

Google Tag Manager (GTM) has a data layer that stores information before passing it to the GTM container. You can scrape this GTM data. However, scraping data from Google Tag Manager requires you to execute JavaScript, which HTTP requests can’t do.
Therefore, you need browser automation libraries like Selenium Python. Selenium has methods to execute JavaScript and get the information.
Here is an image showing an example of a data layer variable.
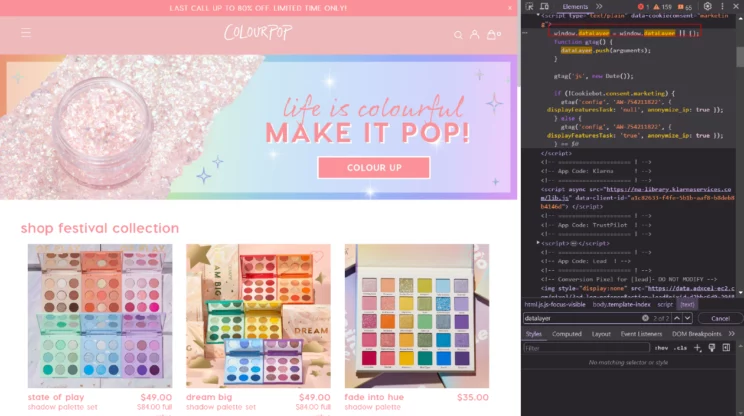
How the Data Layer in Google Tag Manager Works
The data layer in Google Tag Manager gets information when a script executes. For example, consider a data layer definition.
The website will add information to this object using the dataLayer.push() command.
<script>
window.dataLayer = window.dataLayer || [];
</script>
The website will add information to this object using the dataLayer.push() command.
<a href="#" onclick="dataLayer.push({
'category': 'article',
'title': 'Google Tag Manager',
'author': 'Author1'
});">Article details<</a>Whenever a user clicks on the above link, the data layer will get the information. The script will execute, and it will push the defined key-value pairs to the data layer variable.
Reasons to Scrape Data From the Data Layer
Scraping the data layer can provide insights into your competitor’s marketing strategy:
- You can see what your competitors track on their website.
- You can know the tools they use, as GTM supports a variety of tools for analysis.
- The variables and events can tell how they interact with the customers.
This information can give you ideas on how to tweak your marketing strategies. You may also get inspired to develop new strategies that outsmart your competitors.
How to use Python for Scraping Data From Google Tag Manager
It is a bit more challenging to scrape data from Google Tag Manager in Python than Node, as the data layer gets information through JavaScript. However, you can use Selenium, a Python library for browser automation; it can render JavaScript and extract the information from the data layer.
Set Up the Environment
You must install Selenium because it’s an external library. Python’s package manager, pip, can install Selenium.
You also need Pandas to write to a CSV file. The code will write the scraped data into a JSON file; however, it’ll write the errors into a CSV file. That’s why you need Pandas.
The code for Scraping Data From Google Tag Manager

You’ll start by importing the necessary libraries and modules.
Here, you import webdriver, Keys, and By modules from Selenium separately for convenience. Moreover, you import
- re, for regular expressions
- json, for JSON files
- pandas, for CSV files
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas
import re
import json
The code scrapes the data layer of several eCommerce websites listed on Webinopoly.com. Therefore, the first step is to visit that website and get the links.
driver = webdriver.Chrome()
driver.get("https://webinopoly.com/blogs/news/top-100-most-successful-shopify-stores")
a = driver.find_elements(By.XPATH,"//tr/td/a")
The above code uses the find_elements method of Selenium and locates the link elements using XPaths. Finding XPaths can be challenging; you must analyze the HTML code and figure it out for each website.
The next step is to visit the sites listed on the website and extract the information from the data layer.
