

Have you noticed that sometimes Python’s requests library gets you a different source code from the one you saw on a website? That is because some websites generate their HTML code via JavaScript at runtime. These are dynamic websites. In this tutorial, you will learn about web scraping dynamic web pages with Python.
What are Dynamic Websites?
Dynamic websites are those that generate HTML code during run-time, giving these sites a lot of flexibility. They can vary content based on visitor’s location, time, actions, etc.
E-commerce websites are examples of dynamic websites. They display information on their homepage based on various metrics, including supply and demand.
Advantages of dynamic websites include
- Personalized content display: The site can display information based on who logged in. E-commerce websites do this; they recommend products based on the user’s previous purchases.
- Quick site updates: As the site uses code to generate HTML, you only have to change the code to make site-wide changes.
Disadvantages of dynamic websites:
- Complex: You need to have advanced technical knowledge to build a dynamic website. For example, Angular, a popular framework for building dynamic websites, has a steep learning curve.
- Slow: Dynamic sites may be slower than static sites as they rely on processing information before displaying the HTML code.
Types of Dynamic Websites
Dynamic websites may use client-side and server-side scripting.
- Client-side scripts render JavaScript on the client’s browser to generate the HTML code. Your actions will trigger the JavaScript and update the HTML.
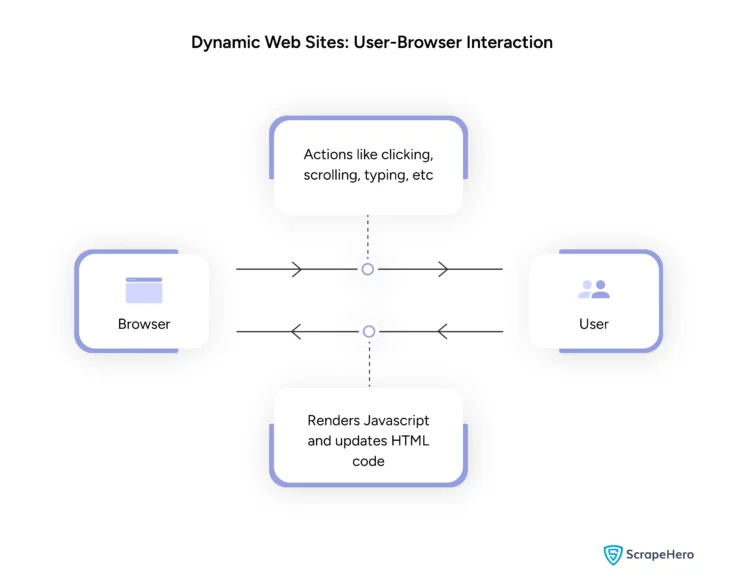
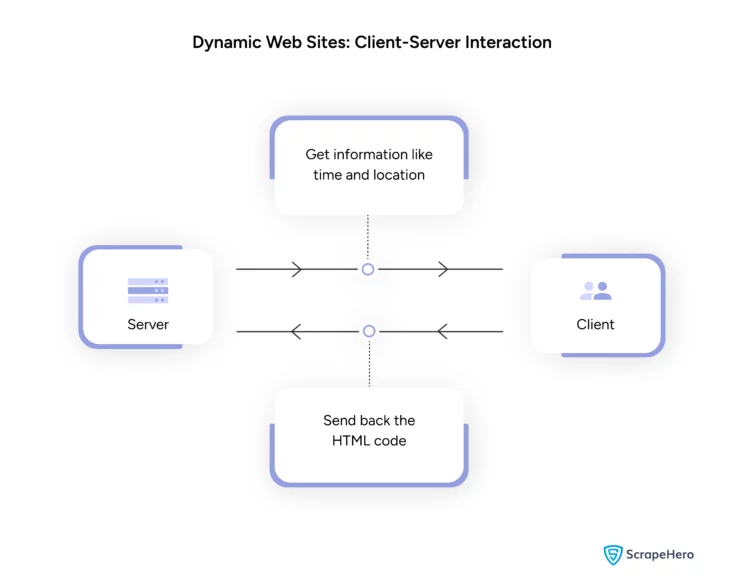
- The server-side scripting processes the information on the server and sends the HTML page back to the client. Besides JavaScript, the server may use languages such as PHP or Python.
