ZF",
"review_count": "5,208",
"rating": "4.6",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/51QYH9ttqfL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Samsung-enhanced-tracking-analysis-coaching/dp/B07VKQ58ZF/ref=sr_1_11?dchild=1&qid=1594196578&sr=8-11",
"rank": "11",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "NiceFuse Smart Watch, Fitness Tracker Health Watch with Heart Rate Blood Oxygen Monitor, Multiple Sport Modes, Waterproof Activity Tracker Smartwatches with Sleep Monitor",
"sale_price": "55.99",
"regular_price": null,
"currency": "USD",
"asin": "B0847FBW4R",
"review_count": "175",
"rating": "4.1",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/41uBkd5rZVL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/NiceFuse-inteligente-frecuencia-deportivos-resistente/dp/B0847FBW4R/ref=sr_1_12_sspa?dchild=1",
"rank": "12",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "COULAX Smart Watch, 1.4\" Touch Screen Smartwatch, Fitness Tracker Step Counter, Activity Tracker with Heart Rate Monitor, IP68 Waterproof Sport Watch for Women and Men",
"sale_price": "49.99",
"regular_price": "52.99",
"currency": "USD",
"asin": "B0855QNMSQ",
"review_count": "304",
"rating": "4.2",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/71GpgnTRJ-L._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/COULAX-Smartwatch-Fitness-Activity-Waterproof/dp/B0855QNMSQ/ref=sr_1_13?dchild=1&qid=1594196578&sr=8-13",
"rank": "13",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Smart Watch, UMIDIGI UFit Fitness Tracker for Men Women with Blood Oxygen Meter Heart Rate Monitor Blood Pressure Monitor 5ATM Waterproof, Smartwatch for iPhone Android Phones",
"sale_price": "46.99",
"regular_price": null,
"currency": "USD",
"asin": "B085TM941M",
"review_count": "249",
"rating": "4.6",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/610jLK5gCaL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/UMIDIGI-Fitness-Pressure-Waterproof-Smartwatch/dp/B085TM941M/ref=sr_1_14?dchild=1&qid=1594196578&sr=8-14",
"rank": "14",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "AMATAGE Smart Watch for Men Android Phones iPhone, Fitness Tracker Watch with Heart Rate and Blood Pressure Monitor, Waterproof Activity Fitness Tracker with 23 Sport Modes, 1 Extra Band(Black)",
"sale_price": "54.69",
"regular_price": null,
"currency": "USD",
"asin": "B0892FC8CP",
"review_count": "21",
"rating": "4.7",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/61AcR-6vy3L._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/AMATAGE-Android-Pressure-Waterproof-Activity/dp/B0892FC8CP/ref=sr_1_15?dchild=1&qid=1594196578&sr=8-15",
"rank": "15",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Apple Watch Series 3 (GPS, 38mm) - Space Gray Aluminum Case with Black Sport Band",
"sale_price": "169.00",
"regular_price": "199.00",
"currency": "USD",
"asin": "B07K39FRSL",
"review_count": "15,758",
"rating": "4.8",
"badge": "Best Seller",
"image_url": "https://m.media-amazon.com/images/I/71fwbMm1NBL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Apple-Watch-GPS-38mm-Space-Aluminium/dp/B07K39FRSL/ref=sr_1_16?dchild=1&qid=1594196578&sr=8-16",
"rank": "16",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Kids Smart Watch for Boys Girls, Kids Smart Watches with Games SOS Call Camera Touch Screen LBS Tracker Kids Smartwatch, Smart Watches for Kids Compatible with iOS & Android",
"sale_price": "27.99",
"regular_price": null,
"currency": "USD",
"asin": "B08626BYX1",
"review_count": "14",
