

This article explores web scraping Zillow data using coding and no-code methods. This could effectively export real estate data from Zillow to Excel or other formats for easier access and use.
There are three methods to scrape Zillow data:
- Zillow data scraping with coding: Building a web scraper in Python or JavaScript
- Zillow data scraping without coding: Using the ScrapeHero Cloud’s Zillow Scraper, a no-code scraping tool
ScrapeHero Cloud offers you ready-made web crawlers and real-time APIs, which are the easiest way to extract data from websites and download it into spreadsheets with a few clicks.

Building a Zillow Data Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Zillow using either Python or Javascript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One key advantage of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or Beautiful Soup to build a Zillow Scraper without using a browser or a browser automation library. However, bypassing the anti-scraping mechanisms implemented can be challenging and is beyond the scope of this article.
Here are the steps to scrape Zillow data using Playwright:
Step 1: Choose Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
JavaScript
npm install playwright@latestPython
pip install playwright
# to download the necessary browsers
playwright installStep 3: Write your code to emulate browser behavior and extract the desired data from Zillow using the Playwright API. You can use the code provided below:
JavaScript
const { chromium, firefox } = require('playwright');
const fs = require('fs');
const zipcode = "10001";
const maxPagination = 2;
const proxyServer = "http://:";
/**
* Save data as list of dictionaries
as json file
* @param{object}data
*/
function saveData(data) {
let dataStr = JSON.stringify(data, null, 2)
fs.writeFile("zillow_data_js.json", dataStr, 'utf8', function (err) {
if (err) {
console.log("An error occurred while writing JSON Object to File.");
return console.log(err);
}
console.log("JSON file has been saved.");
});
}
/**
* The data extraction function used to extract
necessary data from the element.
* @param{HtmlElement}innerElement
* @returns
*/
async function extractData(innerElement) {
async function extractData (data) {
let count = await data.count();
if (count) {
return await data.innerText()
}
return null
};
const xpathPrice = "//span[@class='srp__sc-16e8gqd-1 jLQjry']"
const xpathBeds = "//abbr[text()='bds' or text() = 'bd']/../b"
const xpathBath = "//abbr[text()='ba']/../b"
const xpathSqft = "//abbr[text()='sqft']/../b"
const xpathAddr = "//address"
// Extracting necessary data
let price = innerElement.locator(xpathPrice);
price = await extractData(price);
let beds = innerElement.locator(xpathBeds)
beds = await extractData(beds);
let bath = innerElement.locator(xpathBath)
bath = await extractData(bath);
let sqft = innerElement.locator(xpathSqft)
sqft = await extractData(sqft);
let addr = innerElement.locator(xpathAddr)
addr = await extractData(addr);
return {"price": price, "beds": beds, "bath": bath, "sqft": sqft, "addr": addr}
};
/**
* The main function initiates a browser object and handles the navigation.
*/
async function run() {
const browser = await firefox.launch({headless: false});
const context = await browser.newContext();
const page = await context.newPage();
// Navigating to the home page
await page.goto('https://www.zillow.com/', { waitUntil: 'load' });
await page.locator("xpath=//input[contains(@placeholder, 'Enter an address')]").type(zipcode, {delay: 200});
await page.locator("xpath=//button[@id='search-icon']").click();
// Clearing popup
await page.waitForSelector("xpath=//button[text()='Skip this question']", {timeout: 60000});
await page.locator("xpath=//button[text()='Skip this question']").click()
await page.waitForLoadState("load")
// Checking the results count
const noResultsFound = await page.locator("xpath=//h5[text()='No matching results']").count();
if (noResultsFound) {
console.log(f`No results for the zipcode : ${zipcode}`);
return
};
const totalResultCount = await page.locator("xpath=//span[@class='result-count']").innerText();
console.log(`Total results found - ${totalResultCount} for zipcode - ${zipcode}`);
let data = [];
for (let pageNum = 0; pageNum<maxPagination; pageNum++) {
await page.waitForLoadState("load");
await page.waitForTimeout(10);
let allVisibleElements = page.locator("xpath=//div[@id='grid-search-results']//li[contains(@class, 'ListItem')]");
allVisibleElementsCount = await allVisibleElements.count()
for (let index= 0; index < allVisibleElementsCount; index++) {
await page.waitForTimeout(2000);
await page.waitForLoadState("load");
let innerElement = await allVisibleElements.nth(index);
await innerElement.hover();
innerElement = await allVisibleElements.nth(index);
let dataToSave = await extractData(innerElement);
data.push(dataToSave);
};
let nextPage = page.locator(`//a[@title='Next page' and @aria-disabled="false"]`);
await nextPage.hover();
if (await nextPage.count()) {
await nextPage.click();
}
else {break};
};
saveData(data);
await context.close();
await browser.close();
};
run();Python
import asyncio
import json
import logging
from playwright.async_api import Playwright, async_playwright
ZIPCODE = "10001"
MAX_PAGINATION = 2
PROXY_SERVER = "http://:"
def save_as_json(data: list):
"""
Save data as list of dictionaries
as json file
:param data: List of dict
:return: None
"""
with open("zillow_data_1.json", "w") as file:
json.dump(data, file, indent=4)
async def extract_data(inner_element) -> dict:
"""
The data extraction function used to extract
necessary data from the element.
