
This article outlines a few methods to scrape Google Careers listings. This could effectively export job listing data to Excel or other formats for easier access and use.
There are two methods to scrape Google Careers:
- Scraping Google Careers in Python or JavaScript
- Using the ScrapeHero Cloud, Google Careers Scraper, a no-code tool

Building a Google Careers Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Google Careers using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or Beautiful Soup to build a Google Careers Scraper without using a browser or a browser automation library. But bypassing the anti scraping mechanisms put in place can be challenging and is beyond the scope of this article.
Here are the steps to scrape Google Careers listing data using Playwright:
Step 1: Choose Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
Python
JavaScript
Python
pip install playwright # to download the necessary browsers playwright install
JavaScript
npm install playwright@latest
Step 3: Write your code to emulate browser behavior and extract the desired data from Google Careers using the Playwright API. You can use the code provided below:
Python
JavaScript
Python
import asyncio
import json
from playwright.async_api import Playwright, async_playwright
search_keyword = "Software Engineer"
search_location = "New York"
pagination_limit = 2
data = []
def save_data():
"""
Saving the globaly stored data as json
"""
with open("google_career_data.json", "w") as outfile:
json.dump(data, outfile, indent=4)
def clean_data(data: str or list) -> str:
"""
This function will do basic string cleaning. If the input is string
It will clean the data and return the cleaned data. If it is list,
It will iterate through each elements clean and join them with a pipe.
Args:
data (str or list): The input can be string or list
Returns:
str: cleaned string
"""
if isinstance(data, str):
data = " ".join(data.split()).strip()
return data
data = [" ".join(i.split()).strip() for i in data]
data = " | ".join(data)
return data
async def extract_data(page, job_element) -> None:
"""This function is to extract data from the job listings page
Args:
page (playwright page object)
job_element (Playwright locator object)
"""
# Initializing necessary xpaths
xpath_title = "//h2[@class='p1N2lc']"
xpath_min_qualification = "//h3[text()='Minimum qualifications:']/following-sibling::ul[1]/li"
xpath_prefered_qualification = "//h3[text()='Preferred qualifications:']/following-sibling::ul[1]/li"
xpath_about_this_job = "//div[@class='aG5W3']/p"
xpath_responsibilities = '//div[@class="BDNOWe"]/ul/li'
xpath_job_url = "../../a"
# Extracting necessary data
title = await page.locator(xpath_title).inner_text()
min_qualification = await page.locator(xpath_min_qualification).all_inner_texts()
preferred_qualifications = await page.locator(xpath_prefered_qualification).all_inner_texts()
about_this_job = await page.locator(xpath_about_this_job).all_inner_texts()
responsibilities = await page.locator(xpath_responsibilities).all_inner_texts()
job_url = await job_element.locator(xpath_job_url).get_attribute("href")
# Cleaning
title = clean_data(title)
min_qualification = clean_data(min_qualification)
preferred_qualifications = clean_data(preferred_qualifications)
about_this_job = clean_data(about_this_job)
responsibilities = clean_data(responsibilities)
job_url = clean_data(job_url)
job_url = f"https://www.google.com/about/careers/applications{job_url}"
data_to_save = {
"title": title,
"min_qualification": min_qualification,
"preferred_qualifications": preferred_qualifications,
"about_this_job": about_this_job,
"responsibilities": responsibilities,
"job_url": job_url,
}
# Appending to a list to save
data.append(data_to_save)
async def parse_listing_page(page, current_page: int) -> None:
"""This function will go through each jobs listed and click it
and pass the page object to extract_data function to extract the data.
