

The dynamic nature of Yelp’s website can make web scraping Yelp reviews tricky. However, you can still scrape Yelp reviews using browser automation libraries that can execute JavaScript.
This tutorial shows you how to scrape Yelp using Python with Selenium, a powerful browser automation library.
How to Scrape Yelp Reviews: The Environment
This script uses two external Python libraries: Selenium and BeautifulSoup. Selenium enables you to navigate the Yelp website, run JavaScript, and extract the HTML code of the review page, while BeautifulSoup helps parse this code to extract the review data.
You can install both of the libraries using Python’s package manager pip.
pip install beautifulsoup4 seleniumIn addition to these libraries, this code also uses Python’s built-in packages: json and time. The json module allows you to handle JSON data, including saving it as a file; the time module allows you to implement waits for HTML elements to load properly.
How to Scrape Yelp Reviews: The Data Extracted
This tutorial scrapes five key data points from each review on Yelp:
- Reviewer’s name
- Reviewer’s address
- Rating
- Comment
- Review date
You’ll need to analyze the HTML source code of the review page to identify how to locate the elements containing these data points. Use developer tools to do so. Right-click on a data point, click ‘Inspect,’ and look for unique attributes.
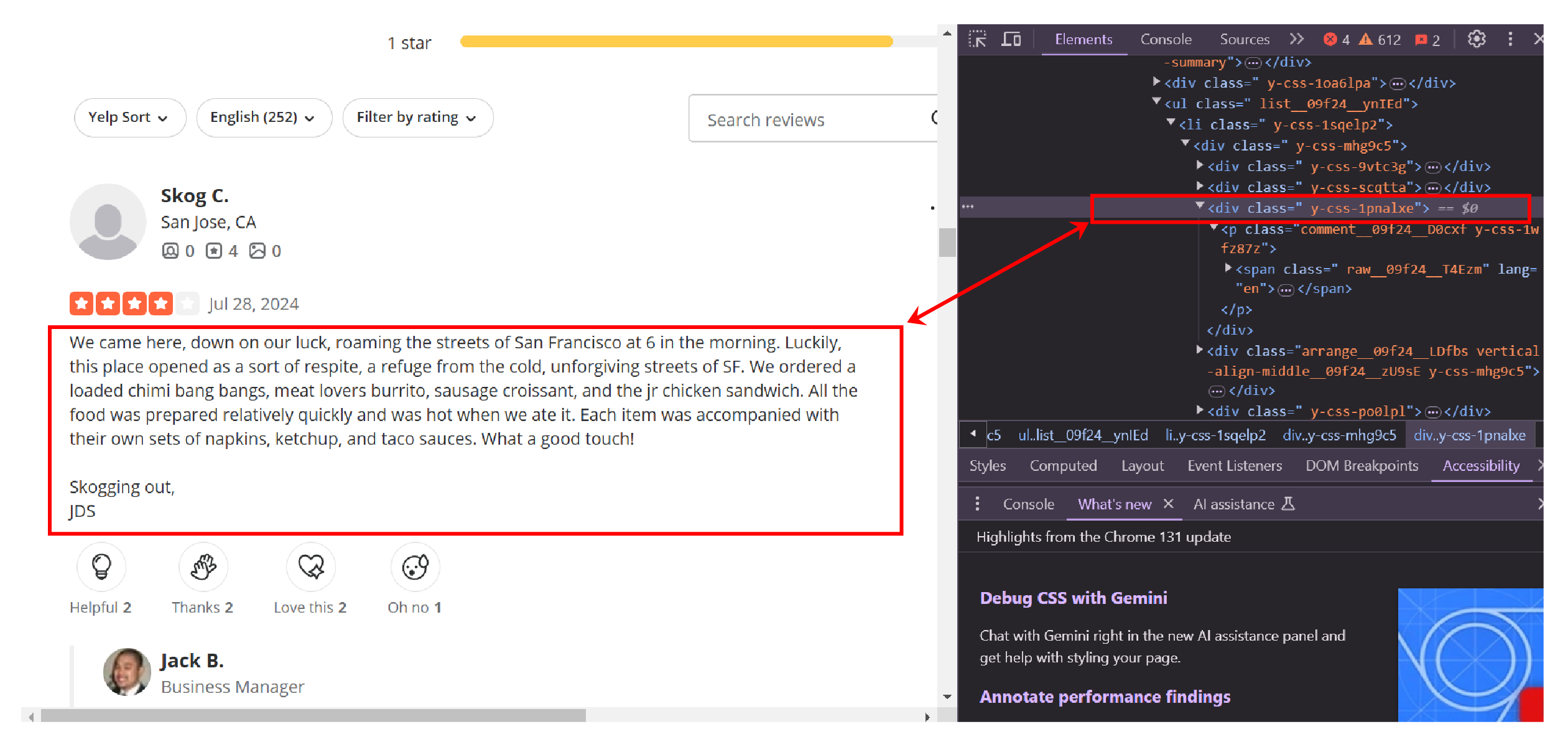
How to Scrape Yelp Reviews: The Code
After understanding the attributes of the elements holding the required data, you can start writing your code.
Start by importing the necessary packages.
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from time import sleep
import json
The above code doesn’t import the entire Selenium library. Because, for a basic Selenium web scraping, you only need to import two of its modules: webdriver and By
- The webdriver module has methods to control the browsers
- The By module lets you specify how to locate elements (XPath, by class, by ID, etc.)
Selenium has several automation indicator flags. You need to disable them to keep your scraper under the radar on Yelp. For Chrome, create a ChromeOptions() object and add arguments related to the flags.
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)Next, launch the Selenium browser using webdriver.Chrome() with your options object as an argument.
