
Hotels.com allows you to find hotels, their prices, addresses, and other details. However, to analyze hotel prices, you need a large data set, which is impractical to obtain manually. Therefore, a more practical approach is web scraping hotel prices.
In this tutorial, you can learn web scraping with Selenium Python, a browser automation library.
Set Up The Environment
You will use Python to run Selenium in this tutorial, although it is also available in other languages. Selenium can control browsers using its web driver module, making it great for scraping dynamic websites.
You can install Selenium with pip. Besides selenium, this tutorial also uses Pandas, which allows you to manipulate structured data.
You will use Pandas to write the extracted data into a CSV file. Python pip can also install Pandas.
pip install pandas seleniumData Scraped from Hotels.com
This code will scrape four details from each hotel listing:
- the name,
- the price,
- the rating,
- the address
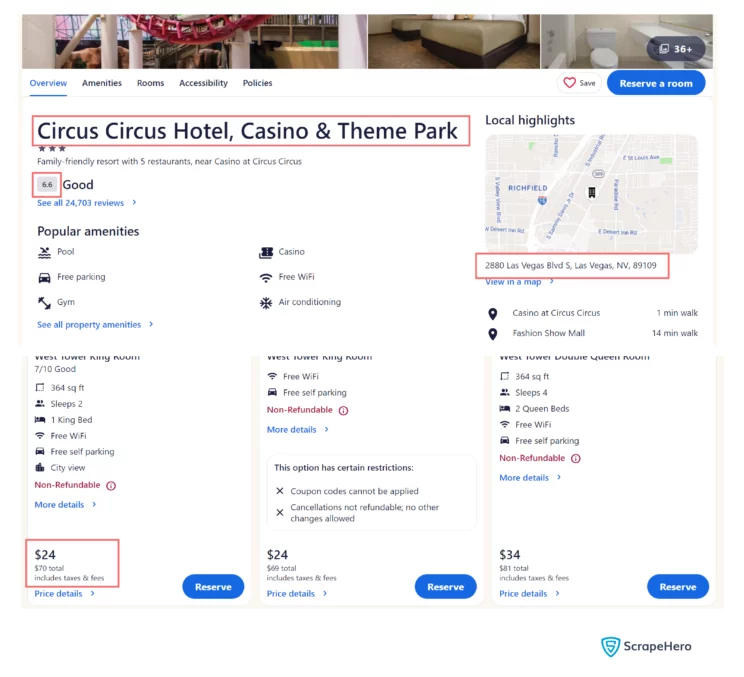
To locate these via Selenium, you must analyze the website structure and figure out the XPath or CSS selectors. You may also use only classes and IDs to select the element, but they may not always work.
Scrape Hotel Prices: The Code

You will use three Python libraries: selenium, Pandas, and time. You must import these.
The time module instructs the program to wait for some time before moving on to the next step. Otherwise, the next step may fail if it depends on the current step’s data.
Note: This code imports Selenium modules separately for convenience.
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandasInstead of directly writing a script, you will write a function parse(). Then, you will call parse().
In the parse() function, you will start the Chrome browser and go to the target url, hotels.com.
response = webdriver.Chrome()
response.get(url)Hotels.com has an interactive button that you must click to enter the location. You can find this button with its XPath using the find_element() method.
Then, you can use the click() method to click on it, which will open a search box.
location = response.find_element(By.XPATH,'//button[contains(@aria-label,"to")]')
location.click()Next, you must find the search box and send the location with the send_keys() method. The send_keys() method can also send keys like return; here, you will use return after filling in the location to submit it.
searchKeyElement = response.find_element(By.XPATH,'//input[contains(@id,"destination")]')
searchKeyElement.send_keys(searchKey)
searchKeyElement.send_keys(Keys.RETURN)Now, you must press the search button. As you did above, locate the element using the XPath and use click().
submitButton = response.find_element(By.XPATH,'//button[@type="submit"]')
submitButton.click()In this code, you will sort the list from low to high price, which is the second option. Therefore, search the dropdown element and use the down key using send_keys().
dropDownButton = response.find_element(By.XPATH,'//select[contains(@id,"sort-filter-dropdown-sort")]')
dropDownButton.send_keys(Keys.DOWN)
After you change the sort option, the website will take some time to sort. You must wait this long before the next step; this is where you use the sleep() method from the time module.
sleep(5)The above code makes the program wait 5 seconds before moving to the next line.
