
Web scraping e-commerce websites yields a large quantity of product data. Data about your products can help you understand how they perform, and your competitors’ product data will give you insights to outsmart them.
Wondering how to start web scraping? Read on. This article explains how to scrape data from e-commerce websites.
Methods to Programmatically Access Websites
Fundamentally, web scraping e-commerce websites requires at least two components
- One accesses a website using a script.
- The other parses the website’s code.
There are two ways to access websites with a script. One method is to send HTTP requests to the website. An HTTP request is what a browser sends to a website; here, the script will directly send the request.
For example, if you are building an Amazon scraper, the code that accesses the Amazon search results page would look like.
r = requests.get(“https://www.amazon.com/s?k=phones&crid=2FUNUSTPCBI8W&sprefix=phone%2Caps%2C517&ref=nb_sb_noss_1”)However, those requests won’t render the JavaScript commonly found on dynamic e-commerce websites. That is when you require the second method, an automated browser. It is possible to program such browsers to visit a web page, render JavaScripts, and extract data.
Libraries and modules for e-commerce web scraping
Any programming language can perform web scraping, but this article explains web scraping e-commerce websites using Python. Read on to learn about the Python libraries and modules that make web scraping possible.
Python has a built-in URL handler, urllib, to manage HTTP requests; the external Python library, requests, is also popular.
For automated browsers, use the libraries Playwright or Selenium to visit a website.
Some of the popular libraries for parsing HTML are html.parser, lxml, and BeautifulSoup.
BeautifulSoup is not a parser, but it can provide intuitive methods for data extraction; it can use any installed parser, including lxml.
Popular formats for storing the extracted data are CSV and JSON. There are built-in modules, csv and json, in Python that can manage these formats. The Python library, Pandas, can also write CSV files; it also provides methods to manipulate the data before writing.
While urllib, json, and csv come with Python, the others are external; install them using this code.
pip install selenium lxml beautifulsoup4 requests pytest-playwright pandasPlaywright needs additional code to install its browser.
python -m playwright installSeveral other Python libraries exist for web scraping. However, the ones discussed above are the popular ones.
Locating the Data Extracted from E-commerce Sites
Suppose you want to scrape the e-commerce site Etsy. The first step is to determine how to locate the data from Etsy’s search results page. To do that, analyze the website’s HTML code.
The browser’s developer options make the analysis quite straightforward.
Right-click on the data required and select inspect. A panel with the website’s HTML code containing a highlighted element will appear. This highlighted element will have the data.
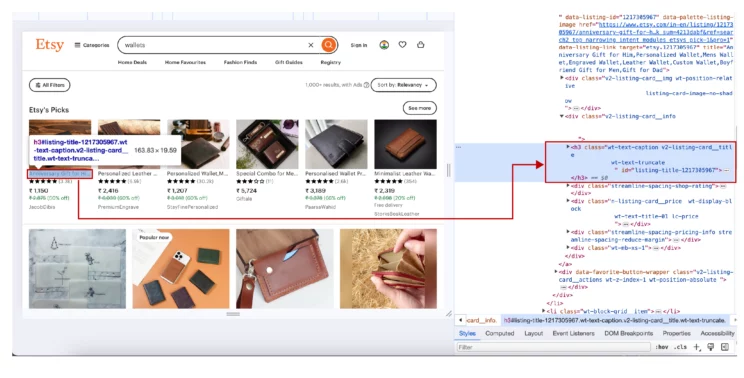
A unique identifier for this element usually includes the tag name, the attribute, and the parent. Then, build an XPath expression, discussed below, using this information to specify the element’s location.
The code
Begin by writing the import statements for the required packages. For example, write ‘import requests’ to use Python requests in the code.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from lxml import html
from playwright.sync_api import Playwright, sync_playwrightThe code snippet above shows import statements for various libraries and modules. Some statements only import a module from a library.
After writing the import statements, start defining custom functions. Writing the code without custom functions is also possible, but it will be less readable.
Typically, you need four functions, each for:
- sending requests
- parsing the response
- cleaning the data
- writing it to a file
Sending HTTP requests or Visit an E-commerce Site
The function will send HTTP requests or launch and send the automated browser to the target website. To send HTTP requests, use the get() method of requests. It accepts the URL as the argument.
The method for using an automated browser varies.
For Selenium, launch the browser using its WebDriver module. Then, go to the target website using the get() method.
Consider this code for a Walmart scraper that uses Selenium to visit Walmart’s search results page.
url = "https://www.walmart.com/search?q=phones”
driver = webdriver.Chrome()
driver.get(url)Playwright needs more steps to visit a website.
- Launch the browser using sync_playwright().start().chromium.launch()
- Start a new context using new_context()
- Open a new page using new_page()
- Visit the target website with goto()
browser = sync_playwright().start().chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.walmart.com/search?q=phones", wait_until="domcontentloaded")Parse and Extract the Required Data
As mentioned above, figure out where the data resides on the web page. Also, determine how to locate them. For example, consider this code from an Amazon page.
