

This article outlines a few methods to scrape Homes.com. This could effectively export real estate data to Excel or other formats for easier access and use.
There are three methods to scrape real estate data:
- Scraping Homes.com in Python or JavaScript
- Using the ScrapeHero Cloud, Homes.com Scraper, a no-code tool

Build Homes.com Scraper in Python/JavaScript
In this section, we will guide you on how to scrape real estate data from Homes.com using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or Beautiful Soup to build a Homes.com scraper without using a browser or a browser automation library. However, bypassing the anti-scraping mechanisms put in place can be challenging and is beyond the scope of this article.
Here are the steps to scrape real estate data using Playwright:
Step 1: Choose Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
Python
JavaScript
Python
pip install playwright
# to download the necessary browsers playwright install JavaScript
npm install playwright@latest
Step 3: Write your code to emulate browser behavior and extract the desired data from Homes.com using the Playwright API. You can use the code provided below:
Python
JavaScript
Python
import asyncio
import json
from playwright.async_api import Playwright, async_playwright
data = []
zip_code = "10001"
pagination_limit = 2
def save_data():
"""
Saving the globaly stored data as json
"""
with open("Homes_data.json", "w") as outfile:
json.dump(data, outfile, indent=4)
async def parse_product_page(page):
"""
Parses information from a product page and extracts relevant details.
This function takes a browser page object and extracts various details from
the product page using XPath locators. It waits for the DOM to be fully loaded
before attempting to locate and retrieve the information.
Args:
page (Page): The browser page object representing the product page.
"""
xpath_price = "//span[@id='price']"
xpath_beds = "//span[contains(@class, 'beds')]/span[contains(@class, 'detail')]"
xpath_baths = "//span[@class='property-info-feature']/span[contains(@class, 'detail')]"
xpath_sqft = "//span[contains(@class, 'sqft')]/span[contains(@class, 'detail')]"
xpath_hao_fee = "//span[contains(@class, 'hoaFee')]/span[contains(@class, 'detail')]"
xpath_address_line_1 = "//h1[@class='property-info-address-main']"
xpath_address_line_2 = "//span[@class='property-info-address-citystatezip']"
xpath_about = "//p[@class='ldp-description-text']"
price = await page.locator(xpath_price).inner_text()
beds = await page.locator(xpath_beds).inner_text()
baths = await page.locator(xpath_baths).inner_text()
sqft = await page.locator(xpath_sqft).inner_text()
hao_fee = await page.locator(xpath_hao_fee).inner_text()
address_line_1 = await page.locator(xpath_address_line_1).inner_text()
address_line_2 = await page.locator(xpath_address_line_2).inner_text()
about = await page.locator(xpath_about).all_inner_texts()
data_to_save = {
"price": price,
"beds": beds,
"baths": baths,
"sqft": sqft,
"hao_fee": hao_fee,
"address_line_1": address_line_1,
"address_line_2": address_line_2,
"about": " ".join(about).strip(),
}
data.append(data_to_save)
async def parse_listing_page(page, current_page):
"""
Iterates through a listing page, extracts information from individual listings,
and handles pagination to continue parsing subsequent pages.
This function takes a browser page object, representing a listing page, and the
current page number. It locates each individual listing element on the page, clicks
on it to open a popup with details, parses the details using 'parse_product_page',
and then closes the popup. After processing all listings on the current page, it
checks for pagination, clicks the 'Next Page' button if available, and recursively
calls itself to parse the next page.
Args:
page (Page): The browser page object representing the listing page.
current_page (int): The current page number being parsed.
"""
xpath_products = "//ul[@class='placards-list']/li//a[@title]"
xpath_next_page = '//button[@title="Next Page"]'
await page.wait_for_timeout(5000)
listed_homes = page.locator(xpath_products)
listed_homes_count = await listed_homes.count()
for i in range(listed_homes_count):
item_element = listed_homes.nth(i)
async with page.expect_popup() as page_1_info:
await item_element.click()
page_1 = await page_1_info.value
await page_1.wait_for_load_state(timeout=60000)
await parse_product_page(page_1)
await page_1.close()
# Pagination
next_page = page.locator(xpath_next_page)
if await next_page.count() > 0 and current_page <= pagination_limit:
current_page += 1
await next_page.click()
await parse_listing_page(page, current_page)
async def parse_search(page):
"""
Performs a search operation on a webpage by entering a ZIP code into a search box.
This function takes a browser page object and interacts with a search box element
on the page. It clicks on the search box, types the provided ZIP code with a slight
delay between keystrokes, presses the 'Enter' key, and waits for the page to finish
loading. The resulting page is returned after the search operation is completed.
Args:
page (Page): The browser page object to perform the search on.
Returns:
Page: The updated browser page object after the search operation.
