

Medium is a popular website that hosts a wide range of articles. Web scraping Medium articles can reveal trends, including the length of the most popular articles. This information can help you with content creation.
Here, you will learn how to scrape Medium articles using Python.
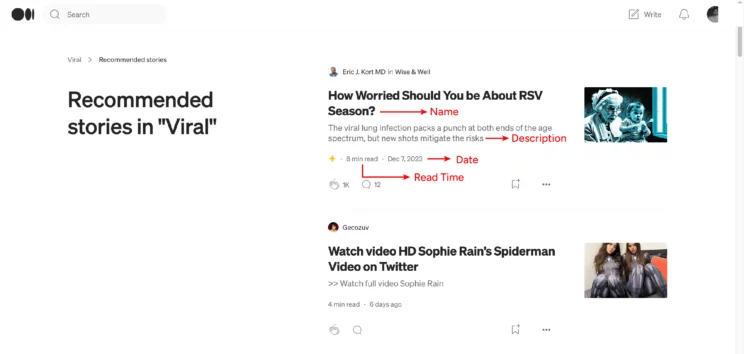
Data Scraped from Medium
This tutorial will show you web scraping Medium articles that are viral and recommended by Medium.
The details include name, description, date published, and read time. You may use these details to find the average read time of the homepage articles.
Web Scraping Medium: The Environment
Here, the code uses Python Playwright and BeautifulSoup to get the details. Specifically, you use Python Playwright to access the homepage contents.
As Medium.com’s homepage is dynamic, you need automated browsers to render JavaScript; libraries like Python requests won’t work. That is why you use Python Playwright here.
This code for web scraping Medium using Python accesses the homepage content using Playwright and passes it to BeautifulSoup for parsing.
Both libraries are external, and you must install them using pip.
Web Scraping Medium: The code
In addition to Python Playwright and BeautifulSoup, you need the json module to write the extracted data to a JSON file and the asyncio module to run an asynchronous function. The program also uses the sleep module to pause the script execution, giving time for the contents to load.
Therefore, the code begins with five import statements.
from playwright.async_api import async_playwright, Playwright
from bs4 import BeautifulSoup
import asyncio
import json
from time import sleepUse functions to structure your code; this improves readability and facilitates faster debugging. The number of functions required depends on the code’s primary tasks.
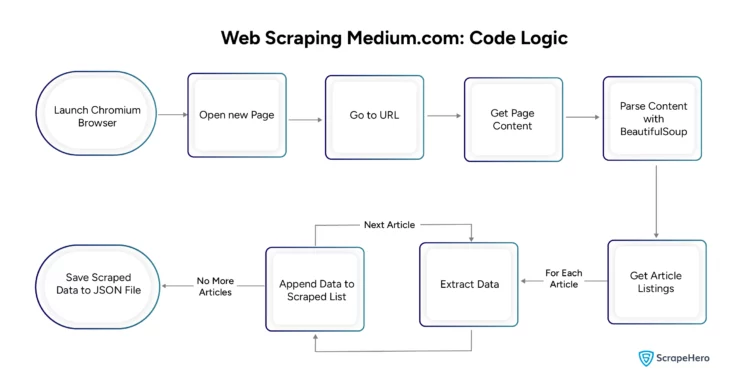
The code performs three main tasks: getting the page source, parsing and extracting details, and writing the data to a file. Create a function for each task. As the code uses Playwright asynchronously, the functions are also asynchronous.
The getSource() function launches a headless Playwright browser that visits Medium.com.
async def getSource(url):
async with async_playwright() as p:
browser = await p.chromium.launch()
page = await browser.new_page()
await page.goto(url)The above code defines the asynchronous function getSource(). It first launches the Chromium browser using chromium.launch() method.
Then, the function starts a new page using the new_page() method. Finally, getSource() uses the goto() method to visit the URL.
The next step is to get the source code.
However, before getting the source, the function uses a loop and scrolls two times to load more articles. Before each scroll, the function rests for 3 seconds to allow new articles to load.
for _ in range(2):
await page.mouse.wheel(0,1000)
sleep(3)Here, the code Playwright’s mouse.wheel() method in a loop to scroll repeatedly.
