

When you search for a product on Target.com, it executes JavaScript and fetches the search results from an external URL. That means you can either use
- Headless browsers like Selenium to execute JavaScript and extract details from the HTML elements, or
- The external URL to fetch the results directly.
This article shows how to scrape Target.com using the second method: using an external URL to fetch results directly.
Data Scraped from Target
The code first makes an HTTP request to the external URL to get the products listed on the search results. You can get this URL using your browser’s inspect tool.
- Open the network tab of the inspect tool while on Target.com
- Select Fetch/XHR
- Search for a product
- Copy the URL from product_summary_with_fullfilment on the ‘Name’ column
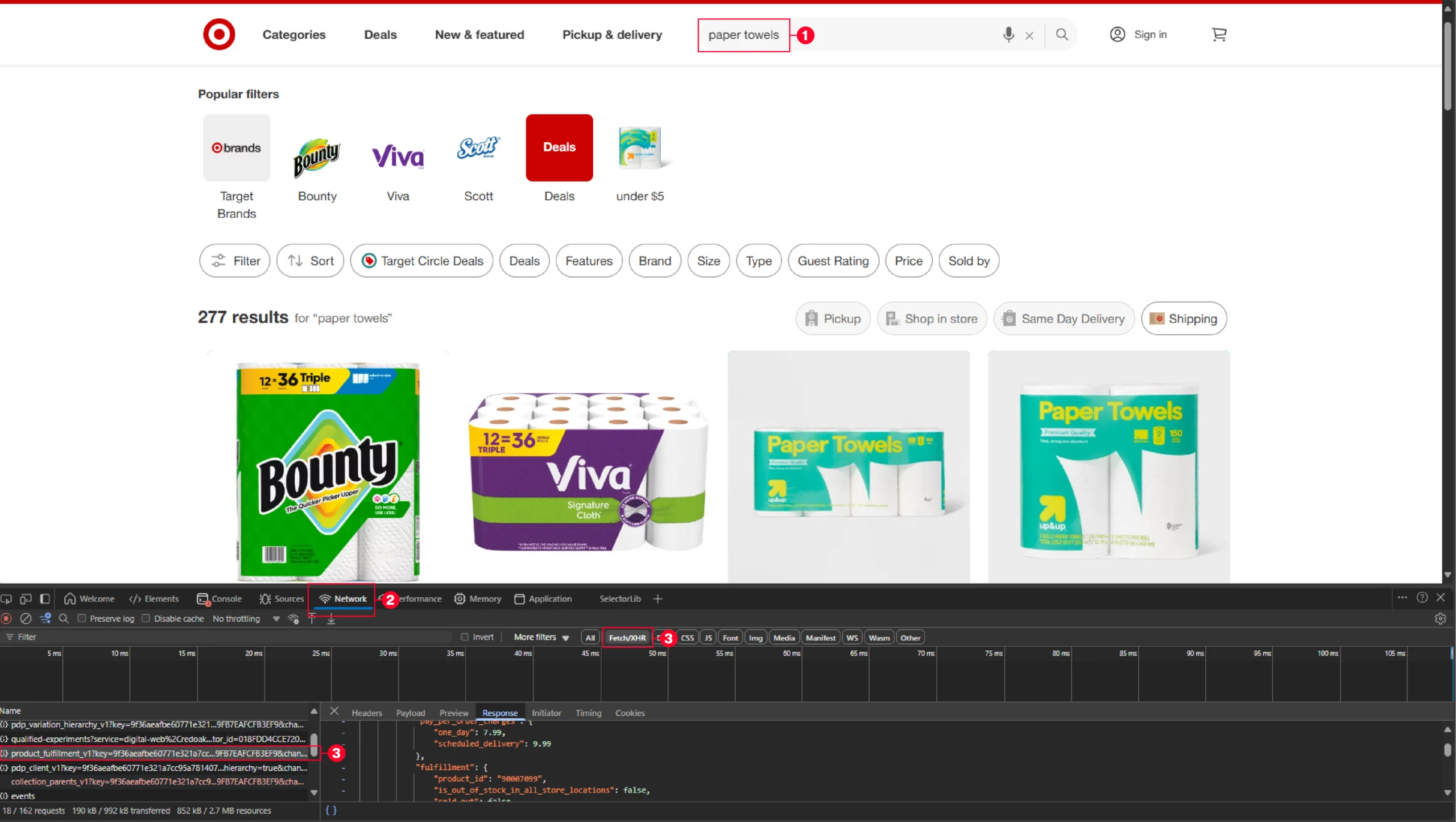
The details obtained from this URL only contain the product title and the URL.
