

Bestbuy.com is a highly dynamic website that stores product details in its script tags. The website executes JavaScript, fetches the information from the tags, and displays it on the webpage.
Generally, you had to use an automated browser like Playwright to render JavaScript to extract from such dynamic websites. However, because the website stores in the script tags, web scraping Best Buy is possible by directly extracting information from those tags using HTTP requests.
The tutorial uses this method to scrape Best Buy for free using Python.
Data Scraped From Best Buy
This tutorial will scrape the following product details from Best Buy.
- Name
- Model
- Price
- Brand Name
- Description
- Specifications
- Ratings
- URL
Web Scraping Best Buy: The Environment
The code uses external Python libraries to run the code in this tutorial:
- Python requests: This library allows you to handle HTTP requests to fetch the HTML code of the target website.
- BeautifulSoup: BeautifulSoup lets you extract the required information very efficiently through its intuitive methods.
You can install the Python packages with pip
pip install requests bs4You also need a couple of packages inside the Python standard library. These do not require installation:
- The re module: This module helps you handle RegEx. It allows you to define a text pattern and search for it in a string.
- The json module: This module lets you handle JSON objects and files. You can create JSON objects from a string using the json module and save it as a JSON file.
If you want to skip the hassle of building a scraper from scratch for popular e-commerce websites, check out ScrapeHero Cloud for ready-made e-commerce web scrapers, which you can try for free.
Web Scraping Best Buy: The Code
Import all the packages mentioned in the previous section. In the case of BeautifulSoup, you import it from the bs4 library.
import requests as rs
from bs4 import BeautifulSoup as bs
import re
import jsonNext, define important headers to reduce the chance of Best Buy blocking your scraper. These headers present your request as one originating from a legitimate browser; you can define all the headers as a dict.
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
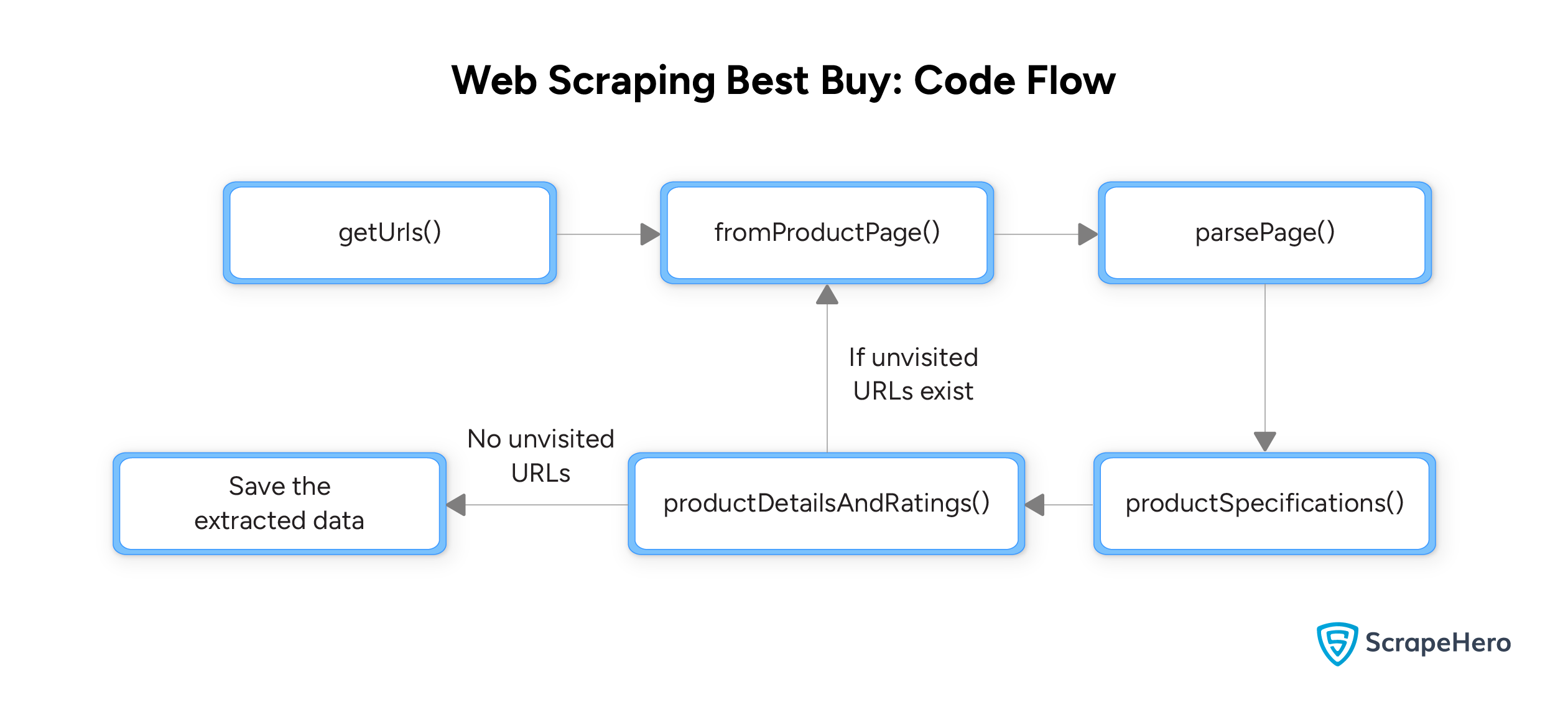
The tutorial uses several functions to structure the code:
- parsePage()
- getUrls()
- productSpecifications()
- productDetailsAndRatings()
- fromProductPage()
parsePage()
The function accepts the URL of a Best Buy search results page and uses the headers defined above to make an HTTP request to the URL.
response = rs.get(url,headers=headers)
