
Web scraping is an efficient method for extracting data about movies, timings, seating etc from movie sites.
Imagine all the movie data that you can gather on a daily basis. You could scrape the data for a particular actor, director or genre and use the information to analyze ongoing movie trends.
This tutorial is about scraping movie details from Fandango.com, a movie booking site, which allows you to find movie overviews and current showtimes.
In this web scraping tutorial, we’ll scrape Fandango.com for the movie details based on a given location and date.
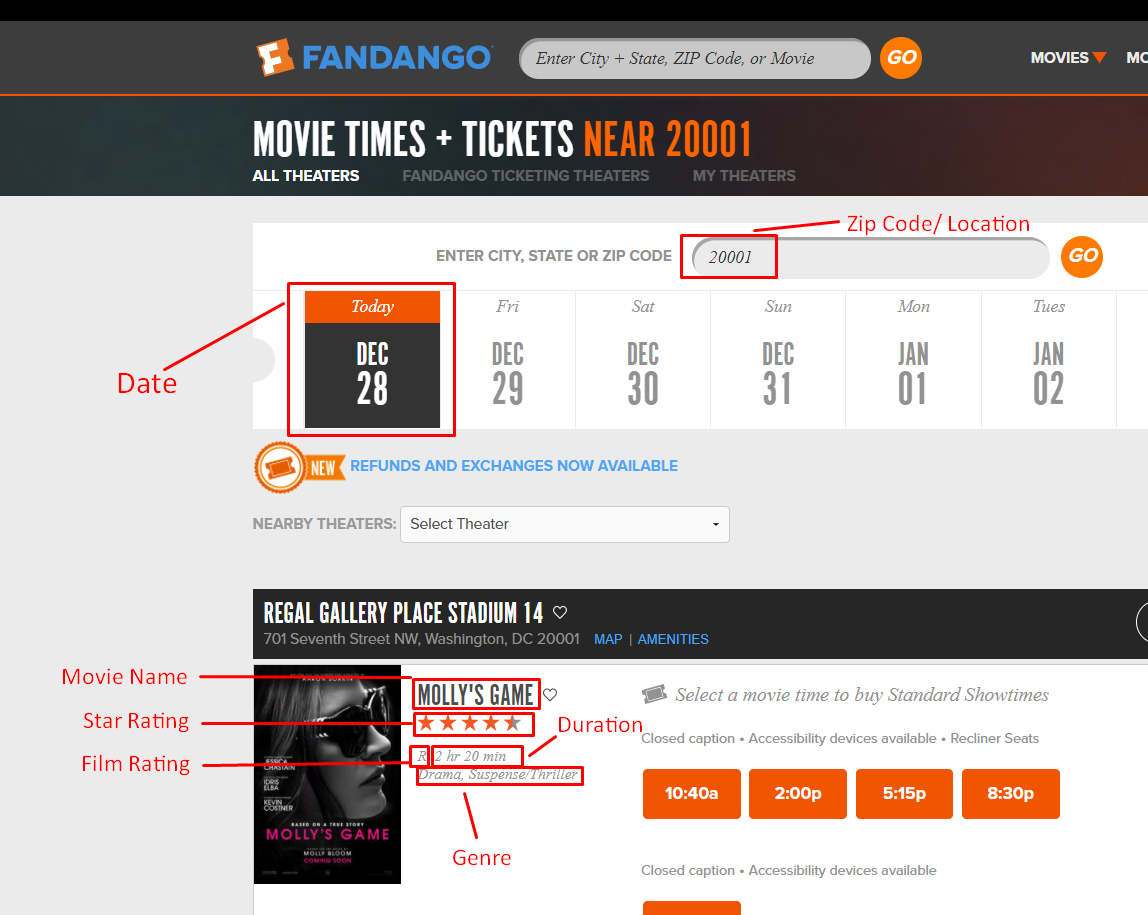
Here is a list of fields we will be extracting:
- Theater Name
- Theater Address
- Movie Name
- Show Date
- Zip Code/Location
- Duration
- Genre
- Star Rating (Out of 5)
- Movie Rating
Below is a screenshot of some of the data that will be scraped.
Scraping Logic
- Construct the URL of the search results from Fandango- Here is the one for the zip code 20001- https://www.fandango.com/20001_movietimes?mode=general&q=20001
- Download HTML of the search result page using Python Requests.
- Parse the page using LXML – LXML lets you navigate the HTML Tree Structure using Xpaths. We have predefined the XPaths for the details we need in the code.
- Save the data to a CSV file. In this article we are only scraping the movie name, rating, genre, theater address and name from the first page of results, so a CSV file should be enough to fit in all the data. If you would like to extract details in bulk, a JSON file is more preferable. You can read about choosing your data format, just to be sure.
Requirements
For this web scraping tutorial using Python 3, we will need some packages for downloading and parsing the HTML. Below are the package requirements.