Therefore, you need to fetch all the other product details from the product URLs. In total, the code extracts 6 data points:
- Description
- Features
- Name
- Price
- URL
- Ratings
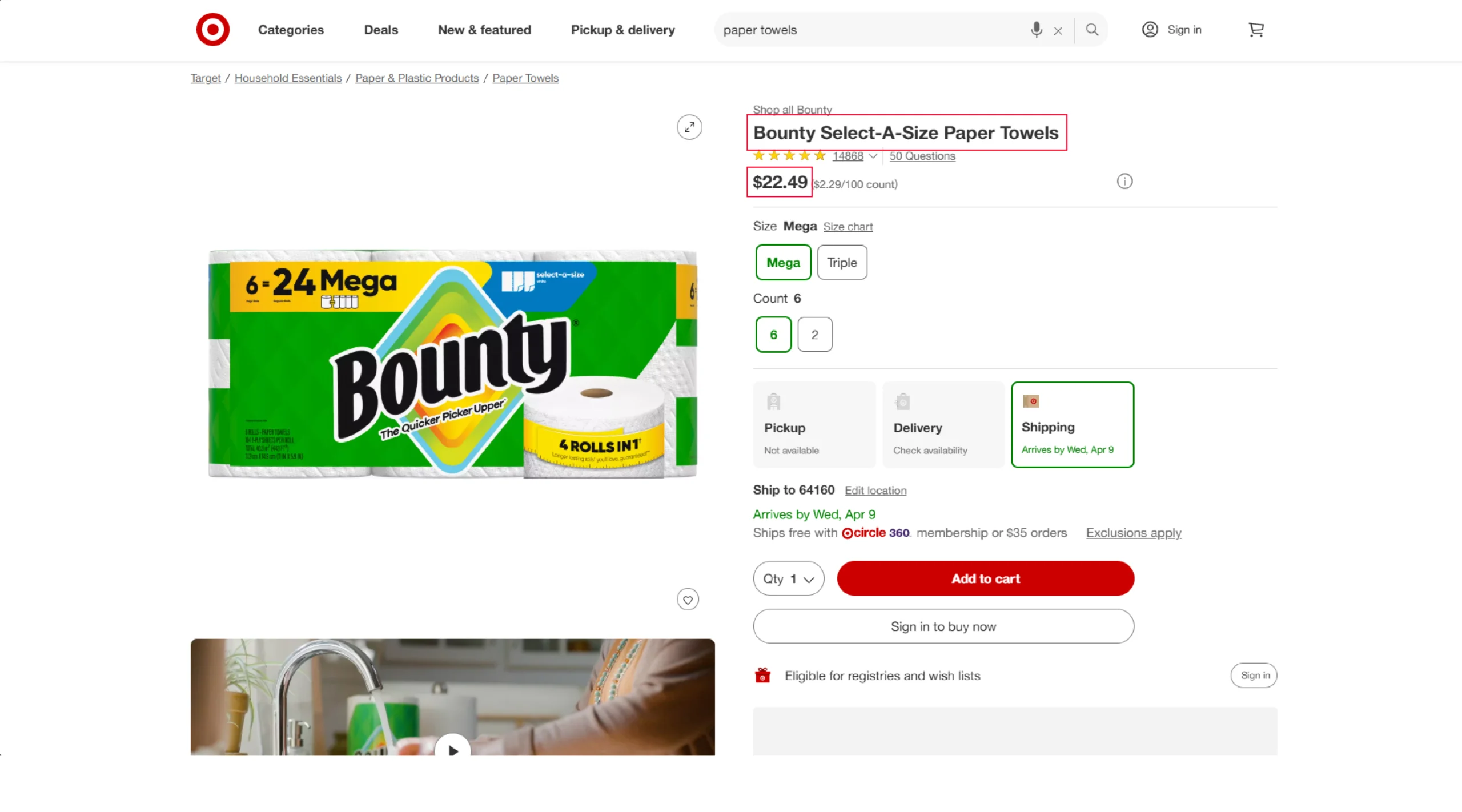
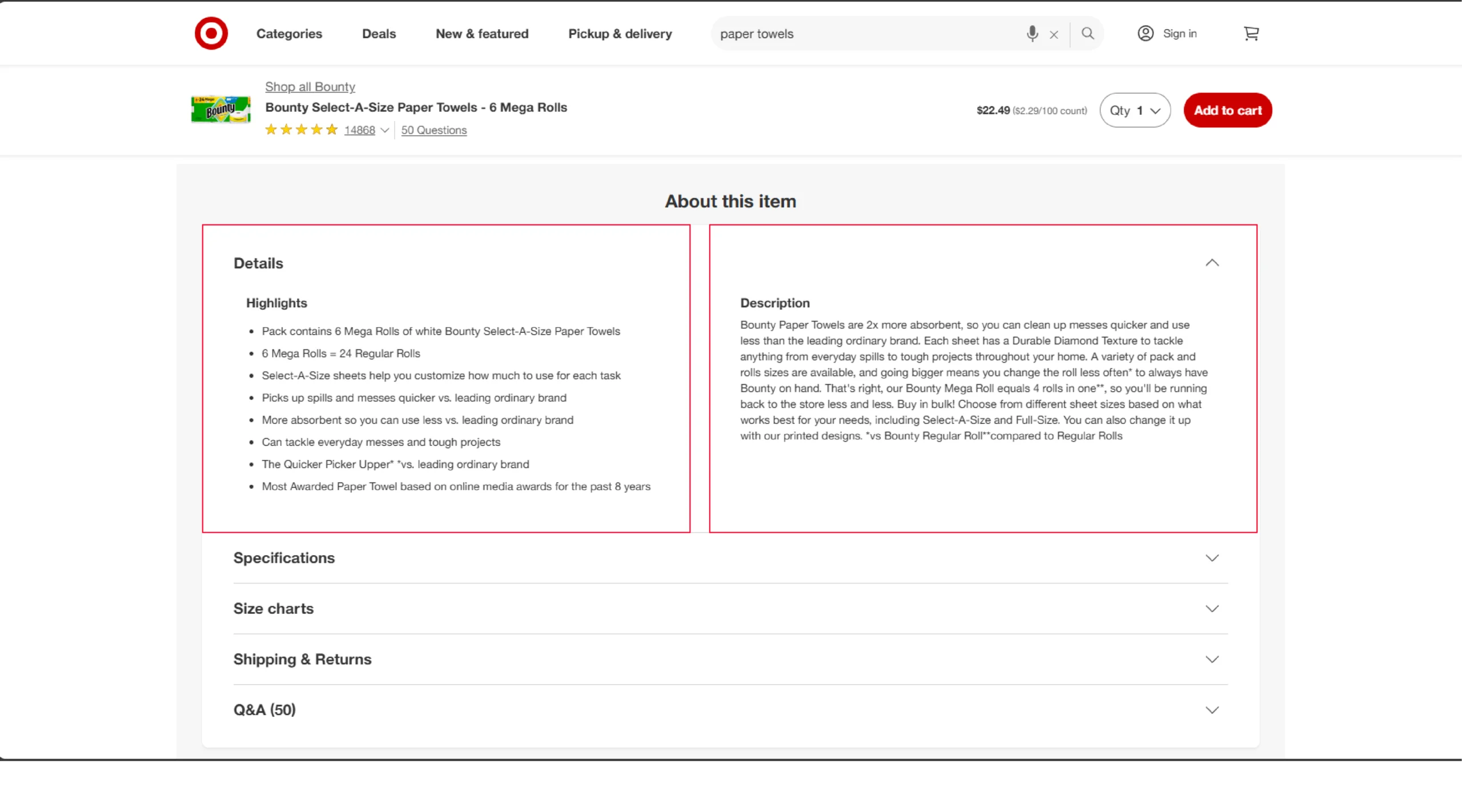
