

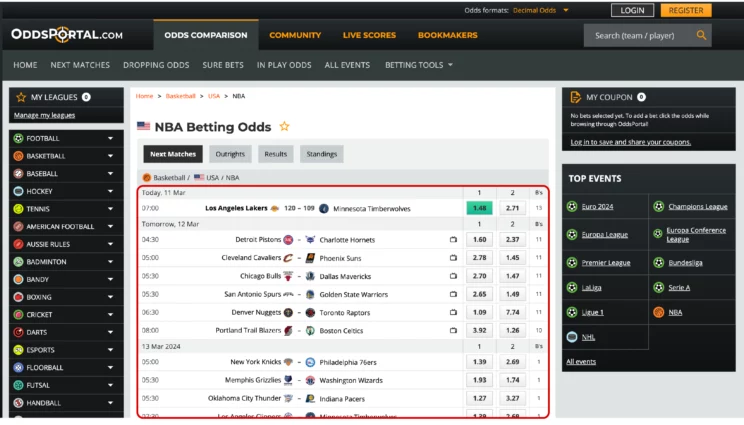
Odds Portal is a website that displays betting odds for various sports, including basketball and football. Based on these, you can make strategic betting decisions; however, manually getting the data is impractical. Scraping oddsportal.com will be a better approach.
The only problem is that Odds Portal is a dynamic website. You can’t scrape betting odds from oddsportal.com with HTTP requests as they can’t render JavaScript. Therefore, you must use browser automation libraries, like Selenium, which has methods for web scraping dynamic content from Odds Portal.
Set up the Environment for Scraping oddsportal.com
This tutorial uses Selenium, which is an external Python library used for web scraping. Therefore, you must install Selenium using Python pip.
pip install seleniumJSON and sleep are in-built Python modules, so you don’t need to install it.
The Code for Web Scraping Betting Odds
This tutorial will use the JSON module to write the extracted data after scraping oddsportal.com. Therefore, you must import both JSON and Selenium.
You need two modules from the Selenium library.
The WebDriver module is the main one that lets you launch the browser and interact with the website.
The other module is By, which has methods to specify how you will locate the element. For example, you will use XPaths here; therefore, you will use By.XPATH in the argument of find_elements().
You will also use the time module to tell the script to wait before moving on to the next step.
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
from time import sleep
import jsonIn this code, you first use the WebDriver module to launch a Chrome browser instance; you can also use other browsers, like Firefox and Safari.
driver = webdriver.Chrome()You can then use the get method to take the WebDriver to your target website, “https://www.oddsportal.com/basketball/usa/nba/.”
driver.get("https://www.oddsportal.com/basketball/usa/nba/")The page may take some time to load. Therefore, you must wait a little before trying to locate HTML elements; this is where you use the sleep() method of the time module.
sleep(5)You can now select each row using the XPath and find_elements() method; each row is a div element with the class “group-flex.”
gameRows = driver.find_elements(By.XPATH,'//div[@class="group flex"]')Once you find all the rows, you can extract their text as strings.
The code then creates an array from each string using the split() method. split() works by creating an array element with the part of the string before and after a separator. You pass the separator as its argument.
For example, if you want every new line to be an array element, you must call the method split(‘\n’) with the new line character as the argument.
Here also, the separator is a new line.
rowData = [row.text.split("\n") for row in gameRows]You can then grab the required details using the array index and save them into a dict object.
Note: The index for the required data may vary with the rows; you must consider this variation when you select the data. That is why the code below has the if-else expression; it checks the row structure.
In this example of web scraping, you will be extracting NBA betting odds from oddsportal.com. You will scrape three data points for each match:
- betting odds of team 1
- betting odds of team 2
- the number of bookmakers providing these odds
The code adds data to the dict in every iteration using the update() method.
for row in rowData:
if row[2] == "\u2013":
try:
data.update({row[1]+" vs. "+row[3]:{
"Team1_Odds":row[4],
"Team2_Odds":row[5],
"No. of Bookmakers":row[6]
}})
except:
continue
else:
try:
data.update({row[1]+" vs. "+row[5]:{
"Team1_Odds":row[6],
"Team2_Odds":row[7],
"No. of Bookmakers":row[8]
}})
except:
continueFinally, you can save the dict object as a JSON file using json.dump().
with open("NBA.json","w") as jsonFile:
json.dump(data,jsonFile,indent=4)
Here is the full code for scraping oddsportal.com
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
from time import sleep
import json
driver = webdriver.Chrome()
driver.get("https://www.oddsportal.com/basketball/usa/nba/")
sleep(5)
gameRows = driver.find_elements(By.XPATH,'//div[@class="group flex"]')
data = {}
rowData = [row.text.split("\n") for row in gameRows]
print(len(gameRows))
for row in rowData:
if row[2] == "\u2013":
try:
data.update({row[1]+" vs. "+row[3]:{
"Team1_Odds":row[4],
"Team2_Odds":row[5],
"No. of Bookmakers":row[6]
}})
except:
continue
else:
try:
data.update({row[1]+" vs. "+row[5]:{
"Team1_Odds":row[6],
"Team2_Odds":row[7],
"No. of Bookmakers":row[8]
}})
except:
continue
with open("NBA.json","w") as jsonFile:
json.dump(data,jsonFile,indent=4)And here is the NBA betting odds extracted from oddsportal.com.