"rating": "4.5",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/61VSnG4aVSL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Watches-Tracker-Smartwatch-Compatible-Android/dp/B08626BYX1/ref=sr_1_17_sspa?dchild=1",
"rank": "17",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Letsfit Smart Watch, Fitness Tracker with Heart Rate Monitor, Activity Tracker with 1.3\" Touch Screen, IP68 Waterproof Pedometer Smartwatch with Sleep Monitor, Step Counter for Women and Men",
"sale_price": "35.99",
"regular_price": null,
"currency": "USD",
"asin": "B07X2KLTJ2",
"review_count": "7,055",
"rating": "4.3",
"badge": "Amazon's Choice",
"image_url": "https://m.media-amazon.com/images/I/61MNpaOq6GL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Letsfit-Activity-Waterproof-Pedometer-Smartwatch/dp/B07X2KLTJ2/ref=sr_1_18?dchild=1&qid=1594196578&sr=8-18",
"rank": "18",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Willful Smart Watch for Android Phones and iOS Phones Compatible iPhone Samsung, IP68 Swimming Waterproof Smartwatch Fitness Tracker Fitness Watch Heart Rate Monitor Smart Watches for Men Women Black",
"sale_price": "30.37",
"regular_price": "49.99",
"currency": "USD",
"asin": "B07YWRXVP6",
"review_count": "2,413",
"rating": "4.3",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/51oAPLRW9DL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Willful-Compatible-Swimming-Waterproof-Smartwatch/dp/B07YWRXVP6/ref=sr_1_19?dchild=1&qid=1594196578&sr=8-19",
"rank": "19",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "AMATAGE Smart Watch for Android Phones iPhone for Men Women, Fitness Tracker Watch with Heart Rate and Sleep Monitor, Waterproof Activity Tracker (Pink/Extra Band)",
"sale_price": "45.99",
"regular_price": null,
"currency": "USD",
"asin": "B085L2YXB1",
"review_count": "205",
"rating": "3.9",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/61ZArrgx5oL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/AMATAGE-Android-Fitness-Waterproof-Activity/dp/B085L2YXB1/ref=sr_1_20?dchild=1&qid=1594196578&sr=8-20",
"rank": "20",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Smart Watch for Android and iOS Phone 2020 Version Smartwatch IP68 Waterproof,Bluetooth Fitness Activity Tracker with Heart Rate Blood Pressure Monitor Step Sleep Tracker Message Reminder,Men Women",
"sale_price": "79.99",
"regular_price": null,
"currency": "USD",
"asin": "B0852J9CGX",
"review_count": "72",
"rating": "4.2",
"badge": null,
"image_url": "https://m.media-amazon.com/images/I/71S1QUaqfLL._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Smartwatch-Waterproof-Bluetooth-Activity-Pressure/dp/B0852J9CGX/ref=sr_1_21?dchild=1&qid=1594196578&sr=8-21",
"rank": "21",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
},
{
"name": "Timemaker Fitness Tracker with Heart Rate Monitor, Smart Bracelet, Activity Tracker Watch, Step Counter, Sleep Monitor, Calorie Counter, IP67 Waterproof Smart Watch for Android and iOS Smart Phones",
"sale_price": "33.99",
"regular_price": null,
"currency": "USD",
"asin": "B082CZBJG5",
"review_count": "4",
"rating": "4.4",
"badge": "Sponsored",
"image_url": "https://m.media-amazon.com/images/I/51y4bd4Ys3L._AC_UY218_.jpg",
"product_url": "https://www.amazon.com/Timemaker-Fitness-Bracelet-Activity-Waterproof/dp/B082CZBJG5/ref=sr_1_22_sspa?dchild=1",
"rank": "22",
"search_url": "https://www.amazon.com/s?k=smart+watches&page=1"
}
],
"next_page": "https://get.scrapehero.com/amz/keyword-search/?keyword=smart watches&domain=com&page=2"
}
You can get more product information such as best seller rank, category, images, product specification, and more by integrating with our Amazon Product Details and Pricing API.