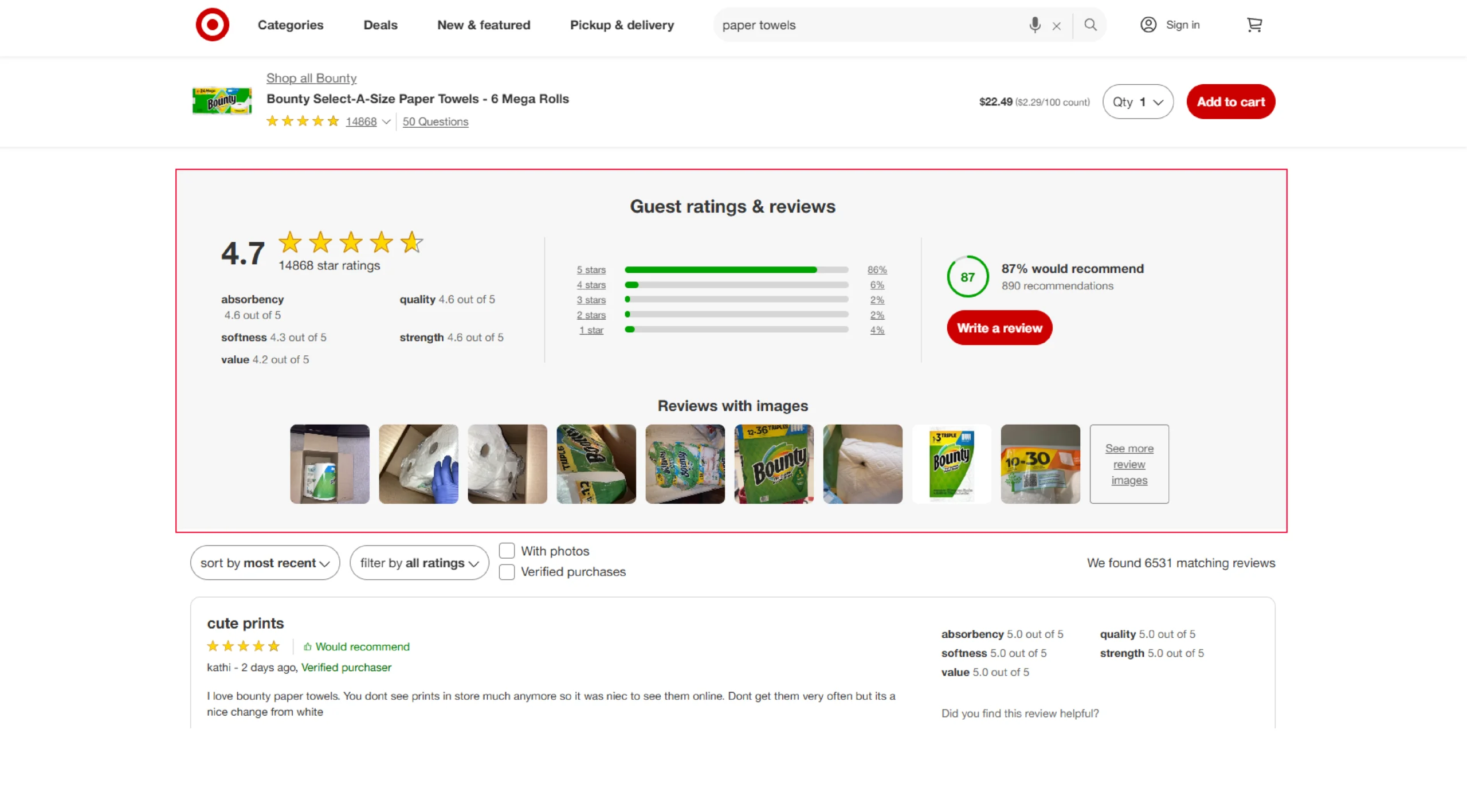
All these details will be inside a script tag; that means you don’t need to worry about XPaths.