Problems When Using Python Requests
This tutorial uses “https://angular.dev/docs” as the target for web scraping with Python. You can see a lot of content when you visit the website in the browser. However, if you use requests, you will receive a response with less content.
You can see why this happens if you go to the target page without enabling JavaScript.

Here is the same web page with JavaScript enabled
Thus, when you use requests to get the target webpage, it fetches the source code from the first scenario.
Install the packages required for Scraping Dynamic Websites
This tutorial uses two external packages for web scraping.
- BeautifulSoup
- Selenium
You can install them using Python pip.
pip install selenium beautifulsoupScraping Dynamic Web Pages with Python
You will use Selenium in this tutorial to render the dynamic web page. Selenium is a browser automation package available in JavaScript (Node.js), Python, Ruby, Java, Kotlin, and C#. However, this tutorial will show Python code to extract data using Selenium.
You then have two methods to get data from a dynamic website:
- Get the page sources using Selenium and then extract data using BeautifulSoup
- Extract data directly using Selenium methods.
Here is a flowchart showing how to scrape a dynamic website with Python.
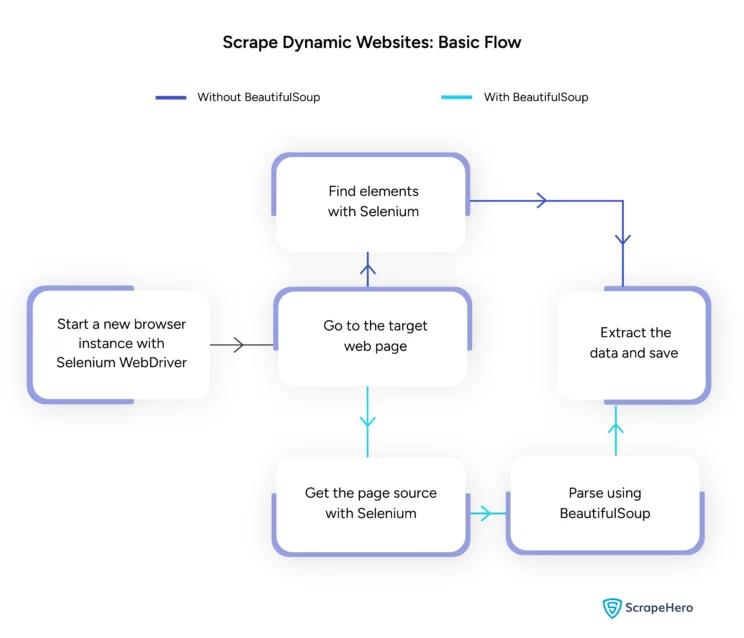
BeautifulSoup is more intuitive than using Selenium to extract data. However, you will see both methods in this tutorial.
The first step is to import the necessary modules for scraping dynamic web pages with Python.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas as pdNext, start a browser instance with Selenium; this will open up a Chrome browser.
browser = webdriver.Chrome()After that, go to the target site, “https://angular.dev/docs,” using the get() method.’
page = browser.get("https://angular.dev/docs")You can then find any element using the find_elements() method. Here, the code finds all the elements with the class “docs-card,” which are anchor tags.
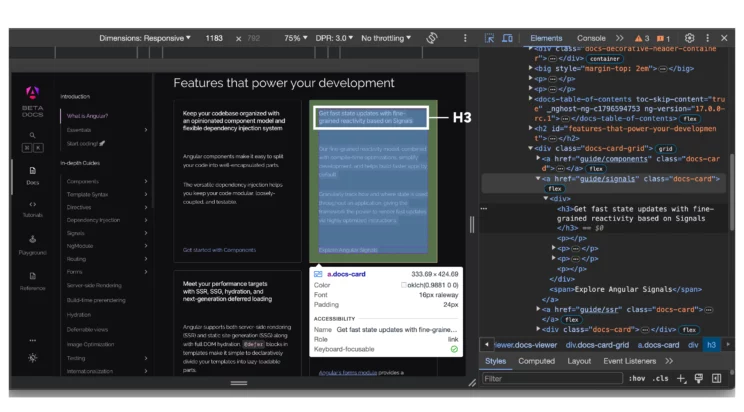
browser.implicitly_wait(10)
docs = browser.find_elements(By.CLASS_NAME,"docs-card")The implicitly_wait() method in the above code tells the browser to wait for certain seconds to load the page.
