

MercadoLibre is an Argentine e-commerce company that serves several Latin American countries. Web Scraping MercadoLibre will tell you how your products perform on the website and give you insight into your competitors.
In this tutorial, you can learn how to scrape MercadoLibre product data using Python.
The Setup for Web Scraping MercadoLibre Using Python
Ensure you have the required Python packages before executing the code shown in this tutorial. This tutorial uses three external packages; install these Python packages using pip.
pip install requests bs4 unicodecsvHere,
- The requests library helps you manage HTTP requests.
- bs4 stands for BeautifulSoup4 library, which lets you parse and extract data from the HTTP response.
- Unicodecsv enables you to write the extracted data to a CSV file.
BeautifulSoup can use any parser. However, this tutorial uses the external Python package lxml, which is also installable using pip.
pip install lxmlThe code also uses argparse, which enables the script to accept arguments from the command line. However, you don’t have to install it since it comes pre-installed with Python.
Data scraped from Mercado Libre
This code for web scraping MercadoLibre scrapes three data points using BeautifulSoup:
- Price
- Url
- Name
These are available on MercadoLlibre’s search results page itself. You only need to find the attributes of these data points.
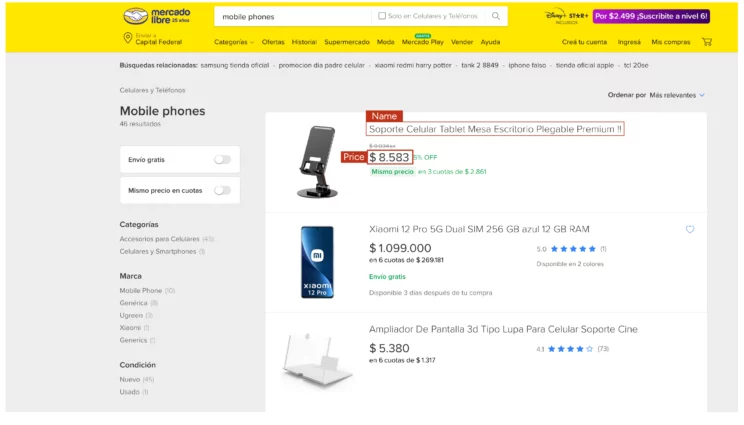
You can find the attributes using your browser’s inspect tool. Right-click on the name and select inspect, and an inspect panel will appear with the HTML tag containing the name. The panel also tells you what attributes the element has.
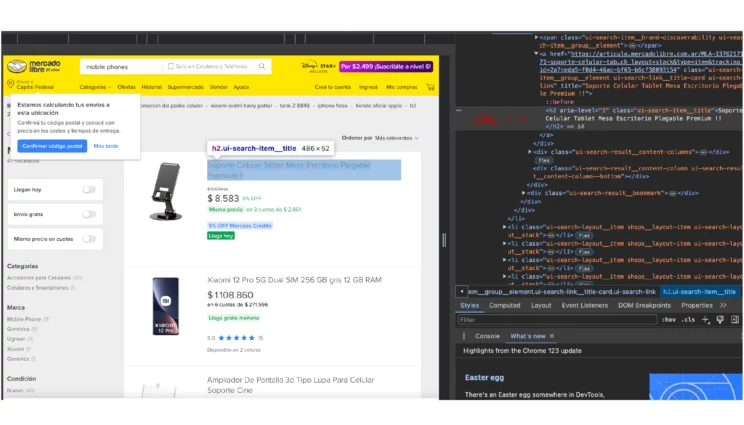
Check the code above or below. There will be an anchor tag with an href attribute. That is the required URL from MercadoLibre.
How to Scrape MercadoLibre: The Code
This section tells you how to write the code for web scraping MercadoLibre using Python. MercadoLibre data extraction with Python has three parts:
- Import Packages
- Define Functions
- Integrate Everything
Import Packages
Import all the packages mentioned above.
import requests
from bs4 import BeautifulSoup
import unicodecsv as csv
Import argparseDefine Functions
Define a separate function parse() to extract the code; this makes this code for MercadoLibre data extraction more readable.
The function accepts a URL and sends an HTTP request. Right now, MercadoLibre does not block a request from a scraper. Therefore, there is no need to use fake user-agent headers.
response = requests.get(url)Next, parse the response using BeautifulSoup.
soup = BeautifulSoup(response.text,'lxml')The products are inside a div element with the class ‘ui-search-result__content-wrapper.’ Select them using find_all().
products=soup.find_all('div',{'class':'ui-search-result__content-wrapper'})Iterate through the div elements and find
- the anchor tag containing the URL
- h2 tag containing the name
- a span tag with the class ‘andes-money-amount__fraction’ tag containing the price
Then, store the extracted elements in a dict object, append it to an array, and return the array.
for product in products:
href = product.find('a')['href']
name = product.find('h2').text
price = product.find('span',{'class':'andes-money-amount__fraction'}).text
data.append({
"Name":name,
"Price":price,
"URL":href
})
return dataThe above function can parse data from a product URL, which includes the search term supplied at runtime. To build this URL, define a function linkMaker() that accepts the search term and returns the product URL.
def linkMaker(string):
words = string.split()
start = ""
end = "#D[A:"
for word in words:
start = start+word+"-"
end = end+word+"%20"
url = "https://listado.mercadolibre.com.ar/"+start[:-1]+end[:-3]+"]"
return urlIntegrate Everything
The argparse module is responsible for accepting the search term when you run the script from the command line. Use its add_argument() method to specify each argument.