Web Scraping Target with Python: Environment
The code needs four external packages for extracting data from Target:
- Python requests: Handles HTTP requests
- BeautifulSoup: Parses HTML code
- The json module: Handles JSON data
- The re module: Handles RegEx syntax
BeautifulSoup and Python requests are external Python libraries; therefore, install them using pip.
pip install bs4 requests
Web Scraping Target.com: The Code
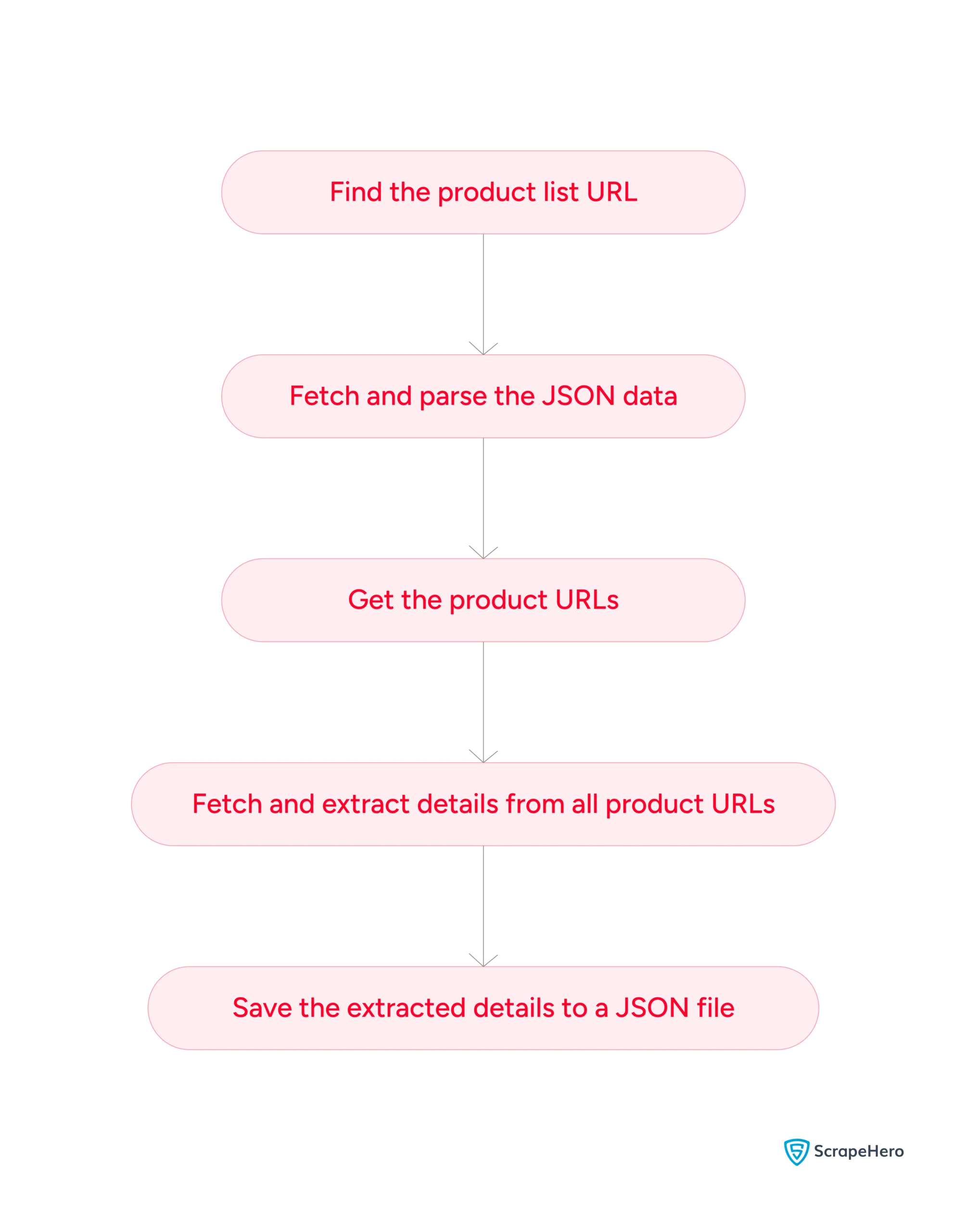
Start by importing all the required packages.