After the loop finishes, the function uses Playwright’s content() method to get the source code.
html_content = await page.content()
return html_contentThe second function is extract(); it calls getSource() asynchronously and gets the source code returned by it. Then, it parses the source code using BeautifulSoup for data extraction.
html_content = await getSource("https://medium.com/tag/viral/recommended")
soup = BeautifulSoup(html_content,'lxml')First, extract() finds the elements holding the article listing. These listings are inside an article tag.
articles = soup.find_all('article')Next, it gets the details: Name from h2, description from h3, read time, and date published from the span tag.
span = article.span.text
h2 = article.h2.text
description = article.h3.text
text = span.split('·')
readTime = text[1].split()[0]
publishedOn = text[2]
link = article.find('div',attrs={'role':'link'})['data-href']Finally, extract() adds these details to a dict object and appends the dict object to an array.
data = {
"Topic":h2,
"Description":description,
"Read Time":readTime,
"Published On": publishedOn,
"URL":link
}
scraped_data.append(data)The main() function calls extract() and gets the scraped data, which it writes to a JSON file using the JSON module.
async def main():
scraped_data = await extract()
print(f"{len(scraped_data)} articles scraped")
with open("medium.json",'w',encoding='utf-8') as jsonFile:
json.dump(scraped_data,jsonFile,indent=4, ensure_ascii=False)Here is a flow chart showing the entire process of scraping data from Medium.
Here is the complete code to scrape Medium articles.
from playwright.async_api import async_playwright, Playwright
from bs4 import BeautifulSoup
import asyncio
import json
from time import sleep
async def getSource(url):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto(url)
for _ in range(2):
await page.mouse.wheel(0,1000)
sleep(3)
html_content = await page.content()
return html_content
async def extract():
html_content = await getSource("https://medium.com/tag/viral/recommended")
soup = BeautifulSoup(html_content,'lxml')
articles = soup.find_all('article')
scraped_data = []
for article in articles:
try:
span = article.span.text
h2 = article.h2.text
description = article.h3.text
text = span.split('·')
readTime = text[1].split()[0]
publishedOn = text[2]
link = article.find('div',attrs={'role':'link'})['data-href']
data = {
"Topic":h2,
"Description":description,
"Read Time":readTime,
"Published On": publishedOn,
"URL":link
}
scraped_data.append(data)
except:
continue
return scraped_data
async def main():
scraped_data = await extract()
print(f"{len(scraped_data)} articles scraped")
with open("mediumArticles.json",'w',encoding='utf-8') as jsonFile:
json.dump(scraped_data,jsonFile,indent=4, ensure_ascii=False)
asyncio.run(main())And here is the scraped data.
[
{
"Topic": "How Worried Should You be About RSV Season?",
"Description": "The viral lung infection packs a punch at both ends of the age spectrum, but new shots mitigate the risks",
"Read Time": "8",
"Published On": "Dec 7, 2023",
"URL": "https://medium.com/wise-well/how-worried-should-you-be-about-rsv-season-dc3be4fdc2b3"
},
{
"Topic": "I’m Strangely Angry at My Viral Article",
"Description": "It’s a case of: “Be careful what you wish for”",
"Read Time": "4",
"Published On": "1 day ago",
"URL": "https://medium.com/new-writers-welcome/im-strangely-angry-at-my-viral-article-9252952baa38"
},
{
"Topic": "This Headhunter Has Nailed LinkedIn Virality Twice in 7 Days",
"Description": "9 lessons from 2 mega-viral posts that you can apply",
"Read Time": "6",
"Published On": "Nov 10, 2022",
"URL": "https://medium.com/better-marketing/this-headhunter-has-nailed-linkedin-virality-twice-in-7-days-d98ba1d4937d"
},
{
"Topic": "Twitter alternative: how Mastodon is designed to be “antiviral”",
"Description": "The new social software is subtly designed to reduce the huge, viral surges of attention we see on Twitter",
"Read Time": "9",
"Published On": "Nov 13, 2022",
"URL": "https://medium.com/user-experience-design-1/mastodon-is-antiviral-design-42f090ab8d51"
},
{
"Topic": "Don’t Become a Content Machine",
"Description": "Why your c̶o̶n̶t̶e̶n̶t̶ work should do more than try and go viral",
"Read Time": "6",
"Published On": "Oct 24, 2022",
"URL": "https://medium.com/@herbertlui/dont-become-a-content-machine-b3b965cfbf9e"
}
]
Code limitations
You can use this code to scrape articles listed on the medium homepage, but the article listings must be inside an article tag. You may have to change your code if Medium restructures the HTML and uses another tag.
Moreover, Medium can change the URL for recommended articles. You then have to find the correct URL and update the code.
Wrapping Up
You can scrape Medium using Python Playwright and BeautifulSoup. However, the code relies on the website structure, which may change; the code will fail if that happens. Therefore, watch Medium.com for any changes and reflect those changes in your code.
If you don’t want to do all that, try ScrapeHero Services.
ScrapeHero is a full-service web scraping service provider. We can create enterprise-grade web scrapers according to your specifications. Our services also include brand and product monitoring and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