Then, the parse_args() will parse the arguments the script gets during execution; store them in a variable. Here, the variable is the search term.
argparser = argparse.ArgumentParser()
argparser.add_argument('search',help = 'Search Term')
args = argparser.parse_args()
search_term = args.searchCall linkMaker() to build a URL and then call parse() with that.
url = linkMaker(search_term)
scraped_data = parse(url)Finally, write the data returned by parse() to a CSV file using the unicodecsv DictWriter() method.
if scraped_data:
print ("Writing scraped data to mercadolibre_%s_data.csv"%(search_term))
with open('mercadolibre_%s_data.csv'%(search_term),'wb') as csvfile:
fieldnames = ["Name","Price","URL"]
writer = csv.DictWriter(csvfile,fieldnames = fieldnames,quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)
else:
print("No data scraped")
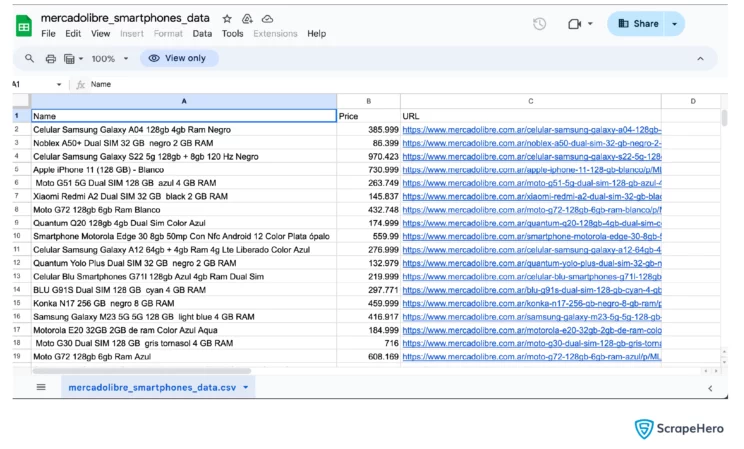
Here are the results of web scraping MercadoLibre.
And here is the complete code
import requests
import argparse
import unicodecsv as csv
from bs4 import BeautifulSoup
def parse(url):
response = requests.get(url)
soup = BeautifulSoup(response.text,'lxml')
products=soup.find_all('div',{'class':'ui-search-result__content-wrapper'})
data = []
for product in products:
href = product.find('a')['href']
name = product.find('h2').text
price = product.find('span',{'class':'andes-money-amount__fraction'}).text
data.append({
"Name":name,
"Price":price,
"URL":href
})
return data
def linkMaker(string):
words = string.split()
start = ""
end = "#D[A:"
for word in words:
start = start+word+"-"
end = end+word+"%20"
url = "https://listado.mercadolibre.com.ar/"+start[:-1]+end[:-3]+"]"
return url
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('search',help = 'Search Term')
args = argparser.parse_args()
search_term = args.search
url = linkMaker(search_term)
scraped_data = parse(url)
if scraped_data:
print ("Writing scraped data to mercadolibre_%s_data.csv"%(search_term))
with open('mercadolibre_%s_data.csv'%(search_term),'wb') as csvfile:
fieldnames = ["Name","Price","URL"]
writer = csv.DictWriter(csvfile,fieldnames = fieldnames,quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)
else:
print("No data scraped")Code Limitation
The above code will scrape MercadoLibre product data if they do not use anti-scraping measures. Otherwise, bypass them using techniques like user-agent headers and proxy rotation to scrape without getting blocked.
Moreover, you may have to reanalyze their HTML code whenever MercadoLibre changes its website structure. That is because changes in website structure can affect the attributes and tags of the data points, making it necessary to update the code to reflect the changes.
Wrapping Up
You can use Python requests and BeautifulSoup to scrape MercadoLibre.com. This code shows how to do that, but you may need to change it when the website structure changes. Moreover, large-scale data extraction may not be possible, as this code does not use any techniques to bypass anti-scraping measures.
Therefore, for a more robust code, contact ScrapeHero Services. We are a full-service web scraping service provider capable of enterprise-grade web scraping and crawling. We also have ready-made web scrapers on ScrapeHero Cloud, which you can try for free.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


