
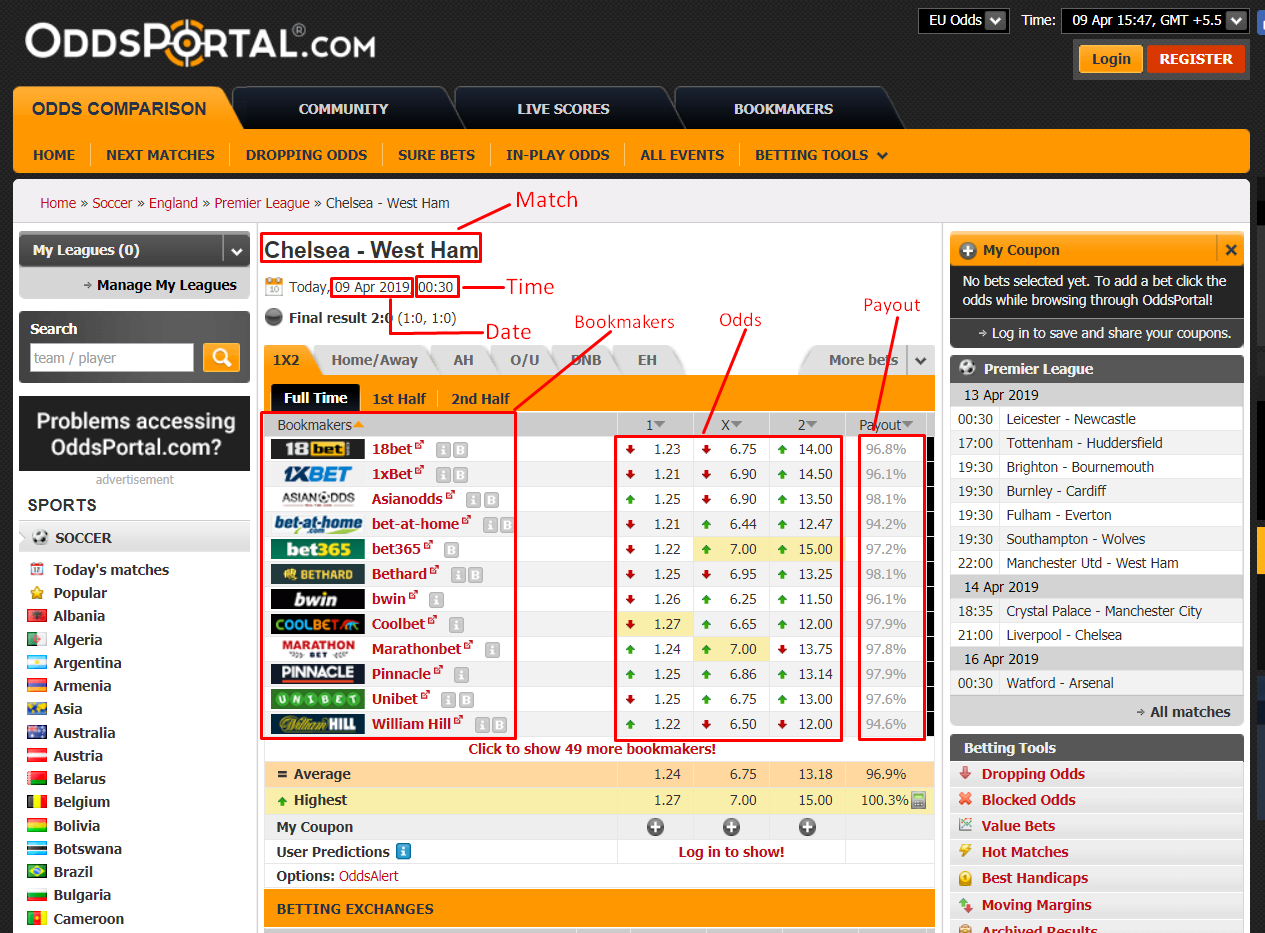
OddsPortal, a betting aggregator website which allows you to compare odds from multiple betting websites for a variety of sports. Using ScrapeHero Cloud, this tutorial will show you how to scrape OddsPortal for soccer betting odds from any soccer league in the world.