{
"rating_histogram": {
"five_star": "81%",
"four_star": "8%",
"three_star": "4%",
"two_star": "2%",
"one_star": "5%"
},
"seller": "Adorama",
"availability_status": "In stock",
"shipping_charge": null,
"is_prime": false,
"author": null,
"asin": "B079Y45KTJ",
"name": "Canon EOS M50 Mirrorless Vlogging Camera Kit with EF-M 15-45mm lens, Black",
"brand": "Canon",
"price": "$499.00",
"regular_price": "$649.00",
"total_reviews": "597",
"average_rating": 4.6,
"color": "Black",
"model": "2680C011",
"is_aplus_page": true,
"parent_asin": "B07CK781NB",
"seller_url": "https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A17MC6HOH9AVE6",
"small_description": "Dual Pixel CMOS AF for fast, accurate autofocus that helps you get the photo you want right as the moment happens - 24.1 Megapixel APS C CMOS sensor and the DIGIC 8 Image Processor delivers incredible color, clear details, and stunning range - Vari angle Touchscreen LCD has a flexible tilt range ideal for high angle and low angle shooting, and reviewing your photos - Built in high resolution electronic viewfinder features approximately 2,360,000 dots to see high amounts of detail when capturing - Automatically transfer your files to your compatible device for easy backup and online uploading with automatic image transfer.Aspect Ratio:3:2 - Connect to the Camera Connect app to transfer images to your smart device, then share directly to various social sites or print directly to a compatible printer - EF M15 45 millimeter allows for high speed, high precision auto focusing with full time manual focus mode (AF+MF) to make adjustments after focusing",
"full_description": "Color: Black | Style: w/ EF-M15-45mm | Configuration: Base The EOS M50 is a compact interchangeable lens camera for aspiring photographers looking for an easy way to boost the quality of their photos and videos. With clear, high-resolution 4K UHD 24p video, you can capture the incredible details and cinematic moments of your life at home or wherever your adventures take you. Snap vibrant, eye-catching photos with a 24.1 Megapixel (APS-C) CMOS Sensor using the built-in Electronic Viewfinder or Vari-angle Touchscreen LCD.Thanks to the fast and improved Dual Pixel CMOS Autofocus system, you can quickly lock focus on your subject to make sure you don't miss the action. See how the EOS M50 can easily deliver the high-quality photos and videos you've always imagined.",
"images": [
"https://images-na.ssl-images-amazon.com/images/I/41TXEnmDBYL.jpg",
"https://images-na.ssl-images-amazon.com/images/I/81j0d8pNBFL._AC_SL1425_.jpg",
"https://images-na.ssl-images-amazon.com/images/I/51r1YbUWUmL.jpg",
"https://images-na.ssl-images-amazon.com/images/I/41eLksKzzoL.jpg",
"https://images-na.ssl-images-amazon.com/images/I/51a-IUwPteL.jpg",
"https://images-na.ssl-images-amazon.com/images/I/51-IS3qJd-L.jpg",
"https://images-na.ssl-images-amazon.com/images/I/51%2BbHrAMZ3L.jpg",
"https://images-na.ssl-images-amazon.com/images/I/51nlbA6ZL-L.jpg"
],
"video_count": 7,
"availability_quantity": "5",
"productCategory": "Electronics > Camera & Photo > Digital Cameras > Mirrorless Cameras",
"url": "https://www.amazon.com/dp/B079Y45KTJ?th=1&psc=1&pf_rd_i=desktop",
"attributes": "configuration: Base, color: Black, style: w/ EF-M15-45mm",
"size": null,
"available_book_formats": null,
"product_information": {
"Product Dimensions": "2.3 x 4.6 x 3.5 inches",
"Item Weight": "13.7 ounces",
"ASIN": "B079Y45KTJ",
"UNSPSC Code": "45121500",
"Item model number": "2680C011",
"Batteries": "1 Lithium ion batteries required.",
"Is Discontinued By Manufacturer": "No",
"Date First Available": "February 25, 2018",