{
"Memphis Grizzlies vs. Charlotte Hornets": {
"Team1_Odds": "2.14",
"Team2_Odds": "1.74",
"No. of Bookmakers": "15"
},
"New Orleans Pelicans vs. Cleveland Cavaliers": {
"Team1_Odds": "1.45",
"Team2_Odds": "2.80",
"No. of Bookmakers": "15"
},
"Dallas Mavericks vs. Golden State Warriors": {
"Team1_Odds": "1.28",
"Team2_Odds": "3.78",
"No. of Bookmakers": "15"
},
"Portland Trail Blazers vs. Atlanta Hawks": {
"Team1_Odds": "2.50",
"Team2_Odds": "1.54",
"No. of Bookmakers": "15"
},
"Sacramento Kings vs. Los Angeles Lakers": {
"Team1_Odds": "2.15",
"Team2_Odds": "1.73",
"No. of Bookmakers": "15"
},
"Boston Celtics vs. Phoenix Suns": {
"Team1_Odds": "1.44",
"Team2_Odds": "2.79",
"No. of Bookmakers": "13"
},
"Chicago Bulls vs. Los Angeles Clippers": {
"Team1_Odds": "3.11",
"Team2_Odds": "1.37",
"No. of Bookmakers": "13"
},
"Houston Rockets vs. Washington Wizards": {
"Team1_Odds": "1.27",
"Team2_Odds": "3.82",
"No. of Bookmakers": "13"
},
"Milwaukee Bucks vs. Philadelphia 76ers": {
"Team1_Odds": "1.26",
"Team2_Odds": "3.87",
"No. of Bookmakers": "13"
},
"Oklahoma City Thunder vs. Dallas Mavericks": {
"Team1_Odds": "1.20",
"Team2_Odds": "4.53",
"No. of Bookmakers": "13"
},
"Portland Trail Blazers vs. New York Knicks": {
"Team1_Odds": "4.76",
"Team2_Odds": "1.19",
"No. of Bookmakers": "13"
},
"Detroit Pistons vs. Miami Heat": {
"Team1_Odds": "2.41",
"Team2_Odds": "1.48",
"No. of Bookmakers": "1"
},
"Toronto Raptors vs. Orlando Magic": {
"Team1_Odds": "2.26",
"Team2_Odds": "1.54",
"No. of Bookmakers": "1"
},
"San Antonio Spurs vs. Denver Nuggets": {
"Team1_Odds": "4.04",
"Team2_Odds": "1.18",
"No. of Bookmakers": "1"
},
"Utah Jazz vs. Atlanta Hawks": {
"Team1_Odds": "1.74",
"Team2_Odds": "1.93",
"No. of Bookmakers": "1"
},
"Golden State Warriors vs. Dallas Mavericks": {
"Team1_Odds": "-",
"Team2_Odds": "-",
"No. of Bookmakers": "2"
}
}
Code Limitation
This code can scrape the dynamically generated NBA odds but might fail for other match odds. Reason: The structure of the odds table may vary with each sport. That means the code is unsuitable for web scraping betting odds on a large scale from Odds Portal; you must add more code.
Moreover, the structure of the NBA page itself can change. You then need to update the code to match the new HTML structure.
Wrapping Up
Dynamic website scraping using Python is possible; you can use the Selenium library. With Selenium, you can visit the website using get() and extract data using find_elements().
Then, you can save it in your preferred file format, like JSON.
However, you must analyze the target website to figure out the XPaths necessary to locate the HTML elements. And these XPaths depend on the structure. Therefore, you must find the new XPaths every time Odds Portal changes its HTML structure, which might be tedious.
If you don’t want to code yourself, you can try ScrapeHero services. ScrapeHero is a full-service web scraping service provider. We can build enterprise-grade web scrapers customized to your needs, and our massive browser farms can scrape dynamic web content.
Frequently Asked Questions
Before scraping a website, you must check these:
- Is the data public? You can only scrape public data. They won’t be behind a login page or a pay wall. Scraping public data doesn’t violate privacy laws or terms of service, but scraping personal information without consent is illegal.
- Does robots.txt allow access? Robots.txt tells you what you can scrape on the website. Not considering it can get you blocked.
- Are you scraping a dynamic website? Dynamic websites need to render JavaScript before displaying information. You can’t scrape such websites with HTTP requests. Hence, checking whether or not the website is dynamic will tell you what libraries to use.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