browser = webdriver.Chrome(options=options)You can then navigate to Yelp’s review page using the get() method.
browser.get(‘https://www.yelp.com/biz/the-st-regis-san-francisco-san-francisco’)After loading the page, scrape the details. However, the reviews span multiple pages, so you’ll need to loop through each one and extract reviews. Using input(), prompt the user for the maximum number of pages to scrape.
max_pages = 1Use this value as a range for a loop that starts by waiting 10 seconds for review elements to load.
for _ in range(int(max_pages)):
sleep(10)Then, the loop retrieves the page’s HTML source code using the page_source attribute and passes it to BeautifulSoup for parsing.
html = browser.page_source
soup = BeautifulSoup(html,'lxml')The next step is to locate review elements, which are all inside a div element with the id reviews. You can locate the div element using BeautifulSoup’s find method.
review_div = soup.find('div',{'id':'reviews'})To extract all the review elements, use find_all().
reviews = review_div.find_all('li', {'class':'y-css-1sqelp2'})Once all the review elements are located, iterate through them to find the necessary details:
- User name and address from a div element with class ‘user-passport-info’
- Rating from the aria-label of a div element of class ‘y-css-dnttlc’
- Date from a span element of the class ‘y-css-1d8mpv1’
- Review text from a p element.
user = review.find('div',{'class':'user-passport-info'})
name = user.span.text
address = user.div.text
rating = review.find('div',{'class':'y-css-dnttlc'})['aria-label']
date = review.find('span',{'class':'y-css-1d8mpv1'}).text
comment = review.p.textFinally, append the extracted data as a dict to your previously defined list and locate and click the link to the next page before repeating the loop. This process goes on until the code covers all the review elements.
review_data.append(
{
'Name':name,
'Address':address,
'Rating':rating,
'Date':date,
'Comment':comment
}
browser.find_element(By.XPATH,'//a[@aria-label="Next"]').click()After finishing the loop, save the extracted data in a JSON file using json.dump().
with open(f'{name}.json','w',encoding='utf-8') as f:
json.dump(review_data,f,indent=4,ensure_ascii=False)You can also modify this code to use a CSV file for the review URLs, allowing you to extract reviews of multiple products using a single script.