You can now search all the listings using the find_all method.
hotels = response.find_elements(By.XPATH,'//a[@class="uitk-card-link"]')
Then use a loop to extract data from each listing:
1. Click on it
for hotel in hotels[:10]:
hotel.click()2. Switch the webdriver’s focus to the new window
new_window = response.window_handles[1]
response.switch_to.window(new_window)3. Find and extract the elements (name, price, address, and rating)
hotelName = response.find_element(By.TAG_NAME,'h1').text
price = response.find_element(By.XPATH,"//div[@data-stid='price-summary']//span/div").text
rating = response.find_element(By.CLASS_NAME,"uitk-badge-base-text").text
address = response.find_element(By.XPATH,'//div[@class="uitk-text uitk-type-300 uitk-text-default-theme uitk-layout-flex-item uitk-layout-flex-item-flex-basis-full_width"]').text4. append it to a file variable
file.append(item)5. Close the new window and switch back to the listings page
response.close()
response.switch_to.window(response.window_handles[0])
6. Again, get all the hotel listings
hotels = response.find_elements(By.XPATH,'//a[@class="uitk-card-link"]')Finally, the function returns the file variable containing all the extracted data.
Then, you use Pandas to write the data to a CSV file.
file = parse('http://www.hotels.com')
df = pandas.DataFrame.from_dict(file)
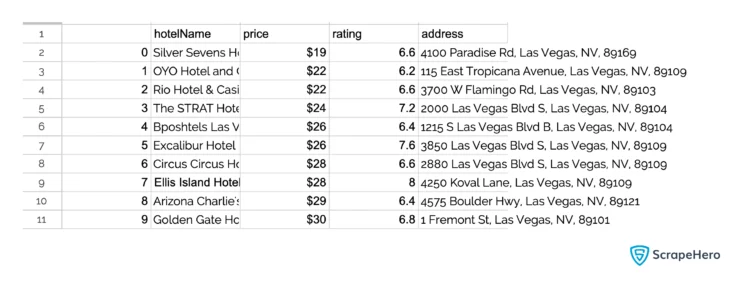
df.to_csv("hotels.csv")Here are the results of the data extraction.
Here is the full code to scrape hotel prices and other details from Hotels.com.
#!/usr/bin/env python
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import pandas
def parse(url):
searchKey = "Las Vegas" # Change this to your city
response = webdriver.Chrome()
response.get(url)
location = response.find_element(By.XPATH,'//button[contains(@aria-label,"Going to")]')
location.click()
searchKeyElement = response.find_element(By.XPATH,'//input[contains(@id,"destination")]')
searchKeyElement.send_keys(searchKey)
searchKeyElement.send_keys(Keys.RETURN)
submitButton = response.find_element(By.XPATH,'//button[@type="submit"]')
submitButton.click()
dropDownButton = response.find_element(By.XPATH,'//select[contains(@id,"sort-filter-dropdown-sort")]')
dropDownButton.send_keys(Keys.DOWN)
sleep(5)
hotels = response.find_elements(By.XPATH,'//a[@class="uitk-card-link"]')
file = []
print(len(hotels))
for hotel in hotels[:10]:
hotel.click()
sleep(10)
new_window = response.window_handles[1]
response.switch_to.window(new_window)
sleep(3)
hotelName = response.find_element(By.TAG_NAME,'h1').text
price = response.find_element(By.XPATH,"//div[@data-stid='price-summary']//span/div").text
rating = response.find_element(By.CLASS_NAME,"uitk-badge-base-text").text
address = response.find_element(By.XPATH,'//div[@class="uitk-text uitk-type-300 uitk-text-default-theme uitk-layout-flex-item uitk-layout-flex-item-flex-basis-full_width"]').text
item = {
"hotelName":hotelName,
"price":price,
"rating":rating,
"address":address
}
file.append(item)
response.close()
response.switch_to.window(response.window_handles[0])
hotels = response.find_elements(By.XPATH,'//a[@class="uitk-card-link"]')
return file
if __name__ == '__main__':
file = parse('http://www.hotels.com')
df = pandas.DataFrame.from_dict(file)
df.to_csv("hotels.csv")Code Limitation
The primary limitation of web scraping with Selenium is that you need to find new XPaths whenever Hotels.com changes its structure. You have to reanalyze the HTML code and figure out the new XPaths.
The code is also unsuitable for large-scale data extraction, where you must consider potential anti-scraping measures.
Wrapping Up
You can scrape hotel data from Hotels.com using Selenium. Selenium has modules that allow you to visit the website and extract data using various methods, including XPaths and CSS selectors. However, you must remain updated with the website’s structure.
Moreover, enterprise-grade web scraping requires expensive browser farms that can run several simultaneous Selenium browser contexts and extract data. This requires a massive investment.
You can forget about all this if you choose ScrapeHero. We will handle all the backend tasks, including providing robust code and managing anti-scraping measures.
ScrapeHero Services include large-scale web scraping, product monitoring, and many more. We can get you high-quality data, including about airlines and hotels. Moreover, we can make custom web scrapers according to your specifications.
You can also check out the hotel lists in our data store; we may already have your required data.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