Each anchor tag with the class “docs-card” has several child elements. You can get these child elements by using the find_element() method on the parent element.
To get the href attribute, you can use the get_attribute() method.
file = []
for d in docs:
file.append([d.find_element(By.TAG_NAME,"h3").text,d.get_attribute("href")])The above code
- declares an empty list
- extracts the h3 tag and the link from each element in docs
- appends them to the list
Finally, you can save the file variable to a CSV file using Pandas.
df = pd.DataFrame(file,columns=["Docs","Links"])
df.to_csv("angular.csv",index=False)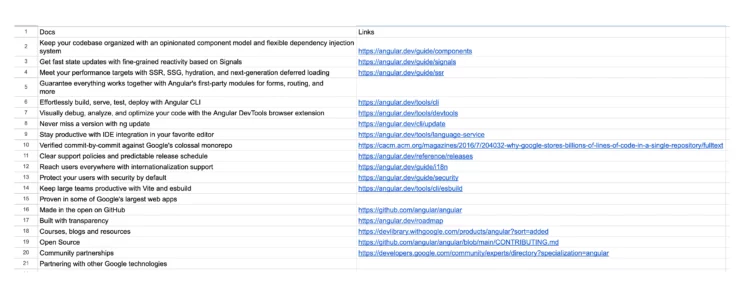
Element Extraction With BeautifulSoup
You can also use BeautifulSoup for scraping dynamic web pages with Python. However, you must get the page source using the page_source attribute.
source = browser.page_source
soup = BeautifulSoup(source,"html.parser")
docs = soup.select('a.docs-card')
newFile = []
for d in docs:
if 'https' in d['href']:
newFile.append([d.h3.string,d['href']])
else:
newFile.append([d.h3.string,"https://angular.dev/"+d['href']])
The above code snippet
- Gets the page source
- Passes the source to BeautifulSoup()
- Selects the anchor tag having the “docs-card” class
- Declares a variable newFile
- Appends newFile with the h3 heading and the corresponding link
Note: Some href values only have relative URLs. Therefore, you must check for “https”; if it is absent, add the base URL as a prefix.
You can then write newFIle to a CSV file as before.
How ScrapeHero Can Help
ScrapeHero is an enterprise-grade web scraping service provider. We have an excellent web crawling infrastructure capable of scraping millions of pages daily. And we can handle web scraping dynamic websites because of our massive browser farms.
How browser farms help dynamic web scraping
Dynamic web scraping requires full-fledged browsers. You need them to visit websites, render JavaScript, and extract data. However, performing the operation with a single browser constrains your productivity. Here, browser farms, an infrastructure capable of operating many browsers simultaneously, can be of immense help.
With browser farms, you can run several simultaneous instances of Selenium and scrape dynamic websites faster.
However, enterprise-grade browser farms demand enormous initial investment. You don’t need to worry about all that or learn how to scrape a dynamic website if you choose ScrapeHero. We will take care of everything. Our infrastructure can help you gather high-quality data for purposes such as product monitoring, brand monitoring, etc.
Wrapping Up
You can use Python for scraping dynamic web pages. Automated browsers like Selenium can help you do that. You can either use Selenium directly for extracting data or use BeautifulSoup to parse the source code obtained using Selenium.
For large-scale web scraping, you can use browser farms, but these require you to bear high initial costs. ScrapeHero services can help you with that. Our web scraping services include custom, large-scale web scraping and crawling solutions. You only need to pay according to your requirements.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