To do that, encapsulate your current logic into a function scrape_yelp_reviews() that accepts a URL.
You can then read your CSV file using Pandas and iterate through each URL in it, calling scrape_yelp_review() with each URL as an argument.
if __name__=="__main__":
urls = pandas.read_csv('yelp.csv',encoding='utf-8')
for url in urls['url']:
scrape_yelp_review(url)The scraped Yelp reviews would look like this:
{
"Name": "Name N.",
"Address": "San Diego, CA",
"Rating": "5 star rating",
"Date": "Oct 7, 2024",
"Comment": "No words will be enough to describe this bed and breakfast. My experiences were great. They have friendly staff, clean rooms, and well decorated common areas. You can also enjoy the Inn’s book collection."
}Here’s the complete code for Yelp data scraping:
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from time import sleep
import json, pandas
def scrape_yelp_review(link):
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=options)
browser.get(link)
review_data = []
max_pages = 1
for _ in range(int(max_pages)):
sleep(10)
html = browser.page_source
soup = BeautifulSoup(html,'lxml')
review_div = soup.find('div',{'id':'reviews'})
reviews = review_div.find_all('li', {'class':'y-css-1sqelp2'})
for review in reviews:
try:
user = review.find('div',{'class':'user-passport-info'})
name = user.span.text
address = user.div.text
rating = review.find('div',{'class':'y-css-dnttlc'})['aria-label']
date = review.find('span',{'class':'y-css-1d8mpv1'}).text
comment = review.p.text
review_data.append(
{
'Name':name,
'Address':address,
'Rating':rating,
'Date':date,
'Comment':comment
}
)
except Exception as e:
print(e)
try:
browser.find_element(By.XPATH,'//a[@aria-label="Next"]').click()
except:
print(f'No more pages')
continue
name = link.split('/')[4]
with open(f'{name}.json','w',encoding='utf-8') as f:
json.dump(review_data,f,indent=4,ensure_ascii=False)
if __name__=="__main__":
urls = pandas.read_csv('yelp.csv',encoding='utf-8')
for url in urls['url']:
scrape_yelp_review(url)
Code Limitations
While the code shown in this tutorial can scrape Yelp reviews, there are some limitations:
- It doesn’t use advanced techniques—such as proxy rotation—to avoid anti-scraping measures, making it unsuitable for large-scale web scraping.
- You must monitor Yelp’s website for changes in HTML structure and update your code accordingly, or it will fail to extract Yelp reviews.
Yelp Review Scraper: An Alternative
If you want a no-code solution for scraping Yelp reviews, check out ScrapeHero Cloud’s Yelp Review Scraper. This ready-to-use cloud scraper can deliver high-quality Yelp reviews with few clicks; here’s how to get started for free:
- Go to Yelp Review Scraper and sign in.
- Click on ‘Create New Project’
- Name your project and paste the URLs of Yelp business listings.
- Click ‘Gather Data’
The scraper will begin collecting Yelp reviews. Once it’s finished, you can download the extracted reviews from ‘My Projects’ under ‘Project’ on the left pane.
Additional Features
Besides no-code scraping, ScrapeHero Cloud also allows you to
- Set your scraper to run at regular intervals.
- Link your cloud storage to have the extracted data sent directly there.
- Integrate the scraper into your workflow using an API.
Why Use a Web Scraping Service
You can scrape Yelp reviews yourself using Python libraries like Selenium and BeautifulSoup. However, if you are only interested in getting reviews, why not consider a web scraping service?
A web scraping service like ScrapeHero can handle all the technicalities, including negotiating anti-scraping measures and monitoring your target website for changes.
ScrapeHero is an enterprise-grade web scraping service provider capable of building high-quality scrapers and crawlers.