Web scraping betting websites will allow you to monitor odds offered by different websites and help make a more accurate decision for regular as well as peer-to-peer betting which is gaining popularity and is expected to be the future of gambling. This Oddsportal scraper will extract the match name, date and time, top bookmakers and the odds of a draw, home and away win for all matches in a particular league.
Here are the steps to scrape OddsPortal for soccer betting odds:
- Create a ScrapeHero Cloud account and select the OddsPortal Crawler.
- Input the OddsPortal URLs.
- Run the scraper and download the data (CSV, JSON, XML)

What data are we extracting?
For this tutorial we will scrape Oddsportal only for the following fields:
- Match
- Payout
- Date
- Bookmakers
- Time
- Home odds
- Draw odds
- Away odds
Read More – Learn to scrape Bet365 for betting odds
Step 1: Create an account
First, we will create an account in ScrapeHero Marketplace. To sign up go to the link – https://cloud.scrapehero.com/accounts/login/ and create an account with your email address.
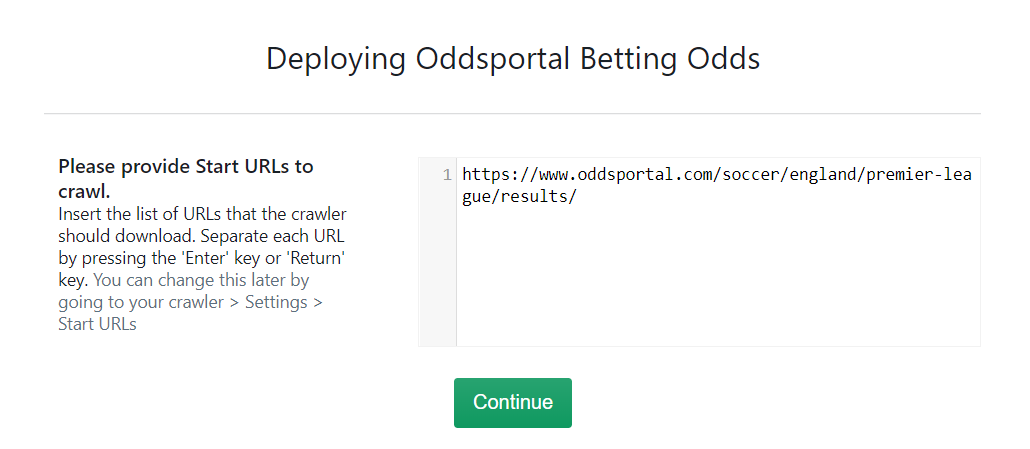
Step 2: Input the Details for the Oddportal Crawler
The only input needed for this crawler is the URL from the leagues available in OddsPortal. Here are steps to choose the sports and league you would like to scrape:
- Select the sport (Soccer). A list of countries will dropdown.
- Click on the country (England) and the league (Premier League) you want.
- A new tab will open with the list of matches along with their corresponding bookmakers and odds.
Ex: https://www.oddsportal.com/soccer/england/premier-league/watford-west-ham-0KCR68FT/
Copy this URL and paste it into the field for Start URLs. If you need to scrape more than one URL, you can add each new one separated by a new line. Then click on ‘Continue’.
