

Email scraping allows you to build a large email database by automatically gathering emails from the internet. This database can be immensely helpful for marketing campaigns necessary for your business’s growth. However, you need to know how to scrape emails from websites.
This tutorial shows you how to scrape emails from a website for free using Python.
How to Scrape Emails from Websites: The Setup
This tutorial uses Python to scrape websites for business emails. The code includes three external Python libraries:
You can install them using Python pip.
Here,
- Selenium allows you to control a browser through the script and has methods to locate and extract data. For example, its get() method enables you to visit a specific webpage, and the find_element() method, to extract HTML elements from it.
- BeautifulSoup enables data extraction from an HTML code. Its methods for data extraction are more intuitive than those of Selenium. For example, its find_all() method can locate and extract elements based on HTML tags and attributes.
- The library Pandas helps you manage structured data. Its methods can read files in formats like CSV and clean them. For example, the read_csv() method reads a CSV file, and the drop_duplicates() method removes duplicates from the data.
The Python code uses the above libraries to get a list of websites from a CSV file and extract emails from them.
How to Scrape Emails from a Website: The Code
This code first imports packages, then defines functions, and finally, calls them. It uses “https://billboard.com” as an example.
Import Packages
In addition to the external Python libraries mentioned above, the code also uses several other internal packages.
- The json module to write the extracted emails to a JSON file
- The argparse module to get the name of the CSV file containing the list of websites during the script execution
- The sleep module to implement pauses during script execution using its time method
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import argparse
import pandas
from time import sleep
import re
import jsonDefine Functions
The script uses four functions to scrape emails from websites: parseMail(), getEmails(), getArgs(), and readCSV().
parseMail() extracts emails from a page. It uses BeautifulSoup for scraping from the links and RegEx for extracting emails from plain text.
def parseMail(driver,emails):
source = driver.page_source
soup = BeautifulSoup(source,'lxml')
links = soup.find_all('a')
email_pattern = re.compile(r'([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4})')
for link in links:
try:
if "mailto" in link['href']:
if re.search(email_pattern,link['href'].split(':')[1]):
emails.append(link['href'].split(':')[1])
except:
continue
email_matches = re.findall(email_pattern, str(soup.body.select(":not(script)")))
for email in email_matches:
emails.append(email)The function:
- Gets the source code from the target webpage using Selenium’s page_source attribute
- Passes the source code to BeautifulSoup()
- Finds all the anchor elements using find_all()
- Iterates through those links
- Checks if their href attribute has “mailto” in it
- Checks if the part after “mailto” matches the pattern of an email
- Appends that part to an array
- Finds all the plain text matching the email pattern and appends it to the same array.
Note: The email pattern is a RegEx. Moreover, the code block above uses a try-except block, as you want the code to check other links even if you get an error.
The getEmail() function visits a website’s home page and contact page, calls parseMail() each time, and returns the scraped emails.
def getEmail(website):
print("scraping from",website)
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
driver.get(website)
sleep(3)
emails = []
parseMail(driver,emails)
contact_page = None
try:
contact_page = driver.find_element(By.XPATH,"//a[contains(text(),'ontact')]")
except:
print("Sorry, could not get emails for", website)
return None
url = contact_page.get_attribute('href')
print("scraping from",url)
driver.get(url)
sleep(3)
parseMail(driver,emails)
return emailsThe function:
1. Launches Selenium in headless mode using Selenium options
2. Visits the website URL using the get() method and calls parseMail()
3. Locates the Contact Page link using Selenium’s find_element() method. The code uses a try-except block so that errors won’t stop code execution.
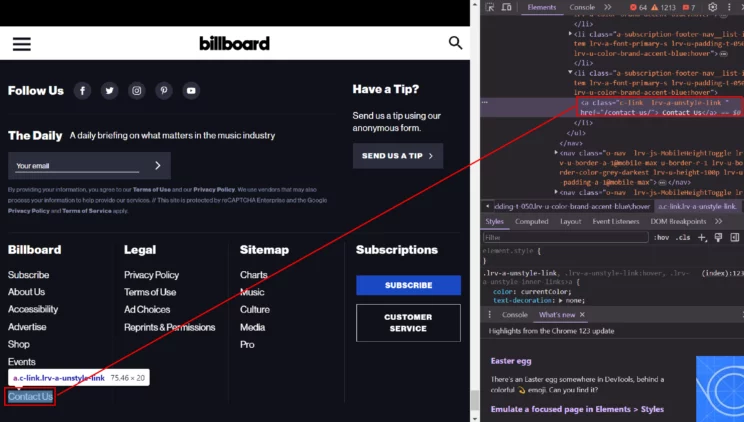
4. Visits the contact page and calls parseMail()
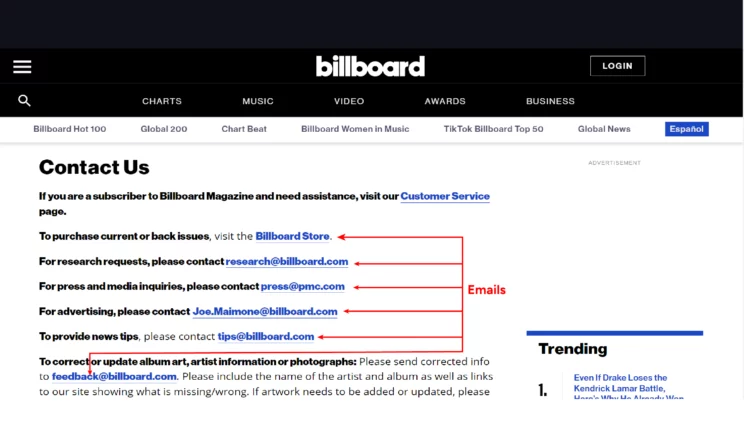
5. Returns extracted emails
Note: The above code uses sleep() to pause the script execution for three seconds, giving time for the elements to load.