import requests
from bs4 import BeautifulSoup
import json
import reDefine headers to use while making HTTP requests to avoid being detected by Target.com. Here are the headers used for web scraping Target.com:
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}- The accept headers define what formats your response will contain.
- The accept-language header specifies what languages the response can contain.
- The DPR headers will specify the density pixel ratio.
- The sec-fetch headers increase security. It gives the server the context of the request.
- “sec-fetch-dest: document” tells the server that the request intends to get a document.
- “sec-fetch-mode: navigate” tells the server that requests originated in the browser’s mainframe.
- “sec-fetch-site: none” tells the server there is no relationship between the server and the request.
- “sec-fetch-site: ?1” tells the server that the request is user-generated.
- The user-agent headers fake the details of the device and the software from which the request originated.
Get the product URLs
Use the headers defined above to send requests to the URL from which target.com fetches the product data.
product_summary = requests.get(
"https://redsky.target.com/redsky_aggregations/v1/web/product_summary_with_fulfillment_v1?key=9f36aeafbe60771e321a7cc95a78140772ab3e96&tcins=87450164%2C89981814%2C76633629%2C76564372%2C75557222%2C83935767%2C90007101%2C87450172%2C84694230%2C83935763%2C75663217%2C51944685%2C81088223%2C81888650%2C86912997%2C91337758%2C91337835%2C91337712%2C91337754%2C91337804%2C91337741%2C91337794%2C91337728%2C91337843%2C91337807%2C91337698%2C91337703%2C91337759&zip=64160&state=TN&latitude=11.090&longitude=77.350&has_required_store_id=false&skip_price_promo=true&visitor_id=018FDD4CCE720201AA9FB7EAFCFB3EF9&channel=WEB&page=%2Fs%2Fpaper+towels",
headers=headers,
).textNext, use the json.loads() to parse the request text, which will be in JSON format.
product_summary = json.loads(product_summary)Extract the value containing the details of all the products; they will be inside the key “product-summaries.”
products = product_summary["data"]["product_summaries"]Define an array to store the URLs
- Iterate through all products.
- Extract the product URLs
- Store them in the array.
urls = []
for product in products:
urls.append(product["item"]["enrichment"]["buy_url"])Define another empty array to store the extracted product details.
targetProducts = []Extract the Product Details
Iterate through the array containing product URLs. Each loop will
- Make HTTP requests to the URL
- Extract details
- Store them in a dict
- Append the dict
Making HTTP requests
While making the HTTP requests, use the get method of Python requests with the headers defined earlier.
pResponse = requests.get(url, headers=headers)Extracting the details
Begin extracting details by parsing the contents using BeautifulSoup. Then, you can locate and extract the required details, which will be inside a script element.
soup = BeautifulSoup(pResponse.text)To locate the script element, you need to analyze the HTML code, which tells you that the product details are inside a script element with a variable __TGT_DATA__,
Therefore, to find the script element containing the product details,
1. Find all the script elements.
scripts = soup.find_all("script")2. Iterate through all the scripts, and if any script contains __TGT_DATA__, pass it into the reqScript variable.