"Manufacturer": "Canon",
"Amazon Best Sellers Rank": "#491 in Electronics , #1 in Mirrorless Cameras"
},
"variation_asin": [
{
"asin": "B07D7DVNZF",
"configuration": "w/ Mount Adapter",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07HMP3PXB",
"configuration": "w/ Premium Handmade Secure Camera Strap",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07CGWQ7NY",
"configuration": "w/ 32GB SDHC Memory Card",
"color_name": "Black",
"style_name": "Body Only"
},
{
"asin": "B079Y45KTJ",
"configuration": "Base",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07HMPS3B3",
"configuration": "w/ Premium Handmade Secure Camera Strap",
"color_name": "Black",
"style_name": "Body Only"
},
{
"asin": "B0101SRIKU",
"configuration": "Base",
"color_name": "Black",
"style_name": "Video Creator Kit"
},
{
"asin": "B07YBB3TZP",
"configuration": "w/ Storage bundle",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07CH6ZMTP",
"configuration": "w/ 32GB SDHC Memory Card",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm + EF-M 55-200mm"
},
{
"asin": "B079YCW48M",
"configuration": "Base",
"color_name": "White",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B079Y6T7T6",
"configuration": "Base",
"color_name": "Black",
"style_name": "Body Only"
},
{
"asin": "B07CH94W8S",
"configuration": "w/ 32GB SDHC Memory Card",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07CH8SJ1W",
"configuration": "w/ 32GB SDHC Memory Card",
"color_name": "White",
"style_name": "w/ EF-M15-45mm"
},
{
"asin": "B07HMK5X81",
"configuration": "w/ Premium Handmade Secure Camera Strap",
"color_name": "Black",
"style_name": "Video Creator Kit"
},
{
"asin": "B079Y5RNFC",
"configuration": "Base",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm + EF-M 55-200mm"
},
{
"asin": "B07HMVBDCT",
"configuration": "w/ Premium Handmade Secure Camera Strap",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm + EF-M 55-200mm"
},
{
"asin": "B07WR3FHC3",
"configuration": "Base",
"color_name": "Black",
"style_name": "w/ EF-M15-45mm + Stand"
},
{
"asin": "B07HMPRZ85",
"configuration": "w/ Premium Handmade Secure Camera Strap",
"color_name": "White",
"style_name": "w/ EF-M15-45mm"
}
],
"product_variations": {
"configuration": [
"Base",
"w/ Premium Handmade Secure Camera Strap",
"w/ Storage bundle",
"w/ 32GB SDHC Memory Card",
"w/ Mount Adapter"
],
"color_name": [
"Black",
"White"
],
"style_name": [
"Body Only",
"Video Creator Kit",
"w/ EF-M15-45mm",
"w/ EF-M15-45mm + EF-M 55-200mm",
"w/ EF-M15-45mm + Stand"
]
},
"product_condition": "new",
"frequently_bought_together": [
{
"title": "BM Premium 2-Pack of LP-E12 Batteries and USB Dual Battery Charger for Canon SX70 HS, Rebel SL1, EOS\u2026",
"link": "https://www.amazon.com/BM-Premium-Batteries-Battery-Mirrorless/dp/B01FV2A30S/ref=pd_bxgy_2/136-7167990-8898465?_encoding=UTF8&pd_rd_i=B01FV2A30S&pd_rd_r=63a7b2d2-57d5-475d-9cc6-145383f2ede5&pd_rd_w=CASBE&pd_rd_wg=eQaAJ&pf_rd_p=4e3f7fc3-00c8-46a6-a4db-8457e6319578&pf_rd_r=9YJPQ20BMTSMZ9Q4XEP6&psc=1&refRID=9YJPQ20BMTSMZ9Q4XEP6",
"price": "$24.99"
},
{
"title": "TAKSTAR SGC-598 Interview Microphone for Nikon/Canon Camera/DV Camcorder",
"link": "https://www.amazon.com/TAKSTAR-SGC-598-Interview-Microphone-Camcorder/dp/B00E58AA0I/ref=pd_bxgy_3/136-7167990-8898465?_encoding=UTF8&pd_rd_i=B00E58AA0I&pd_rd_r=63a7b2d2-57d5-475d-9cc6-145383f2ede5&pd_rd_w=CASBE&pd_rd_wg=eQaAJ&pf_rd_p=4e3f7fc3-00c8-46a6-a4db-8457e6319578&pf_rd_r=9YJPQ20BMTSMZ9Q4XEP6&psc=1&refRID=9YJPQ20BMTSMZ9Q4XEP6",
"price": "$32.00"
}
]
}
With just a few lines of code, you can integrate our API with your application and start receiving data as a JSON response.
