

Scraping a dynamic website, like Walmart, can be quite challenging. But you can scrape Walmart reviews using HTTP request methods without using headless browsers. How? Just extract the data from a JSON string embedded within the website’s script tags.
This article offers a detailed guide on how to scrape Walmart reviews using Python’s requests library and BeautifulSoup.
Scrape Walmart Reviews: The Environment
Before you begin scraping, you’ll need to install BeautifulSoup and requests:
You can do this using pip:
pip install beautifulsoup4 requestsData Scrape from Walmart
This code in this tutorial can scrape four data points from Walmart:
- Rating given by the reviewer
- Title of the review
- Review text
- The review submission date
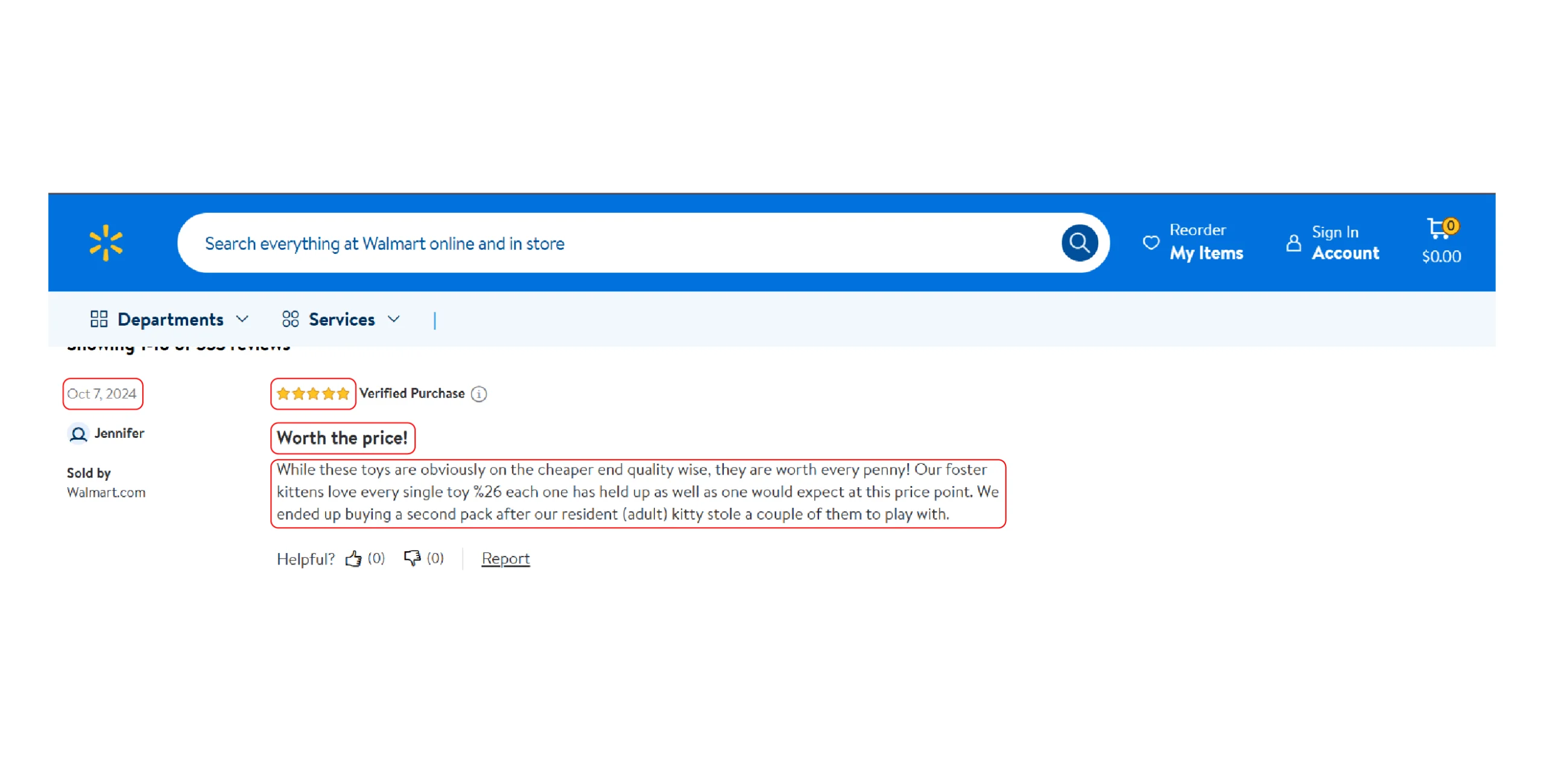
All this information is available inside a script tag, which you can locate by analyzing the webpage’s HTML source.
Scrape Walmart Reviews: The Code
Start by importing the necessary libraries.
- BeautifulSoup from the bs4 library is used for parsing HTML documents.
- json handles JSON data.
- requests is used to make HTTP requests to fetch web pages.
from bs4 import BeautifulSoup
import json, requestsNext, define a function called scrape_reviews that accepts an argument, url. This function will allow you to scrape Walmart customer reviews from a specific product URL.
def scrape_reviews(url):Set a variable max_pages to 5 to limit the number of pages to scrape. This helps manage the data volume and reduces server load; adjust this number based on your needs.
max_pages = 5Create an empty list all_reviews to store all scraped reviews; this list will hold dicts with the extracted review data.
all_reviews = []Now, you can run a loop as many times as the value of max_pages.
In each iteration, the code:
1. Uses the variable i to construct the URL for each page.
2. Sends an HTTP GET request to that URL
response = requests.get(f'{url}?page={i+1}', headers={'user-agent': '*'})Note: The code uses a custom user agent string, which you may need to rotate to avoid getting blocked. Read How to Fake and Rotate User-Agents to know more.