:param inner_element: inner listing element
:return: data as dict
"""
# initializing x-paths
xpath_price = "//span[@class='srp__sc-16e8gqd-1 jLQjry']"
xpath_beds = "//abbr[text()='bds' or text() = 'bd']/../b"
xpath_bath = "//abbr[text()='ba']/../b"
xpath_sqft = "//abbr[text()='sqft']/../b"
xpath_addr = "//address"
# Extracting necessary data
price = inner_element.locator(xpath_price)
price = await price.inner_text() if await price.count() else None
beds = inner_element.locator(xpath_beds)
beds = await beds.inner_text() if await beds.count() else None
bath = inner_element.locator(xpath_bath)
bath = await bath.inner_text() if await bath.count() else None
sqft = inner_element.locator(xpath_sqft)
sqft = await sqft.inner_text() if await sqft.count() else None
addr = inner_element.locator(xpath_addr)
addr = await addr.inner_text() if await addr.count() else None
return {"price": price, "beds": beds, "bath": bath, "sqft": sqft, "addr": addr}
async def run(playwright: Playwright) -> None:
"""
The main function initiate a browser object and handle the
navigation.
:param playwright: Playwright object
:return: None
"""
# initializing x-paths
xpath_no_results = "//h5[text()='No matching results']"
xpath_total_results = "//span[@class='result-count']"
xpath_next_page = """//a[@title='Next page' and @aria-disabled="false"]"""
xpath_text_box = "//input[contains(@placeholder, 'Enter an address')]"
xpath_search_button = "//button[@id='search-icon']"
xpath_popup = "//button[text()='Skip this question']"
xpath_results_elements = (
"//div[@id='grid-search-results']//li[contains(@class, 'ListItem')]"
)
# Initializing the browser and creating a new page.
browser = await playwright.firefox.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
# Navigating to home page
await page.goto("https://www.zillow.com/", wait_until="domcontentloaded")
await page.wait_for_load_state(timeout=60000)
# Entering zipcode and hitting search button
await page.locator(xpath_text_box).type(ZIPCODE, delay=200)
await page.locator(xpath_search_button).click()
# Clearing the POPUP
await page.wait_for_selector(xpath_popup, timeout=60000)
await page.locator(xpath_popup).click()
await page.wait_for_load_state(timeout=60000)
# Checking if no results
no_results_found = await page.locator(xpath_no_results).count()
if no_results_found:
logging.warning(f"No results for the zipcode : {ZIPCODE}")
return
total_results_count = await page.locator(xpath_total_results).inner_text()
logging.warning(
f"Total results found - {total_results_count} for zipcode - {ZIPCODE}"
)
# List for saving data
data = []
# Paginating through each page
for page_number in range(MAX_PAGINATION):
# Waiting to finish the loading
await page.wait_for_load_state("load")
# Extracting the elements
all_visible_elements = page.locator(xpath_results_elements)
all_visible_elements_count = await all_visible_elements.count()
for element_index in range(all_visible_elements_count):
# Hovering the element to load the price
inner_element = all_visible_elements.nth(index=element_index)
await inner_element.hover()
inner_element = all_visible_elements.nth(index=element_index)
data_to_save = await extract_data(inner_element)
data.append(data_to_save)
next_page = page.locator(xpath_next_page)
await next_page.hover()
if not await next_page.count():
break
# Clicking the next page button
await next_page.click()
save_as_json(data)
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())This code uses the Playwright library in Python and JavaScript to scrape listings based on zipcodes from Zillow.