This function also handles pagination
Args:
page (playwright page object)
current_page (int): current page number
"""
xpath_learn_more = "//span[text()='Learn more']/following-sibling::a"
xpath_jobs = "//li[@class='zE6MFb']//h3"
xpath_title = "//h2[@class='p1N2lc']"
xpath_next_page = "//div[@class='bsEDOd']//i[text()='chevron_right']"
if current_page == 1:
# Clicking Learn more button (For the first page only)
learn_more_buttons = page.locator(xpath_learn_more)
first_learn_more_buttons = learn_more_buttons.nth(0)
await first_learn_more_buttons.click()
# Locating all listed jobs
await page.wait_for_selector(xpath_jobs)
jobs = page.locator(xpath_jobs)
jobs_count = await jobs.count()
# Iterating through each jobs
for i in range(jobs_count):
# Clicking each job
job_element = jobs.nth(i)
await job_element.click()
await extract_data(page, job_element)
await page.wait_for_selector(xpath_title)
# Pagination
next_page = page.locator(xpath_next_page)
if await next_page.count() > 0 and current_page < pagination_limit:
await next_page.click()
await page.wait_for_selector('//h3[@class="Ki3IFe"]')
await page.wait_for_timeout(2000)
current_page += 1
await parse_listing_page(page, current_page=current_page)
async def run(playwright: Playwright) -> None:
"""This is the main function to initialize the playwright browser
and create a page. Then do the initial navigations.
Args:
playwright (Playwright)
"""
# Initializing browser and opening a new page
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
# Navigating to homepage and clicking the "jobs" icon
await page.goto("https://careers.google.com/", wait_until="domcontentloaded")
await page.get_by_role("link", name="Jobs results page").click()
# Typing the job name and clicking enter
job_search_box = page.locator("//input[@id='c3']")
await job_search_box.click()
await job_search_box.type(search_keyword)
await job_search_box.press("Enter")
# Clicking the location searchbox icon
await page.locator("//h3[text()='Locations']").click()
location_filter_box = page.locator('//input[@aria-label="Which location(s) do you prefer working out of?"]')
await location_filter_box.click()
await location_filter_box.type(search_location, delay=200)
await location_filter_box.press("Enter")
await page.wait_for_load_state()
await page.wait_for_timeout(2000)
await parse_listing_page(page, current_page=1)
save_data()
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
JavaScript
const { chromium } = require('playwright');
const searchKeyword = "Software Engineer";
const searchLocation = "New York";
const paginationLimit = 2;
let data = [];
/**
* Saves the globally stored data as JSON.
*/
function saveData() {
const fs = require('fs');
fs.writeFileSync("google_career_data.json", JSON.stringify(data, null, 4));
}
/**
* Basic string cleaning function. If the input is a string,
* it will clean the data and return the cleaned data. If it is a list,
* it will iterate through each element, clean it, and join them with a pipe.
* @param {string | string[]} data - The input can be a string or a list
* @returns {string} - Cleaned string
*/
function cleanData(data) {
if (typeof data === "string") {
return data.replace(/s+/g, " ").trim();
}
return data.map((item) => item.replace(/s+/g, " ").trim()).join(" | ");
}
/**
* Extracts data from the product details page
* @param {Page} page - playwright page object
* @param {ElementHandle} jobElement - Playwright locator object
*/
async function extractData(page, jobElement) {
// Initializing necessary xpaths
const xpathTitle = "//h2[@class='p1N2lc']";
const xpathMinQualification = "//h3[text()='Minimum qualifications:']/following-sibling::ul[1]/li";
const xpathPreferredQualification = "//h3[text()='Preferred qualifications:']/following-sibling::ul[1]/li";
const xpathAboutThisJob = "//div[@class='aG5W3']/p";
const xpathResponsibilities = '//div[@class="BDNOWe"]/ul/li';
const xpathJobUrl = "../../a";
// Extracting necessary data
const title = await page.locator(xpathTitle).innerText();
const minQualification = await page.locator(xpathMinQualification).allInnerTexts();
const preferredQualifications = await page.locator(xpathPreferredQualification).allInnerTexts();
const aboutThisJob = await page.locator(xpathAboutThisJob).allInnerTexts();
const responsibilities = await page.locator(xpathResponsibilities).allInnerTexts();
const jobUrl = await jobElement.locator(xpathJobUrl).getAttribute("href");
// Cleaning data
const cleanedTitle = cleanData(title);
const cleanedMinQualification = cleanData(minQualification);
const cleanedPreferredQualifications = cleanData(preferredQualifications);
const cleanedAboutThisJob = cleanData(aboutThisJob);
const cleanedResponsibilities = cleanData(responsibilities);
const cleanedJobUrl = `https://www.google.com/about/careers/applications${cleanData(jobUrl)}`;
const dataToSave = {
title: cleanedTitle,
minQualification: cleanedMinQualification,
preferredQualifications: cleanedPreferredQualifications,
aboutThisJob: cleanedAboutThisJob,
responsibilities: cleanedResponsibilities,
jobUrl: cleanedJobUrl,
};
// Appending to a list to save
data.push(dataToSave);
}
/**
* Parses each job listing page, clicks on each job, and extracts data from the details page.