The response to the request will have the HTML source code of BestBuy.com.
Next, the function parses the response text using BeautifulSoup, creating a BeautifulSoup object.
soup = bs(response.text, "lxml")
The function then returns this BeautifulSoup object.
soup = bs(response.text, "lxml")
getUrls()
The function getUrls() accepts a BeautifulSoup object. This object contains the parsed HTML source code from which you can extract URLs.
From this object, find all the li tags having the class ‘sku-item’; the li tags with this class hold the product information, including URLs. You can use BeautifulSoup’s find_all() method to get these tags.
products = soup.find_all('li',{'class':'sku-item'})The find_all() method gives you the tags as a list. You can iterate through this list to find URLs. To find a URL:
- Locate the anchor tag inside an h4 tag.
- Extract the URL from the ‘href’ attribute of the anchor tag.
anchorTag = product.h4.a
rawUrl = anchorTag['href']The extracted URL would be relative. That means you need to make them absolute by prefixing “https://bestbuy.com.”
url = rawUrl if "https://" in rawUrl else "https://bestbuy.com"+rawUrl+"&intl=nosplash"Next, append the cleaned URL to an array.
urls.append(url)
Finally, getUrls() returns the extracted URLs.
productSpecifications()
The function accepts a BeautifulSoup object and extracts product specifications.
It targets the keyword “shop-specifications.” The keyword will either be the script ID or inside the script tag’s text.
First, the function checks if the keyword is inside the ID. It
- Creates RegEx pattern
productScriptId = re.compile(r"shop-specifications.+") - Uses the pattern inside BeautifulSoup’s find method to find the script tag
productScript = page.find('script',{'id':productScriptId})
If the script tag exists, the function
- Creates a JSON object using the script tag’s text
productJson = json.loads(productScript.text) - Extracts the specifications from the object
specs = productJson['specifications']['categories'][0]['specifications'] - Iterates through the specifications and cleans them.
specifications ={} for spec in specs: specifications[spec['displayName']]=spec['value']
If the script tag doesn’t exist, the function:
- Finds all the script tags
scripts = page.find_all('script') - Iterates through the scripts tag and checks if the keyword exist
for script in scripts: if "initializer" in script.text: if "shop-specifications" in script.text: specScript = script.text</.pre>Note: The function also checks if the string “initializer” as there are other script tags with the keyword “shop-specifications” on Bestbuy.com.