The corresponding scripts have two main functions:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Zillow, fills in a search query, clicks the search button, and waits for the results to be displayed on the page.
The extract_details function is then called to extract the listings and store the data in a json file. - extract_data function: This function takes a Playwright page object as input and returns a list of dictionaries containing the listing’s details. The details include each listing’s price, number of bedrooms and bathrooms, square footage, and the address.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Zillow script you just executed would be created.
Step 4: Run your code and collect the scraped data from Zillow.
View the complete code for scraping Zillow on GitHub.
Using No-Code Zillow Scraper by ScrapeHero Cloud
ScrapeHero Cloud’s Zillow data scraping tool allows users to pull data quickly without writing any code. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the Zillow scraper.
1. Sign up or log in to your ScrapeHero Cloud account.
2. Go to the Zillow Scraper by ScrapeHero Cloud.
3. Click the Create New Project button.
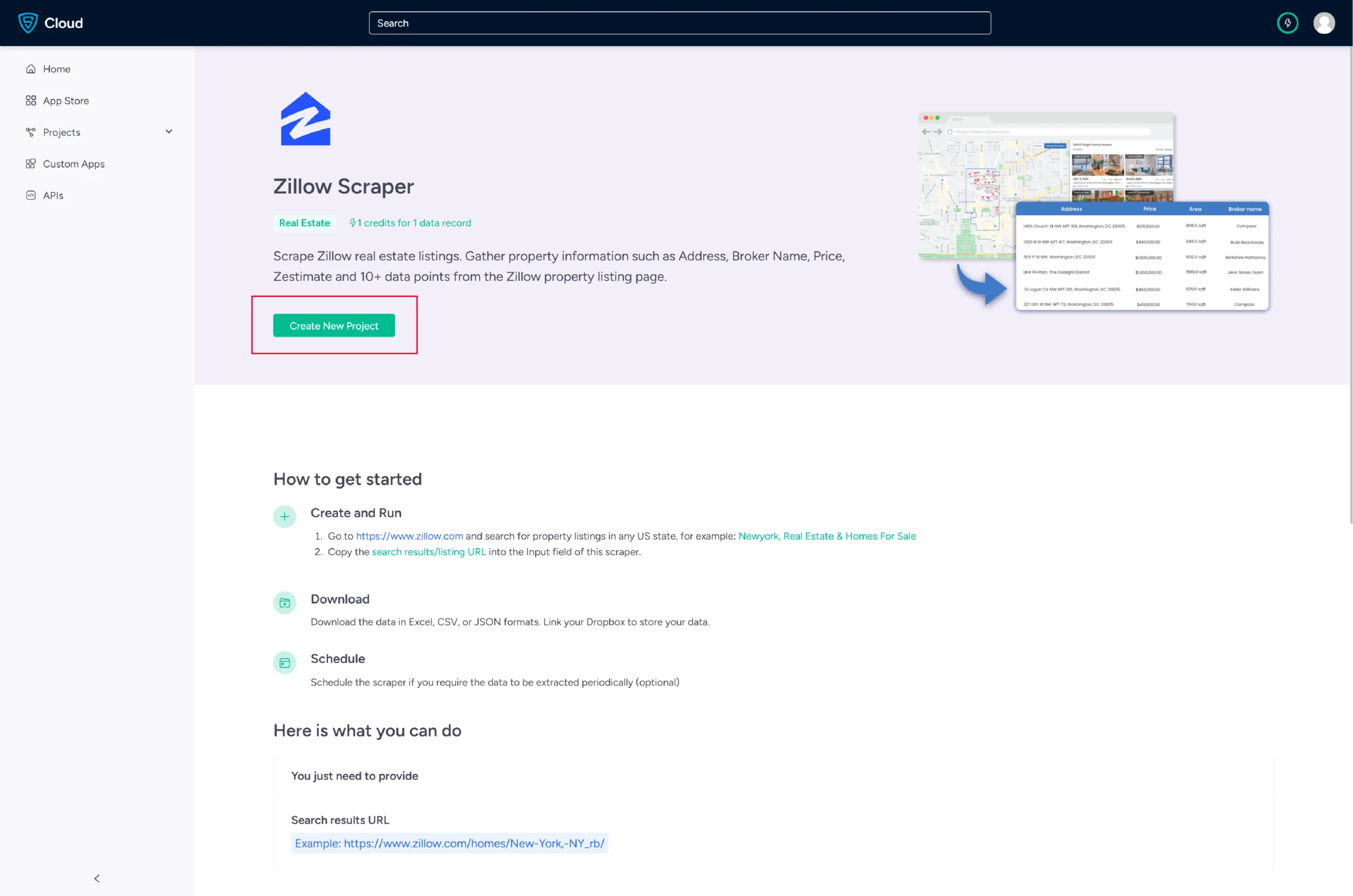
4. To scrape the details, you need to provide the Zillow search results URL for a specific search query.
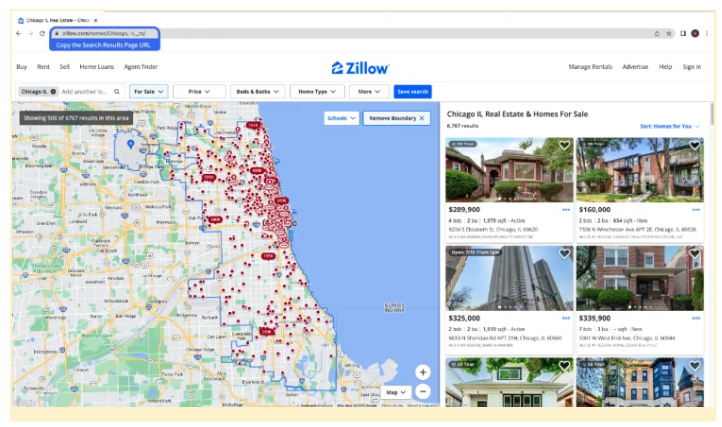
a. You can get the URL from the Zillow search results page.
5. In the field provided, enter a project name, Zillow URL and the maximum number of records you want to gather. Then, click the Gather Data button to start the scraper.

6. The scraper will start fetching data for your queries, and you can track its progress under the Projects tab.
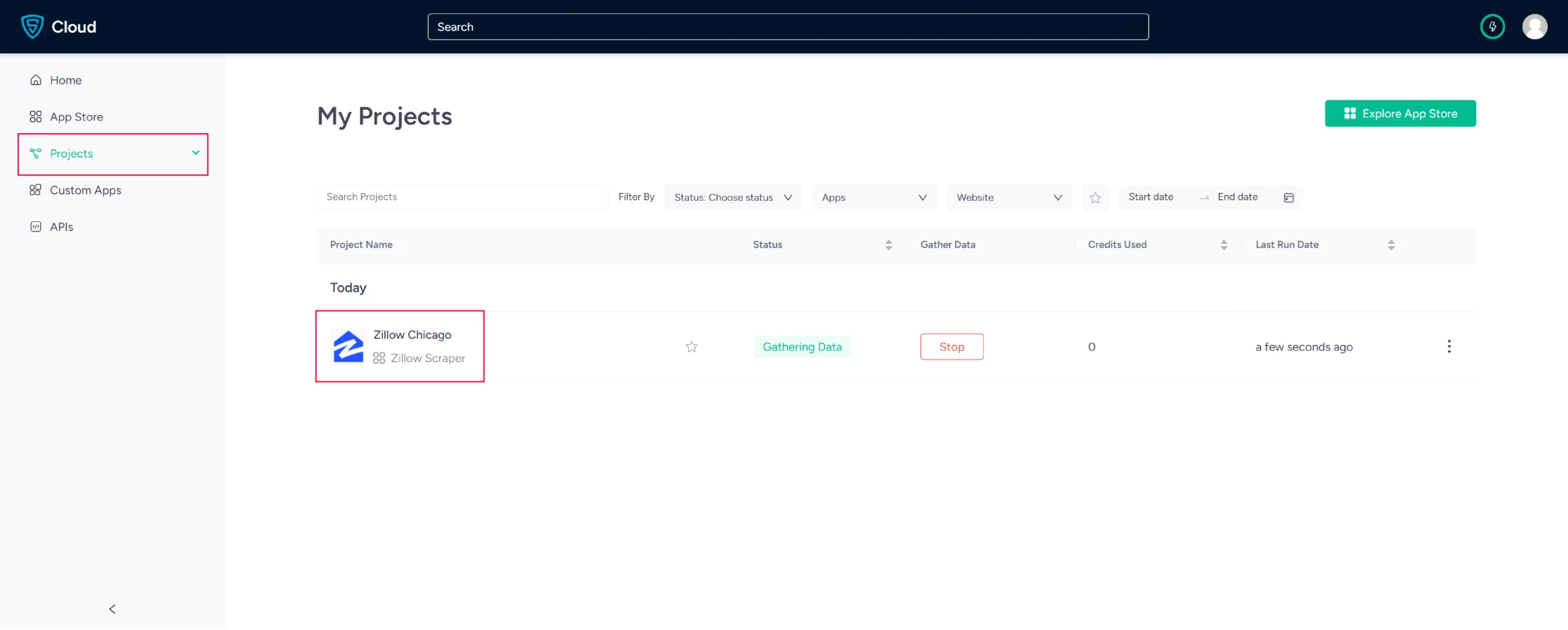
7. Once it is finished, you can view the data by clicking on the project name. A new page will appear, and under the Overview tab, you can see and download the data.