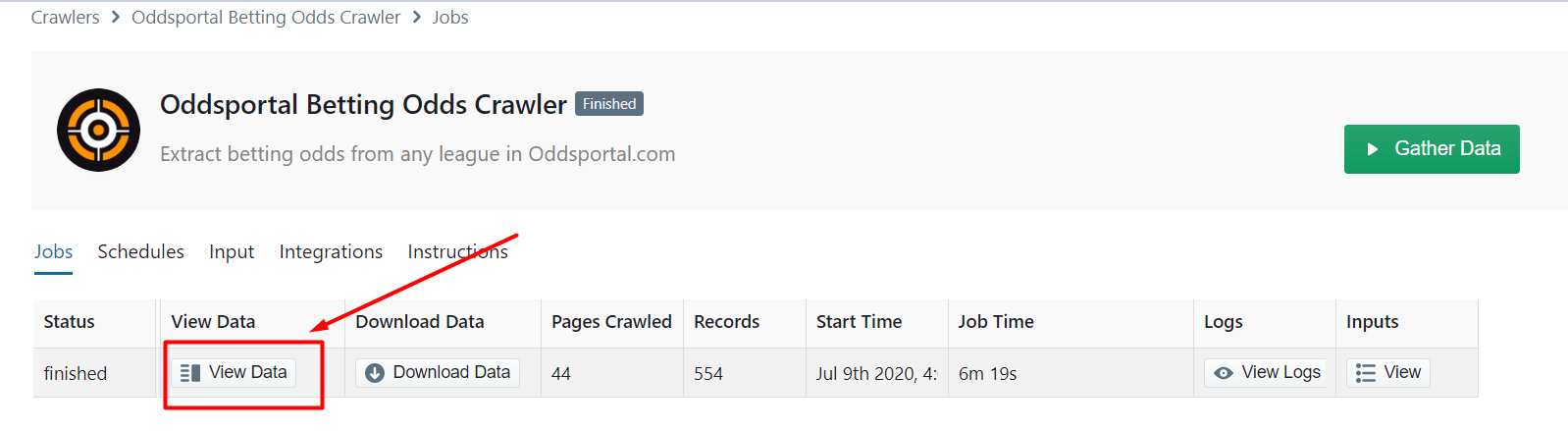
Step 3: Run the OddsPortal Scraper
The Oddportal crawler page will open up and you will see the option to ‘Gather Data’. Once you have clicked it the scraper will start to run

After the scrape is complete the ‘Status’ of the crawler will change from ‘Started’ to ‘Finished’. Click on ‘View Data’ to view the scraped data.
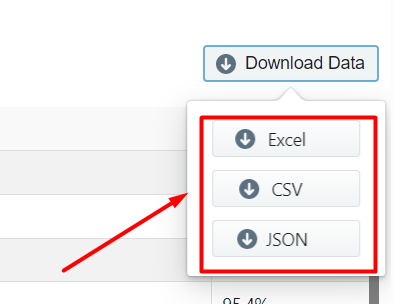
Step 4: Download the Data
You can see all the data scraped on this page. To download the scraped data click on ‘Download Data’.

A drop down to select a data format will appear. You can choose between CSV, JSON, and XML formats. After clicking on the data format option, a file will soon be downloaded with all the scraped OddPortal product data.
You can get data delivered to Dropbox if you integrate the crawler account to your Dropbox account. You also have the option to schedule the data if you want to extract product data on a timely basis.
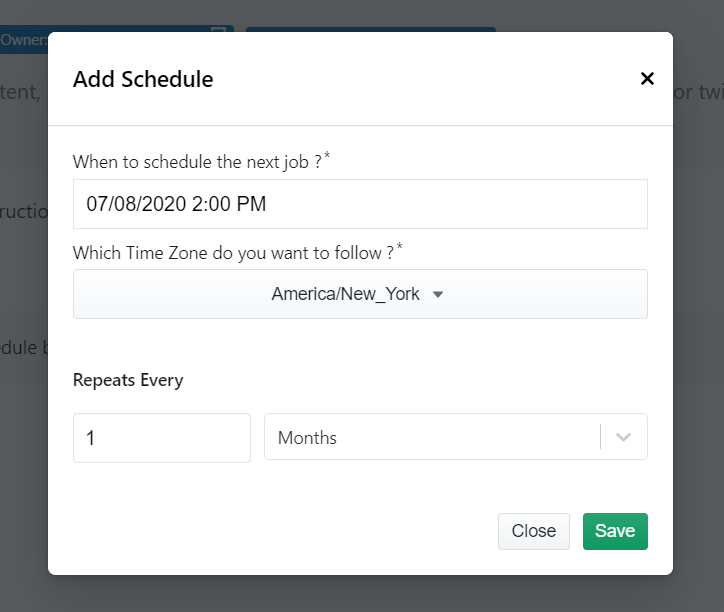
You can get data delivered to Dropbox if you integrate the crawler account to your Dropbox account. You also have the option to schedule the data if you want to extract product data on a timely basis.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