- Searches for the JSON string from the script text and creates a JSON object.
specJson = json.loads(re.search(r'{\\".+}',specScript).group(0).replace('\\',"")) - Extracts and cleans the product specifications
specJson = json.loads(re.search(r'{\\".+}',specScript).group(0).replace('\\',"")) specs = specJson['specifications'] specifications = {} for spec in specs['categories']: for s in spec['specifications']: specifications[s['displayName'].replace('u002F','/')] = s['value']
Finally, productSpecifications() returns the extracted specifications.
productDetailsAndRatings()
This function extracts ratings and product details. These details are inside a script tag associated with the keyword “user-generated-content-ratings-and-reviews.”
Similar to productSpecifications(), this keyword could be in the ID of a script tag or inside the tag’s text.
Here also, the function first searches for a script tag where the ID has the keyword. If there is no script tag with that ID, it finds all the script tags and searches for the keyword inside the tag’s text.
However, unlike productSpecifications(), this function extracts three datasets:
- Product Details: details of products such as name, price, model, etc.
- Stats: Product statistics, including overall rating, the number of ratings, etc.
- Secondary Ratings: ratings of separate qualities of the product.
rnrId = re.compile(r"user-generated-content-ratings-and-reviews.+")
rnrScript = page.find('script',{'id':rnrId})
secondaryRatings = {}
if rnrScript:
rnrJson = json.loads(rnrScript.text)
productDetails = rnrJson['app']['productDetails']
stats = rnrJson['app']['stats']
sr = rnrJson['app']['aggregateSecondaryRatings']
for r in sr:
secondaryRatings[r['attributeLabel']] = round(r['avg'],2)
else:
scripts = page.find_all('script')
for script in scripts:
if "initializer" in script.text:
if "user-generated-content-ratings" in script.text:
ratingScript = script.text
ratingJson = json.loads(re.search(r'{\\".+}',ratingScript).group(0).replace('\\\\"',"'").replace('\\',""))
productDetails = ratingJson['app']['productDetails']
stats = ratingJson['app']['stats']
return [productDetails,stats,secondaryRatings]
fromProductPage()
The function fromProductPage() accepts the list of URLs extracted from getUrls(). It iterates through the list and extracts product details from each URL.
Start by calling parsePage() with a URL as the argument; this returns a BeautifulSoup object, which will have all the required details.
page = parsePage(url)
Extract the product specifications by calling the productSpecifications() function.
productDetails,stats,secondaryRatings = productDetailsAndRatings(page)
You can now extract the required ratings from the extracted statistics.
ratings = {
"Overall Rating":stats['averageOverallRating'],
"No. of Ratings":stats['totalReviewCount'],
"Recommended Percent":stats['recommendedPercent'],
"Rating Distribution":{
"5-Star": stats['ratingDistribution'][4]['count'],
"4-Star": stats['ratingDistribution'][3]['count'],
"3-Star": stats['ratingDistribution'][2]['count'],
"2-Star": stats['ratingDistribution'][1]['count'],
"1-Star": stats['ratingDistribution'][0]['count']
}
}
Extract the required product details. Here, the code extracts the name, model, price, brand name, and description.
name = productDetails['name']
model = productDetails['model']
price = productDetails['price']
brandname = productDetails['brandName']
description = productDetails['description'] if 'description' in productDetails else None
Note: A description may not be available for every product. That is why the code checks if the JSON data contains the key ‘description.’
Append all the extracted details to an array defined outside the loop.
bestBuyProducts.append(
{
"Name":name,
"Model":model,
"Price":price,
"Brand Name":brandname,
"Descriptions":description,
"specifications":specifications,
"Primary Ratings":ratings,
"Secondary Ratings": secondaryRatings,
}
)Finally, return the array.
return bestBuyProducts
You have declared all the functions; now you can integrate them. Here is a flowchart showing the execution order of the defined functions.