"""
xpath_search_box = "//input[contains(@class, 'multiselect-search')]"
await page.locator(xpath_search_box).click()
await page.locator(xpath_search_box).type(zip_code, delay=200)
await page.wait_for_load_state("domcontentloaded")
await page.locator(xpath_search_box).press("Enter")
await page.wait_for_load_state("domcontentloaded")
return page
async def run(playwright: Playwright) -> None:
"""
Orchestrates a web scraping process using the Playwright library.
Launches a Chromium browser instance, navigates to a URL, performs
parsing operations, and closes the browser after saving data.
Args:
playwright (Playwright): The Playwright instance for browser operations.
Returns:
None
"""
# Initializing browser, context and a new page
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
url = "https://www.Homes.com/"
await page.goto(url, wait_until="domcontentloaded")
page = await parse_search(page=page)
page = await parse_listing_page(page, 1)
save_data()
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main()) JavaScript
const { chromium } = require('playwright');
let data = [];
const zipCode = "10001";
const paginationLimit = 2;
/**
* Saves the globally stored data as JSON.
*/
function saveData() {
const fs = require('fs');
fs.writeFileSync('Homes_data.json', JSON.stringify(data, null, 4));
}
/**
* Parses information from a product page and extracts relevant details.
*
* @param {Page} page - The browser page object representing the product page.
*/
async function parseProductPage(page) {
await page.waitForTimeout(10000);
const xpathPrice = "//span[@id='price']";
const xpathBeds = "//span[contains(@class, 'beds')]/span[contains(@class, 'detail')]";
const xpathBaths = "//span[@class='property-info-feature']/span[contains(@class, 'detail')]";
const xpathSqft = "//span[contains(@class, 'sqft')]/span[contains(@class, 'detail')]";
const xpathHoaFee = "//span[contains(@class, 'hoaFee')]/span[contains(@class, 'detail')]";
const xpathAddressLine1 = "//h1[@class='property-info-address-main']";
const xpathAddressLine2 = "//span[@class='property-info-address-citystatezip']";
const xpathAbout = "//p[@class='ldp-description-text']";
const price = await page.locator(xpathPrice).innerText();
const beds = await page.locator(xpathBeds).innerText();
const baths = await page.locator(xpathBaths).innerText();
const sqft = await page.locator(xpathSqft).innerText();
const haoFee = await page.locator(xpathHoaFee).innerText();
const addressLine1 = await page.locator(xpathAddressLine1).innerText();
const addressLine2 = await page.locator(xpathAddressLine2).innerText();
const about = await page.locator(xpathAbout).allInnerTexts();
const dataToSave = {
price: price,
beds: beds,
baths: baths,
sqft: sqft,
haoFee: haoFee,
addressLine1: addressLine1,
addressLine2: addressLine2,
about: about.join(' ').trim(),
};
data.push(dataToSave);
}
/**
* Iterates through a listing page, extracts information from individual listings,
* and handles pagination to continue parsing subsequent pages.
*
* @param {Page} page - The browser page object representing the listing page.
* @param {number} currentPage - The current page number being parsed.
*/
async function parseListingPage(page, currentPage) {
const xpathProducts = "//ul[@class='placards-list']/li//a[@title]";
const xpathNextPage = '//button[@title="Next Page"]';
await page.waitForTimeout(5000);
const listedHomes = page.locator(xpathProducts);
const listedHomesCount = await listedHomes.count();
for (let i = 0; i < listedHomesCount; i++) {
const itemElement = listedHomes.nth(i);
await itemElement.click();
const page1 = await page.waitForEvent('popup');
await page1.waitForLoadState("load");
await parseProductPage(page1);
await page1.close();
}
// Pagination
const nextPage = page.locator(xpathNextPage);
if ((await nextPage.count()) > 0 && currentPage <= paginationLimit) {
currentPage += 1;
await nextPage.click();
await parseListingPage(page, currentPage);
}
}
/**
* Performs a search operation on a webpage by entering a ZIP code into a search box.
*
* @param {Page} page - The browser page object to perform the search on.
* @returns {Page} - The updated browser page object after the search operation.
*/
async function parseSearch(page) {
const xpathSearchBox = "//input[contains(@class, 'multiselect-search')]";
await page.locator(xpathSearchBox).click();
await page.locator(xpathSearchBox).type(zipCode, { delay: 200 });
await page.waitForLoadState("domcontentloaded");
await page.locator(xpathSearchBox).press("Enter");
await page.waitForTimeout(10000);
return page;
}
/**
* Main Web Scraping Function
*
* This function orchestrates the web scraping process using the Playwright library.
* It launches a Chromium browser instance, navigates to a specified URL, performs
* parsing operations, and closes the browser after data is saved.
*
* @async
* @function main
* @returns {Promise<void>} - A Promise that resolves when the scraping process is complete.