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users go here – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Install Packages
- PIP to install the following packages in Python (https://pip.pypa.io/en/stable/installing/)
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpaths (Learn how to install that here – http://lxml.de/installation.html)

The Code
https://gist.github.com/scrapehero/edc9d9dffd24402a9c176862d076db18
If the embed above doesn’t work, you can download the code from the link here.
If you would like the code in Python 2.7, check out this link.
Running the Scraper
Assume the script is named fandango.py. If you type in the script name in command prompt or terminal along with a -h
usage: fandango.py [-h] location showdate positional arguments: location movie location (zipcode or city+state) showdate movie show time optional arguments: -h, --help show this help message and exit
The arguments location and showtime are the keywords to find the list of movies for a given location and date.
The argument for location can be given by using a zip code, or you can provide it in the format ‘City, State Abbreviation’. The argument showdate should be given in the format YYYY/MM/DD.
python3 fandango.py "Queen City, CA" "2017-12-29"
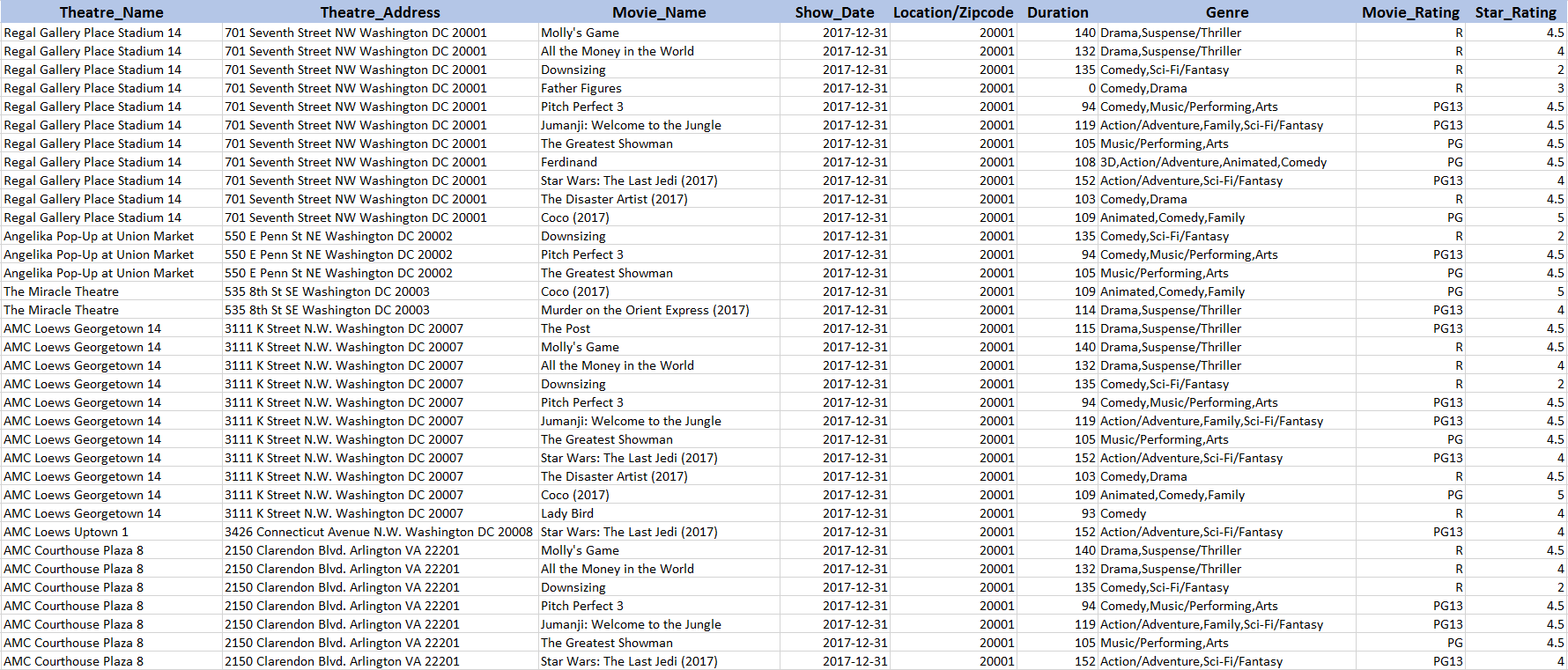
This will create a CSV file called Queens, CA-2017-12-29-movie-results.csv that will be in the same folder as the script. Here is some sample data extracted from Fandango.com for the command above. You can follow this tutorial if you would like to parse the address into a structured format.
Known Limitations
This scraper should be able to scrape the details of movies currently showing on Fandango.com. You can even go further and create a complex scraper to collect the details of the available seats for each showtime. If you would like to scrape the details of thousands of pages at very short intervals then you should read Scalable do-it-yourself scraping – How to build and run scrapers on a large scale and How to prevent getting blacklisted while scraping
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