There might be errors while scraping from the data layer; therefore, you’ll use try-except blocks.
for url in a[:10]:
try:
newDriver = webdriver.Chrome()
newDriver.get(url.get_attribute("href"))
html = newDriver.find_element(By.TAG_NAME,"html")
html.send_keys(Keys.END)
data_layer = newDriver.execute_script("return window.dataLayer")
print(url.get_attribute("href"))
print(data_layer)
fileNname = url.get_attribute("href")
filename = re.search(r'://(.*?)\.com', fileNname)
print(filename.group(1))
with open(filename.group(1), 'w') as file:
json.dump(data_layer, file, indent=2)
newDriver.quit()
The code iterates through 10 link elements and tries to
- Extract URLs from the element. You can use the get_attribute() method on the element to extract the URLs.
- Execute a script and get the data layer. The execute_script() method allows you to execute JavaScript.
- Save as a JSON file. You can use json.dump() to save the extracted information to a JSON file.
NOTE: The function uses regular expressions to get the domain name without “https://” and use it as the name for each JSON file.
If there are any errors, the code will push them into a scraping_errors variable, creating a list.
except Exception as e:
errors.append([{e},url])
newDriver.quit()
You’ll then save this list as a CSV file. DataFrame() converts scraping_errors into a Pandas DataFrame, and to_csv writes the variable into a CSV file.
df = pandas.DataFrame(errors)
df.to_csv("errors.csv")
driver.quit()
Here is the full code for scraping the data layer of Google Tag Manager.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pandas
import re
import json
driver = webdriver.Chrome()
driver.get("https://webinopoly.com/blogs/news/top-100-most-successful-shopify-stores")
a = driver.find_elements(By.XPATH,"//tr/td/a")
errors=[]
for url in a[:10]:
try:
newDriver = webdriver.Chrome()
newDriver.get(url.get_attribute("href"))
html = newDriver.find_element(By.TAG_NAME,"html")
html.send_keys(Keys.END)
data_layer = newDriver.execute_script("return window.dataLayer")
print(url.get_attribute("href"))
print(data_layer)
fileNname = url.get_attribute("href")
filename = re.search(r'://(.*?)\.com', fileNname)
print(filename.group(1))
with open(filename.group(1), 'w') as file:
json.dump(data_layer, file, indent=2)
newDriver.quit()
except Exception as e:
errors.append([{e},url])
newDriver.quit()
df = pandas.DataFrame(errors)
df.to_csv("errors.csv")
driver.quit()
Here is the information scraped from the data layer of colourpop.com.
[
[
"js",
{
"getTimeAlias": {}
}
],
[
"config",
"G-WSYJCRME4P",
{
"send_page_view": false
}
],
[
"event",
"page_view",
{
"page_location": "https://colourpop.com/",
"page_path": "/",
"page_title": "ColourPop Cosmetics",
"send_to": "G-WSYJCRME4P"
}
],
[
"set",
"developer_id.dMWZhNz",
true
],
{
"event": "gtm.dom",
"gtm.uniqueEventId": 9
},
{
"event": "gtm.load",
"gtm.uniqueEventId": 10
}
]
Code Limitations
While the above code allows you to scrape the data layer using Python, it may have certain limitations.
This code assumes that the name of the data layer object is dataLayer. However, the web page may use a custom name, and the code won’t work in that case. In such situations, you must figure out the name of the data layer by analyzing the website.
The code is also vulnerable to measures restricting web scraping; it does not include strategies, like proxy rotation, that can help you scrape without getting blocked. Therefore, you can’t pull data from the data layer on a large scale using this code.
Wrapping Up
It’s possible to extract details from the data layer of GTM using Python. The information can provide you with insights into your competitor’s tracking strategies. However, you must use automated browsers, like Selenium or Playwright, instead of HTTP requests.
The lack of strategies to bypass anti-scraping measures makes the code unsuitable for large-scale web scraping. Moreover, the data layer variable’s name may differ. You must figure it out by studying the website’s structure, which can be tedious.
It’s better to use professional web scraping services if you don’t want to code yourself or build a more robust code appropriate for large-scale data extraction.
Try ScrapeHero. We’re a full-service web scraping service provider capable of building enterprise-grade web scrapers. Our services range from data extraction to custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