* Also handles pagination.
* @param {Page} page - playwright page object
* @param {number} currentPage - current page number
*/
async function parseListingPage(page, currentPage) {
// Initializing necessary xpaths
const xpathLearnMore = "//span[text()='Learn more']/following-sibling::a";
const xpathJobs = "//li[@class='zE6MFb']//h3";
const xpathTitle = "//h2[@class='p1N2lc']";
const xpathNextPage = "//div[@class='bsEDOd']//i[text()='chevron_right']";
if (currentPage === 1) {
// Clicking Learn more button (For the first page only)
const learnMoreButtons = await page.locator(xpathLearnMore);
const firstLearnMoreButton = learnMoreButtons.nth(0);
await firstLearnMoreButton.click();
}
// Locating all listed jobs
await page.waitForSelector(xpathJobs);
const jobs = await page.locator(xpathJobs);
const jobsCount = await jobs.count();
// Iterating through each job
for (let i = 0; i < jobsCount; i++) {
// Clicking each job
const jobElement = jobs.nth(i);
await jobElement.click();
await extractData(page, jobElement);
await page.waitForSelector(xpathTitle);
}
// Pagination
const nextPage = await page.locator(xpathNextPage);
if (await nextPage.count() > 0 && currentPage < paginationLimit) {
await nextPage.click();
await page.waitForSelector('//h3[@class="Ki3IFe"]');
await page.waitForTimeout(2000);
currentPage += 1;
await parseListingPage(page, currentPage);
}
}
/**
* Main function to initialize the playwright browser,
* create a page, and do the initial navigations.
*/
async function run() {
const browser = await chromium.launch({headless: false});
const context = await browser.newContext();
const page = await context.newPage();
// Navigating to homepage and clicking the "jobs" icon
await page.goto("https://careers.google.com/", { waitUntil: "domcontentloaded" });
await page.getByRole("link", { name: "Jobs results page" }).click();
// Typing the job name and clicking enter
const jobSearchBox = page.locator("//input[@id='c3']");
await jobSearchBox.click();
await jobSearchBox.type(searchKeyword);
await jobSearchBox.press("Enter");
// Clicking the location search box icon
await page.locator("//h3[text()='Locations']").click();
const locationFilterBox = page.locator('//input[@aria-label="Which location(s) do you prefer working out of?"]');
await locationFilterBox.click();
await locationFilterBox.type(searchLocation, { delay: 200 });
await locationFilterBox.press("Enter");
await page.waitForLoadState();
await page.waitForTimeout(2000);
await parseListingPage(page, 1);
saveData();
await context.close();
await browser.close();
}
/**
* Main async function to run the script.
*/
run()
This code shows how to scrape Google Careers using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Google Careers, fills in a search query based on role and location, clicks the search button, and waits for the results to be displayed on the page. The save_data function is then called to extract the listing details and store the data in a google_career_data.json file.
- extract_data function: This function takes a Playwright page object as input and returns a list of dictionaries containing details of the job listings. The details include each role’s title, qualifications required, description, responsibilities, and specific URL.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Google Careers script you just executed would be created.
Step 4: Run your code and collect the scraped data from Google Careers.
Using No-Code Google Careers Scraper by ScrapeHero Cloud
The Google Careers Scraper by ScrapeHero Cloud is a convenient method for scraping listings of job openings at Google from Google Careers. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the Google Careers scraper.
- Sign up or log in to your ScrapeHero Cloud account.
- Go to the Google Careers Scraper by ScrapeHero Cloud.
- Add the scraper to your account. (Don’t forget to verify your email if you haven’t already.)
- Add the Google Careers listing page URL to start the scraper. If it’s just a single query, enter it in the field provided and choose the number of pages to scrape.
You can get the careers listing URL from the Google Careers search results page.-
- Input role and location of choice.