import http.client
conn = http.client.HTTPSConnection("get.scrapehero.com")
conn.request("GET", "/amz/keyword-search/?x-api-key=XXXXXXXXXXXXXX&keyword=Sanitizer&country_code=US")
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
const http = require("https");
const options = {
"method": "GET",
"hostname": "get.scrapehero.com",
"port": null,
"path": "/amz/keyword-search/?x-api-key=XXXXXXXXXXXXXX&keyword=Sanitizer&country_code=US",
"headers": {}
};
const req = http.request(options, function (res) {
const chunks = [];
res.on("data", function (chunk) {
chunks.push(chunk);
});
res.on("end", function () {
const body = Buffer.concat(chunks);
console.log(body.toString());
});
});
req.end();
<?php
$curl = curl_init();
curl_setopt_array($curl, [
CURLOPT_URL => "https://get.scrapehero.com/amz/keyword-search/?x-api-key=XXXXXXXXXXXXXX&keyword=Sanitizer&country_code=US",
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => "",
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 30,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "GET",
]);
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err) {
echo "cURL Error #:" . $err;
} else {
echo $response;
}
HttpResponse<String> response = Unirest.get("https://get.scrapehero.com/amz/keyword-search/?x-api-key=XXXXXXXXXXXXXX&keyword=Sanitizer&country_code=US")
.asString();
require 'uri'
require 'net/http'
require 'openssl'
url = URI("https://get.scrapehero.com/amz/keyword-search/?x-api-key=XXXXXXXXXXXXXX&keyword=Sanitizer&country_code=US")
http = Net::HTTP.new(url.host, url.port)
http.use_ssl = true
http.verify_mode = OpenSSL::SSL::VERIFY_NONE
request = Net::HTTP::Get.new(url)
response = http.request(request)
puts response.read_body
We have a wide variety of Amazon scrapers and Real-Time APIs available in our Marketplace. You can use these web scraping tools to extract more data from Amazon.
Does not renew
Compare all features &
choose what works best for you
Need More?
Contact us for a custom plan based on your needs.
Join 12400+ customers who love working with ScrapeHero
A few mouse clicks and copy/paste is all that it takes!
The API returns highly structured JSON data in real-time within seconds.
Our robust infrastructure allows us to scale the API to meet your high volume demands easily.
You can easily integrate our APIs to your application and stream extracted data seamlessly.
We use the best residential proxies to route your requests to avoid IP bans and CAPTCHAs.
Can’t find what you’re looking for? Check out Cloud Support for assistance!
Sure, you can modify or cancel your plan at any time. Click on the Billing tab to change your plan.
If you cancel, you’ll be billed for the current month, but you won’t be charged again. If you have any page credits, you can still use our service until it reaches its limit.
Normally, it will take 3-5 business days to build a custom API endpoint. However, this may vary according to the complexity of the site and the proposed business logic.
No, we always provide the latest and most accurate data present on the website. However, you are free to cache the results in your systems to reduce API calls and costs.
Sure, we can build custom solutions for you. Please contact our Sales team using this link, and that will get us started. In your message, please describe in detail what you require.
All our data credit reset at the end of the billing period. Any unused credits do not carry over to the next billing period and also are nonrefundable. This is consistent with most software subscription services.
Contact us to schedule a brief, introductory call with our experts and learn how we can assist your needs.

Legal Disclaimer: ScrapeHero is an equal opportunity data service provider, a conduit, just like an ISP. We just gather data for our customers responsibly and sensibly. We do not store or resell data. We only provide the technologies and data pipes to scrape publicly available data. The mention of any company names, trademarks or data sets on our site does not imply we can or will scrape them. They are listed only as an illustration of the types of requests we get. Any code provided in our tutorials is for learning only, we are not responsible for how it is used.