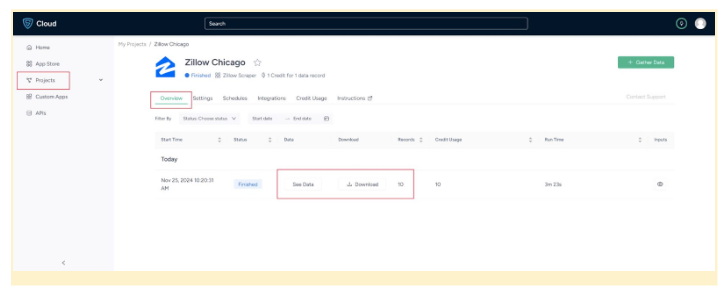
8. You can also pull Zillow data into a spreadsheet from here. Just click on Download Data, select Excel, and open the downloaded file using Microsoft Excel.
Uses Cases of Zillow Housing Data
If you’re unsure as to why you should scrape Zillow, here are a few use cases for web scraping Zillow where this data would be helpful:
-
Real Estate Investment Strategy
Data scraped from Zillow for a particular location or zip code, such as average property prices, historical data on property values, and neighborhood characteristics, can help investors identify potential areas for profitable investment.
Investors can also gain insights into market trends and predict future property price variations. This assists in risk mitigation and increases the probability of good returns on their investment.
-
Home Buying Decisions
Potential buyers can use the data to compare prices of similar properties in an area of choice, understand the value trends, and even study the proximity of amenities like schools, shopping areas, and parks.
This information can assist in making informed home-buying decisions that are both financially sound and compatible with the buyer’s lifestyle needs.
-
Real Estate Agents and Brokers
Real estate professionals can utilize Zillow data to understand a specific market segment comprehensively. This includes understanding the average property pricing, buyer preferences, historical property sales data, and more in a particular location.
With this information, agents can effectively match their properties with potential buyers and set competitive prices for the properties they represent.
-
Property Developers and Builders
For those constructing new properties, Zillow data can provide insights into the types of properties in demand within a specific zip code or location. By understanding trends in housing demand, developers can make strategic decisions on the kind of properties to build.
For instance, if there is a high demand for homes with solar panels in a particular area, developers could incorporate them into their new projects.
-
Urban Planning and Policy-Making
Entities involved in urban planning and housing policy can benefit from Zillow data. Understanding housing market trends, including property pricing, demand, and availability in specific zip codes, can inform decisions on housing policies and zoning laws.
For instance, if data shows a lack of affordable housing in a particular area, policymakers might work to incentivize developers to create more affordable housing options.
Frequently Asked Questions
Zillow scraping refers to extracting real estate data from the real estate listings available on the Zillow website. You can efficiently scrape Zillow real estate data displayed on this prominent online platform for property analysis.
Beginners can scrape Zillow data without code. With tools such as ScrapeHero Cloud, tailored to Zillow’s anti-scraping measures, you can efficiently perform web scraping for Zillow. You can also use coding frameworks like Playwright to get real estate data from Zillow.
To avoid being blocked by Zillow, it is better to implement strategies such as rotating IP addresses, mimicking human browsing behavior, and adhering to Zillow’s terms of service.
You can scrape data, including Address, Broker Name, Price, Zestimate, and other data points from the Zillow property listing page.
ScrapeHero provides a comprehensive pricing plan for both Scrapers and APIs. To know more about the pricing, visit our pricing page.
The legality of web scraping depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.