Start with getting the product name and the number of pages to scrape from the user.
product = input("What do you want to buy?")
pages = input("How many pages do you want to scrape")
Declare an empty dict.
pageData = {}
In a loop that runs a number of times equal to the number of pages to scrape:
- Build the URL using the current page and the product name
url = f"https://www.bestbuy.com/site/searchpage.jsp?st={product}&_dyncharset=UTF-8&_dynSessConf=&id=pcat17071&type=page&sc=Global&cp={cp}&nrp=&sp=&qp=&list=n&af=true&iht=y&usc=All+Categories&ks=960&keys=keys&intl=nosplash" - In a try-except block, call parsePage() with the URL as the argument. The try-except block handles the error if the search results page is not available.
try: soup = parsePage(url) except: print(f"only {cp} pages") break - Call the getUrls() to extract the product URLs from the search results page.
urls = getUrls(soup) - Call fromProductPage() with the list of product URLs as argument.
allProductDetails = fromProductPage(urls) - Save the extracted data to the dict declared earlier.
pageData[f"page {cp}"] = allProductDetails
After the loop completes, write the dict to a JSON file using json.dump()
with open("bestBuy.json","w") as f:
json.dump(pageData,f,indent=4,ensure_ascii=False)
Here is the complete code.
And here is the sample product data scraped from Bestbuy.com.
{
"Name": "Solo New York - Re:Define Recycled Backpack - Black",
"Model": "UBN708-4",
"Price": 55.99,
"Brand Name": "Solo New York",
"Descriptions": "Solo Define Recycled Backpack Collection. GREAT STYLE WHILE SAVING THE PLANET. We are tackling environmental issues from all angles, in-style. Designed in urban-cool gray, our Recycled Collection brings a sustainable angle to sleek design, making green choices accessible to the masses. Each item in this collection is built with city-functionality in mind and offers an uncompromising style. The Define Recycled Backpack has a fully padded 15.6” compartment with lockable zippers. The RFID data protection pocket helps secure personal data encoded on your credit cards, IDs and passports.",
"specifications": {
"Product Height": "18 inches",
"Product Width": "13 inches",
"Product Depth": "7 inches",
"Product Weight": "1.43 pounds",
"Maximum Laptop/Tablet Size": "15.6 inches",
"Rolling": "No",
"USB Charging Port": "true",
"Product Name": "Re:Define Recycled Backpack",
"Brand": "Solo New York",
"Model Number": "UBN708-4",
"Color": "Black",
"Color Category": "Black",
"Laptop/Tablet Compartment": "true",
"Adjustable Strap(s)": "true",
"Batteries Included": "false",
"Manufacturer's Warranty - Parts": "5 year Limited",
"Manufacturer's Warranty - Labor": "5 year Limited",
"UPC": "030918015742"
},
"Primary Ratings": {
"Overall Rating": 4.8,
"No. of Ratings": 122,
"Recommended Percent": 98,
"Rating Distribution": {
"5-Star": 104,
"4-Star": 15,
"3-Star": 1,
"2-Star": 0,
"1-Star": 2
}
},
"Secondary Ratings": {
"Value": 4.69,
"Quality": 4.77,
"Ease of Use": 4.82
},
"URL": "https://bestbuy.com/site/solo-new-york-redefine-recycled-backpack-black/6470442.p?skuId=6470442&intl=nosplash"
}
Code Limitations
The code shown in this tutorial can scrape product details from Best Buy. However, it does have some limitations:
- Does not scrape reviews: The product reviews exist on a different page; this scraper does not scrape them.
- Not appropriate for large-scale web scraping: Large-scale web scraping requires advanced techniques like proxy rotation to bypass anti-scraping measures. This code doesn’t use those techniques.
- May require code updates: Best Buy may change its HTML structure anytime, requiring you to update the code to reflect the changes.
Why Use a Web Scraping Service?
Web scraping Best Buy with Python is possible using BeautifulSoup, Python requests, re, and json. Python requests library manages HTTP requests, while json, BeautifulSoup, and re, handle extracting information.
However, you may need to add additional code if you want to scrape product reviews or use the code for large-scale web scraping. Moreover, the code needs to be updated whenever Bestbuy.com changes its HTML structure.
But you don’t need to build your own Best Buy web scraper using Python. ScrapeHero can do that for you; in fact, we can build web scrapers for any e-commerce website, including Walmart, Amazon, and eBay.
ScrapeHero is a fully managed enterprise-grade web scraping service. We can build high-quality web scrapers and crawlers to fulfill your data needs. Contact us today!
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