The getArgs() function uses the argparse module and gets the name of the CSV file containing the list of websites.
def getArgs():
argparser = argparse.ArgumentParser()
argparser.add_argument('csv',help = 'Name of the CSV file')
args = argparser.parse_args()
csv = args.csv
return csv
The function:
1. Calls Argparser() method
2. Uses add_argument() to specify the arguments argparse will parse during script execution
3. Uses pars_args() method to parse and extract argument and store it in a variable
4. Returns the variable
The readCSV() function integrates all the above functions by calling getEmail() for each website.
def readCSV():
csvFile = getArgs()
df = pandas.read_csv(csvFile)
print(df)
allEmails = []
for website in df["websites"][:1]:
emails = getEmail(website)
frame=pandas.DataFrame(emails)
frame.drop_duplicates(inplace=True)
if emails:
allEmails.append({website.split('/')[2]:frame[0].tolist()})
with open("websites.json","w") as jsonFile:
json.dump(allEmails,jsonFile,indent=4)
else:
print("Sorry, no emails found")The function:
1. Calls getArgs() and gets the name of the CSV file containing the list of the websites you want to scrape.
2. Uses the name to read the CSV file using Pandas.
3. Cleans the data read from the CSV file using Pandas.
4. Calls getEmail() with the websites as arguments in a loop.
5. Saves all the extracted emails to a JSON file.
Finally, call the readCSV() function to begin the code execution.
if __name__=="__main__":
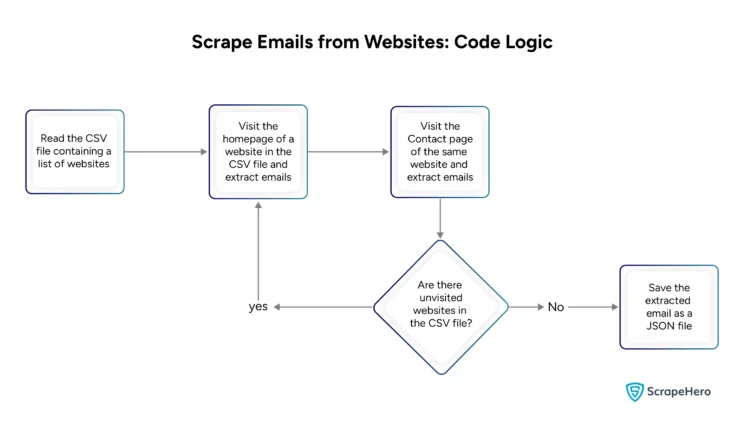
readCSV()Here is a flowchart showing how to scrape emails from websites.
Code Limitations
The code can only extract emails from websites that do not try to obfuscate emails. These websites hide the emails on the website using various techniques, like encoding and concatenating.
You must understand these techniques before learning how to scrape emails from any website.
This code also does not use techniques to bypass anti-scraping measures, which are necessary for web scraping on a large scale. You may then have to add additional code for large-scale data extraction.
ScrapeHero Email Scraper: An Alternative
You can avoid all these limitations using ScrapeHero Email Scraper from our ScrapeHero Cloud. This web scraper provides a no-code solution to extract emails and other contact details from a list of websites. Moreover, you can use this cloud scraper for free for up to 25 pages.
As the scraper runs on the cloud, you don’t have to worry about overhead expenses. We can save your bandwidth by directly delivering the extracted data to your cloud storage, like Dropbox.
To get started with ScrapeHero Cloud
- Visit https://scrapehero.com/marketplace
- Create an account
- Add ScrapeHero Contact Details Scraper to your account
- Paste a list of websites into the input
- Click “Gather data”
Wrapping Up
It may be challenging to scrape emails from websites. Two simple ways are extracting emails from the mailto links using parsers and from plain text using RegEx. This code showed you both techniques using Python.
However, if the website uses obfuscation techniques, this script may not get all the emails. Add additional code in that case.
If you don’t want to do that, use the ScrapeHero Email Scraper.
And for large-scale data extraction, you can approach ScrapeHero services. ScrapeHero is a full-service web scraping service provider capable of building enterprise-grade web scrapers and crawlers. Our services also include product and brand monitoring and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