for script in scripts:
if "__TGT_DATA__" in script.text:
reqScript = scriptStill inside the loop,
1. Extract the JSON string.
jsonProduct = re.search(r'parse\("({ .+)"\)\)', reqScript.text).group(1)2. Clean the string, depending on the JSON string’s structure. Here,
- Remove backslashes before the double quotes so they remain unescaped.
jsonProduct = jsonProduct.replace('\\"', '"')
jsonProduct = jsonProduct.replace('\\\\"', '\\"')- Put the true and false values in double quotes.
jsonProduct = jsonProduct.replace("false\n", '"false"\n')
jsonProduct = jsonProduct.replace("true\n", '"true"\n')Now, load the JSON string using the json module, giving you a JSON object.
jonProduct = json.loads(jsonProduct)You can extract the product details from this JSON object. Ensure you extract the required details in a try-except block, as there may be null values, leading to errors.
1. Get the dict containing product descriptions.
queries = jsonProduct["__PRELOADED_QUERIES__"]["queries"]
product = None
for i in range(len(queries)):
try:
product = jsonProduct["__PRELOADED_QUERIES__"]["queries"][i][1]['data']['product']
except:
continue
try:
rawDescription = product['children'][0]['item']['product_description']
except:
rawDescription = product['item']['product_description']The above code uses try except-except block because the product description may be at either of the locations in the JSON object.
2. Get the product description and features from this dict
description = rawDescription["downstream_description"]
features = rawDescription["soft_bullets"]["bullets"]3. Get the title
name = rawDescription["title"]4. Extract the dict containing various types of product prices, which also have a couple of possible locations.
try:
rawPrice = product["children"][0]["price"]
except:
rawPrice = product['price']5. Get the current price from this dict
price = rawPrice["current_retail"]6. Extract the ratings
ratings = product['ratings_and_reviews']['statistics']Storing the values to a dict and appending it to the array
# store the details in an dict
extractedProductDetails = {
"description": description,
"features": features,
"name": name,
"price": price,
"url": url,
}
# Append the details to an array
targetProducts.append(extractedProductDetails)Finally, you can save the extracted details to a JSON file.
with open("target.json", "w", encoding="UTF-8") as targetFile:
json.dump(targetProducts, targetFile, indent=4, ensure_ascii=False)Code Limitations
Although you can scrape Target using the code from the Tutorial, it has some limitations:
- Doesn’t scrape all available product details; you need to alter the code if you want to extract any other data points.
- Will fail if Target.com changes the HTML/JSON structure as the parsers rely on it..
- Doesn’t have techniques to bypass anti-scraping measures, making it unsuitable for large-scale web scraping.
ScrapeHero Target Scraper
For scraping data from Target without coding, try ScrapeHero Target Scraper for free from ScrapeHero Cloud. It is a no-code web scraper that can gather product details from Target.
Its benefits include:
- Scheduled executions
- Automated delivery to your cloud storage
- Data available in multiple formats
- API to integrate with your workflow
Here’s how you use the scraper:
- Go to the scraper’s homepage.
- Create a new project.
- Give your project a name.
- Enter search keywords or search listing URLs.
- Click Gather data.
You can find the gathered data from the “My Projects” tab.
Wrapping Up: Why Use a Web Scraping Service
Target data scraping is possible without using headless browsers. Use Python requests to get the HTML code and the packages BeautifulSoup, json, and re to extract the content.
However, the code shown in this tutorial only works until Target.com changes the HTML/JSON structure or URLs. If that happens, you need to update the code. You also need to change the code to bypass anti-scraping measures in large-scale projects.
If you want to avoid all this work, try ScrapeHero’s web scraping service. ScrapeHero can take care of everything, including handling anti-scraping measures and monitoring Target.com for changes.
ScrapeHero is an enterprise-grade web scraping service provider capable of building high-quality, custom scrapers for you. Contact ScrapeHero to know more!