*/
async function main () {
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext();
const page = await context.newPage();
const url = "https://www.Homes.com/";
await page.goto(url, { waitUntil: "domcontentloaded" });
await parseSearch(page);
await parseListingPage(page, 1);
saveData();
await context.close();
await browser.close();
}
main(); This code shows how to scrape Homes.com using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions, namely:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Homes.com, fills in a search query, clicks the search button, and waits for the results to be displayed on the page.
The save_data function is then called to extract the real estate data and store the data in a JSON file named Homes_data.json. - save_data function: This function takes a Playwright page object as input and returns a list of dictionaries containing listing details. The details include each listing’s price,number of bedrooms and bathrooms, square footage, address, etc.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Homes.com script you just executed would be created.
Step 4: Run your code and collect the scraped data from Homes.com.
Using No-Code Homes.com Scraper by ScrapeHero Cloud
The Homes.com Scraper by ScrapeHero Cloud is a convenient method for scraping real estate data from Homes.com. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the Homes.com scraper.
- Sign up or log in to your ScrapeHero Cloud account.
- Go to the Homes.com Scraper by ScrapeHero Cloud in the marketplace.
Note:The ScrapeHero Cloud’s Homes.com Scraper falls under the premium scrapers category that does not include a free tier. To access this scraper, the user should be subscribed to a paid plan. - Add the scraper to your account. (Don’t forget to verify your email if you haven’t already.)
- You need to add the Homes.com search results URL for a particular location to start the scraper. If it’s just a single query, enter it in the field provided and choose the number of pages to scrape.
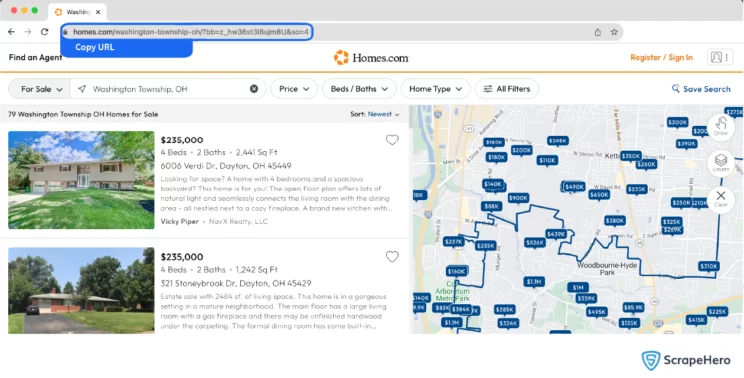
- To scrape results for multiple queries, switch to Advance Mode, and in the Input tab, add the search results URL to the SearchQuery field and save the settings.
- To start the scraper, click on the Gather Data button.
- The scraper will start fetching data for your queries, and you can track its progress under the Jobs tab.
- Once finished, you can view or download the data from the same.
- You can also export the listings data into an Excel spreadsheet from here. Click on the Download Data, select “Excel,” and open the downloaded file using Microsoft Excel.
Uses cases of Web Scraping Real Estate Data
If you’re unsure as to why you should scrape real estate data, here are a few use cases where this data would be helpful:
Real Estate Investment
Use Homes.com data to analyze property prices, historical value trends, and local features in specific zip codes. This data helps investors pinpoint lucrative investment locations, understand market dynamics, and make forecasts to reduce risk and maximize ROI.
Smart Home Buying
Real Estate Data from Homes.com aids potential homeowners in price comparison, value trend analysis, and amenity mapping (like schools, malls, parks). This equips buyers to make decisions that are cost-effective and align with their lifestyle.
Real Estate Professionals
Agents and brokers can utilize real estate data from Homes.com for in-depth market analysis. Knowledge of average pricing, buyer patterns, and past sales enables agents to effectively match properties with buyers and price listings competitively.
Property Development
Builders and developers can use data from Homes.com to identify in-demand property features in targeted locations. For example, if solar-powered homes are trending in an area, developers can include these features in new projects.
Urban Planning
Policy-makers can use Homes.com data to inform decisions on zoning laws and housing policies. If the data indicates a shortage of affordable housing in an area, strategies can be developed to incentivize low-cost housing projects.
Frequently Asked Questions
Homes.com scraping refers to extracting real estate data from the real estate listings available on Homes.com. This process allows for systematically collecting housing data displayed on this popular real estate website.
What is real estate web scraping?
Real estate web scraping is the automated collection of property and consumer data from online real estate websites. This method provides detailed insights on available properties, buyer preferences, and agent reliability, storing it in a structured table format, such as spreadsheets or databases. The scraped data is instrumental for making investment decisions, optimizing pricing models, etc. in the real estate sector.
What is the subscription fee for the Homes.com Scraper by ScrapeHero?
To know more about the pricing, visit the pricing page.
Is it legal to scrape Homes.com?
Legality depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Generally, Web scraping is legal if you are scraping publicly available data.
Please refer to our Legal Page to learn more about the legality of web scraping:
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