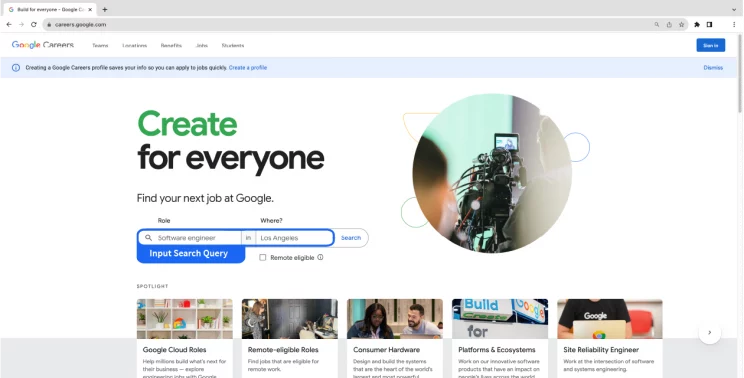
- Input role and location of choice.
- Copy the targeted Google careers listing page URL.
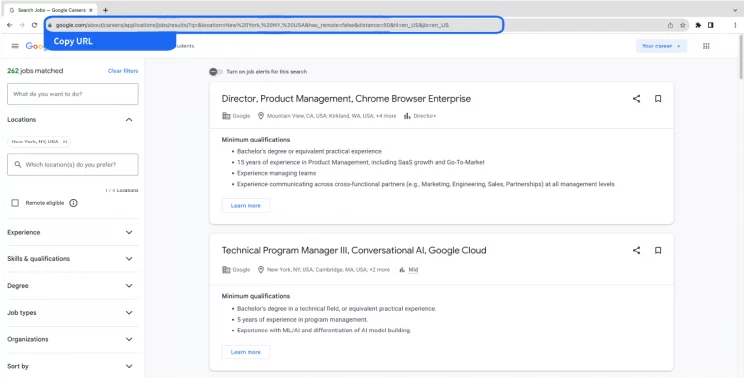
-
- To scrape results for multiple queries, switch to Advance Mode, and in the Input tab, add the listing page URL to the SearchQuery field and save the settings.
- To start the scraper, click on the Gather Data button.
- The scraper will start fetching data for your queries, and you can track its progress under the Jobs tab.
- Once finished, you can view or download the data from the same.
- You can also export the job listings data into an Excel spreadsheet from here. Click on the Download Data, select “Excel,” and open the downloaded file using Microsoft Excel.
Uses cases of Google Careers Listings Data
For individuals actively seeking job opportunities at Google, scraping Google Careers can improve their chances of landing a position, here’s how:
Real-Time Job Alerts
Using web scraping techniques on Google Careers, job seekers can set up real-time alerts for specific job roles, locations, or keywords. This ensures that they receive immediate notifications whenever relevant job openings are posted. Staying updated on the latest opportunities gives candidates a competitive advantage and increases their chances of applying early.
Analyzing Job Requirements
Career data scraping enables candidates to analyze the requirements and qualifications Google seeks for various positions. By studying the skills, experience, and educational background desired by the company, candidates can tailor their resumes and cover letters accordingly, increasing the likelihood of catching the recruiter’s attention.
Company Insights
Scraping Google Careers listings provides valuable insights into the company’s hiring patterns and trends. Understanding the frequency and types of job openings can help candidates identify recurring opportunities and areas where Google is actively recruiting.
Tracking Hiring Trends
Web scraping can help candidates track Google’s hiring trends. Observing when the company tends to increase hiring or focuses on specific roles can offer a broader perspective on the company’s current priorities and potential upcoming opportunities.
Preparing for Interviews
Reviewing past job descriptions and requirements can assist candidates in preparing for interviews by anticipating potential questions and understanding the company’s expectations.
Frequently Asked Questions
What is Google Careers scraping?
Google Careers scraping refers to extracting job listing data from a pool of openings at Google. This process allows for candidates to combine web scraping insights with other job search strategies to maximize their chances of securing a position at Google.
What is the subscription fee for the Google Careers Scraper by ScrapeHero?
To know more about the pricing, visit the pricing page.
Is it legal to scrape Google Careers?
Legality depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Generally, Web scraping is legal if you are scraping publicly available data.
Please refer to our Legal Page to learn more about the legality of web scraping.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