"//span[@class='a-size-medium a-color-base a-text-normal']"Only lxml can use the XPath.
parser = lxml.html.fromstring(response.text)
parser.xpath("//span[@class='a-size-medium a-color-base a-text-normal']/text()")The above code selects all the elements matching the criteria.
When using BeautifulSoup, specify the HTML tag name and attributes.
soup.find("span",attrs={"class":"a-size-medium a-color-base a-text-normal"}).textThe above code only matches the first element that BeautifulSoup finds. To find all the elements, use the find_all() method.
In Selenium, use the find_element() or find_elements() method to extract data points. Pass By.XPATH in the argument to specify the method to locate as XPath. However, this requires you to import By from selenium.webdriver.common.by.
Note: Besides by XPath, there are other ways to locate elements, including by class and by ID.
driver.find_element(By.XPATH,"//span[@class='a-size-medium a-color-base a-text-normal']").textThe above snippet finds the first element matching the XPath; use the find_elements() method to select all the matching elements.
Playwright has the method locator(), which accepts XPaths as the argument.
page.locator("//span[@class='a-size-medium a-color-base a-text-normal']").first.inner_text()The above method selects the text of the first product. For selecting the text of all the elements, use all_inner_texts() without the first attribute.
Clean the Extracted Data
The next part is cleaning, which deletes any extra spaces in the data. Use join() and split() methods for cleaning.
split() will split the string wherever it finds the specified separator. The default separator is a space, so the function will split the string wherever it encounters a space to create an array.
Then, use join to make a string from the items in the array. The method join() also accepts an argument it uses to join the elements. Therefore, using a single space as the argument will return a string with no extra spaces between the words.
data = " ".join(data.split()).strip()The above code snippet also uses strip(), which removes the spaces from the beginning and the end.
Store the Extracted Data
Finally, save the data as JSON or CSV.
To write as a JSON file, use the json.dump() method.
with open(“filename”, 'w') as file:
json.dump(data, file, indent=4)For writing as a CSV file with Pandas:
- Convert the scraped data into a Pandas data frame using the DataFrame() method.
- Use the to_csv() method on the data frame.
df = pandas.DataFrame(data)
df.to_csv()Or, use the csv module.
with open('%s-ebay-scraped-data.csv'%(brand),'wb') as csvfile:
fieldnames = ["title","price","url"]
writer = csv.DictWriter(csvfile,fieldnames = fieldnames,quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
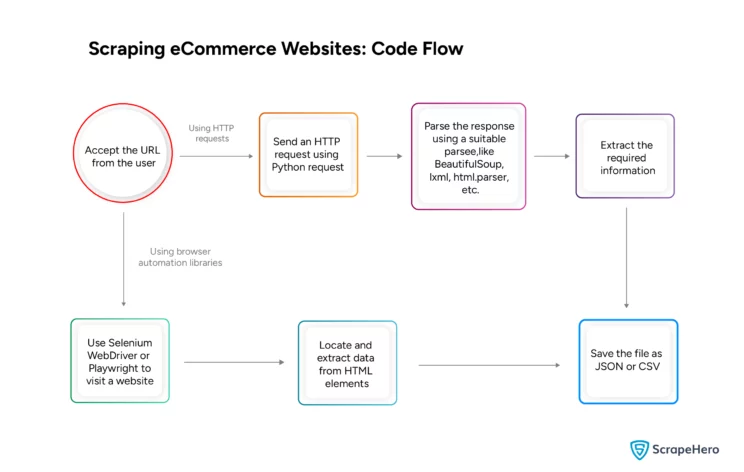
writer.writerow(data)Here is a flow chart illustrating the entire process.
Additional Points on Web Scraping E-commerce Websites
You read about web scraping e-commerce websites using Python, but the tutorial didn’t discuss anti-scraping measures. Most e-commerce websites use these measures to detect and restrict web scraping. Therefore, ways to avoid detection are necessary.
One method is to use headers to pose as a legitimate user. Use headers in HTTP requests and browser-based methods.
For example, you can pass the headers as an argument in Python requests.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
response = requests.get(url, headers=headers)However, headers may not be enough to avoid detection. Additional anti-scraping measures like proxy rotation may be necessary to extract data on a large scale.
The code locates HTML elements based on the website’s structure. Therefore, update the code whenever the target website changes its structure.
Wrapping Up
It is possible to scrape e-commerce websites using Python. There are both built-in and external packages for that. However, watch for changes in the website’s HTML code and update the code.
Moreover, it is necessary to modify this code for large-scale data extraction. Extracting data on a large scale exposes your scraper, making you more vulnerable to getting blocked. For such situations, use advanced anti-scraping measures like proxy rotation to avoid getting blacklisted while web scraping.
Of course, you can always choose ScrapeHero.
Our e-commerce web scrapers on the ScrapeHero Cloud provides a no-code approach. With only a few clicks, you can get product data from e-commerce websites in your preferred format.
We can also create custom web scrapers for you. ScrapeHero is a full-service web scraping service provider. We build enterprise-grade web scrapers according to your specifications; there is no need to learn web scraping or code yourself. ScrapeHero services range from large-scale web scraping and crawling to custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