3. Parses the response with BeautifulSoup, converting raw HTML into a more manageable format for locating elements.
soup = BeautifulSoup(response.text, 'lxml')4. Looks for a script tag with an ID of __NEXT_DATA__ that contains a JSON string containing review data.
json_string = soup.find('script', {'id': '__NEXT_DATA__'}).text5. Parses the JSON string using json.loads(), allowing you to navigate the JSON data.
json_data = json.loads(json_string)6. Navigates through the parsed JSON data to extract customer reviews.
customer_reviews = json_data['props']['pageProps']['initialData']['data']['reviews']['customerReviews']7. Loops through each review and extracts rating, title, text, and submission date, then appends them to the earlier defined list.
for review in customer_reviews:
all_reviews.append({
'Rating': review['rating'],
'Title': review['reviewTitle'],
'Text': review['reviewText'],
'Date': review['reviewSubmissionTime']
})After the loop ends, the code saves the collected reviews in a file named walmart.json. The context manager (with) handles the file’s opening and closing, while json.dump() writes the list of dicts into the file.
with open("walmart.json", 'w', encoding='utf-8') as f:
json.dump(all_reviews, f, indent=4, ensure_ascii=False)Finally, call the function with a specific product URL to start extracting the review_data.
scrape_reviews('https://www.walmart.com/reviews/product/706770009')Using a List of Product Codes
The above method can extract reviews of a specified product. That means you need to change the product code manually. Instead, you can use a CSV file with product codes.
To do that, first, prepare a CSV file by gathering product codes. The file will look something like this:
product_codes
11439573544
777712139
6524705484Next, read the CSV file; you can use Pandas for that.
import pandas
with open(‘walmart.csv’) as f: # assuming the CSV file is named ‘walmart.csv’
codes = pandas.read_csv(f)Now, call scrape_reviews() in a loop.
for code in codes['product_codes']:
scrape_reviews(f'https://www.walmart.com/reviews/product/{code}',code)In the above snippet, you also pass the variable code in addition to the URL. This allows you to save the extracted reviews with a file name that includes the product code.
In theory, the above snippets should extract reviews from each product; however, Walmart might block repeated queries from the same user agent. So you need to rotate user agents using a Python library like fake_useragent.
from fake_useragent import UserAgent
ua = UserAgent()
for i in range(max_pages):
response = requests.get(f'{url}?page={i+1}', headers={'user-agent':f'{ua.random}'})Here’s the complete code for scraping Walmart reviews:
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import json, requests, pandas
def scrape_reviews(url,product_code):
max_pages = 5
ua = UserAgent()
all_reviews = []
for i in range(max_pages):
response = requests.get(f'{url}?page={i+1}', headers={'user-agent':f'{ua.random}'})
soup = BeautifulSoup(response.text, 'lxml')
json_string = soup.find('script', {'id': '__NEXT_DATA__'}).text
json_data = json.loads(json_string)
customer_reviews = json_data['props']['pageProps']['initialData']['data']['reviews']['customerReviews']
for review in customer_reviews:
all_reviews.append({
'Rating': review['rating'],
'Title': review['reviewTitle'],
'Text': review['reviewText'],
'Date': review['reviewSubmissionTime']
})
with open(f"walmart_{product_code}.json", 'w', encoding='utf-8') as f:
json.dump(all_reviews, f, indent=4, ensure_ascii=False)
with open('walmart.csv') as f:
codes = pandas.read_csv(f)
for code in codes['product_codes']:
scrape_reviews(f'https://www.walmart.com/reviews/product/{code}',code)
Code Limitations
While this code can get you started with Walmart review scraping, there are several limitations to consider:
- Dynamic Content Handling: If Walmart changes its website structure or uses advanced JavaScript rendering techniques (like AJAX), this code may break since it relies on the HTML structure to locate the elements.
- Rate Limiting and Blocking: Frequent requests to Walmart’s servers may lead to IP blocking. The current code doesn’t implement delays between requests or proxy rotation to overcome that, making it unsuitable for large-scale web scraping.
- Error Handling: The code lacks error handling mechanisms like try-except blocks that would provide feedback in case of errors.
- Further Data Requirements: The scraped data may not include all the information you want (e.g., reviewer names or helpful votes); you need to change the code for that.
Alternative: Walmart Review Scraper
If you’re looking for a no-code solution for Walmart data scraping, consider using ScrapeHero Cloud’s Walmart Review Scraper. This ready-made tool can deliver Walmart product reviews with just a few clicks.
To get started for free:
- Visit to Walmart Review Scraper
- Click ‘Get Started’
- Create an account or sign in with Google
- Click ‘Create New Project’
- Enter the project details, including project name and product review URLs/product codes
- Click ‘Gather Data’ and wait for the scraper to finish
- Go to ‘My Projects’ and download the extracted data
Advanced Features
In addition to no-code data extraction, ScrapeHero Cloud also provides premium services:
- Schedules: Set up your scraper to execute automatically at specified intervals.
- Integrations: Connect various cloud storage providers to save the extracted data automatically.
- API: Obtain an API for easy integration into your workflow.
Need Walmart product details instead of reviews? Checkout Walmart product details scraper.
Why Use a Web Scraping Service?
Python requests and BeautifulSoup are great libraries for scraping Walmart reviews; the requests library fetches the HTML source code, and BeautifulSoup parses it. However, the limitations mentioned above can increase your workload. If your primary goal is obtaining data, why scrape yourself?
A more efficient way would be to use ScrapeHero’s web scraping service.
ScrapeHero offers fully managed web scraping solutions that can handle large-scale data extraction efficiently while taking care of legalities.



