

Weather data is highly dynamic and updated in real-time. Websites like Weather.com use JavaScript to fetch and display data in real-time. Therefore, web scraping weather data using Python requires headless browsers like Selenium, which can render JavaScript.
Read on to learn how you can use Selenium Python to extract the dynamic weather data from Weather.com.
Data Scraped from Weather.com
The code does not scrape data from the HTML elements displayed on the web page. Instead, it extracts a JSON string from a script tag containing all the data displayed on the screen.
The code extracts three data sets:
- Two-day hourly forecast: Detailed forecasts for every hour of each day.
- Fifteen-day 24-hour forecast: General weather forecasts of each day.
- Fifteen-day day-parted forecast: General weather forecasts for day and night separately of each day.
Environment for Web Scraping Weather Data Using Python
The code needs three external packages that you need to install with pip:
Selenium Python is a browser automation library that lets you visit Weather.com and input the location in the search box.
pip install seleniumBeautifulSoup parses the HTML data extracted using Selenium. It then enables you to find the script tags.
pip install bs4Pandas enables you to save the extracted data as a CSV file.
pip install pandasYou also require other packages but don’t require installation because they come with the standard Python library:
- The json module allows you to parse and manipulate JSON objects.
- The re module enables you to extract the JSON string from the script tag.
- The time module allows you to pause the script.
Code for Web Scraping Weather Data Using Python
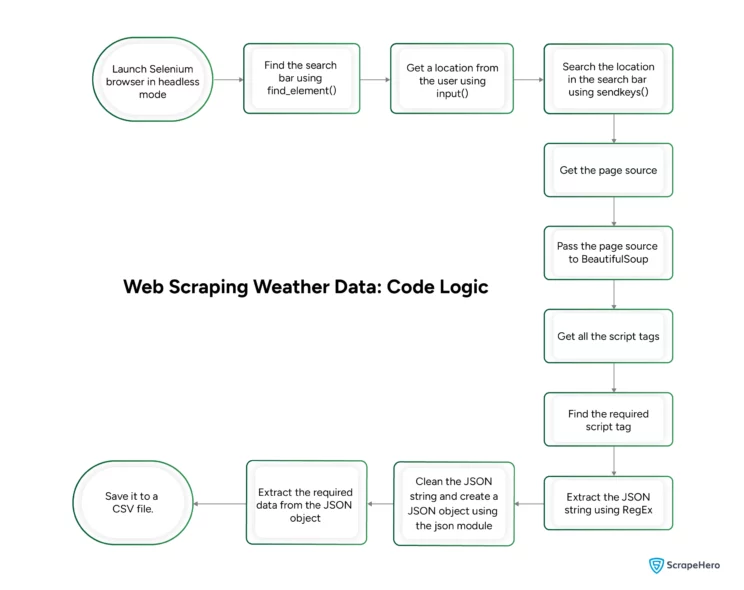
Start by importing the packages mentioned above; for Selenium, import its three modules separately.
- WebDriver controls the browser
- The By module specifies how to extract the contents ( by XPath, tag_name, etc.)
- The Keys module allows you to send keyboard inputs
import pandas, json, re
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleeThis tutorial performs web scraping using Selenium in headless mode. To do so, add arguments to the Selenium Chrome Options.
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")Now, you can launch Chrome using the options as an argument and visit weather.com.
browser = webdriver.Chrome(options=options)
browser.get("https://weather.com")Next, find the search bar that accepts the location. The search bar will be an input element; BeautifulSoup’s find method can locate it.
bar = browser.find_element(By.TAG_NAME,"input")This code can get weather data from any location supplied by the user. It uses input() to get a location from the user.
Then, Selenium’s send_keys() method can input the place into the search bar.
place = input("Enter a place")
bar.send_keys(place)Use sleep() to pause the script for three seconds for options to load, then press Enter using sendkeys(). Pausing is necessary, or the weather data may not be from the entered location.
sleep(3)
bar.send_keys(Keys.ENTER)The homepage does not have the required weather data; you need to extract it from one of the other pages. This code extracts data from the page that displays Today’s weather forecast.
Find and click on the ‘Today’ link in the navigation bar; this will load the necessary weather data.
forecasts = browser.find_element(By.XPATH,f"//nav/div/div/a/span[contains(text(),'Today')]")
forecasts.click()Now, get the page source and pass it to BeautifulSoup for parsing. BeautifulSoup will allow you to find HTML data.
source = browser.page_source
soup = BeautifulSoup(source,"lxml")The code gets the weather data from the script tag. But you need to know which script tag contains the data.
Therefore,
- Find all the script tags.
scripts = soup.find_all('script') - Iterate through them and extract the one containing the term “window.__data.”
reqScript = "" for script in scripts: if "window.__data" in script.text: reqScript = script.text
The next step is to find the JSON string from the script tag. You can use RegEx using Python’s re module to do so.
group = re.search(r'\("({.+})"\)',reqScript)Clean the extracted JSON string. Here, cleaning refers to removing all unnecessary backward slashes.
You can now make a JSON object from the string and extract the required information.
text = group[1].replace('\\"','"')
text = text.replace('\\"','"')Extracting Hourly Forecasts
A location-dependent inner key of the key ‘getSunV3HourlyForecastUrlConfig’ holds the hourly forecast. That means the code needs to find the key dynamically every time. You can do that using the keys() method.
jsonWeather = json.loads(text)
hourly = jsonWeather['dal']['getSunV3HourlyForecastUrlConfig']
innerKey = list(hourly.keys())[1]You can then use the inner key to find the required data.
hourly = hourly[innerKey]['data']Extracting Fifteen-Day Forecasts
The other two datasets will be inside the key ‘getSunV3DailyForecastingWithHeadersUrlConfig’. As previously done, find the location-dependent inner key and get the required data.
dailyForecast = jsonWeather['dal']['getSunV3DailyForecastWithHeadersUrlConfig']
innerKey = list(dailyForecast.keys())[1]
fifteenDay = dailyForecast[innerKey]['data']The data will contain both the fifteen-day forecasts: 24-hour and day-part. Separate them and remove the response headers from the data.
daypart = fifteenDay['daypart']
del fifteenDay['daypart']
response_headers = fifteenDay['responseHeaders']
del fifteenDay['responseHeaders']You now have three JSON objects with the required data sets. Pandas can convert these JSON objects to DataFrames, allowing you to save them as CSV files.
# create DataFrames
fifteenDayDataFrame = pandas.DataFrame(fifteenDay)
daypartDataFrame = pandas.DataFrame(daypart[0])
hourlyDataFrame = pandas.DataFrame(hourly)
# save to csv files
hourlyDataFrame.to_csv("hourly.csv")
fifteenDayDataFrame.to_csv("fifteenDay.csv")
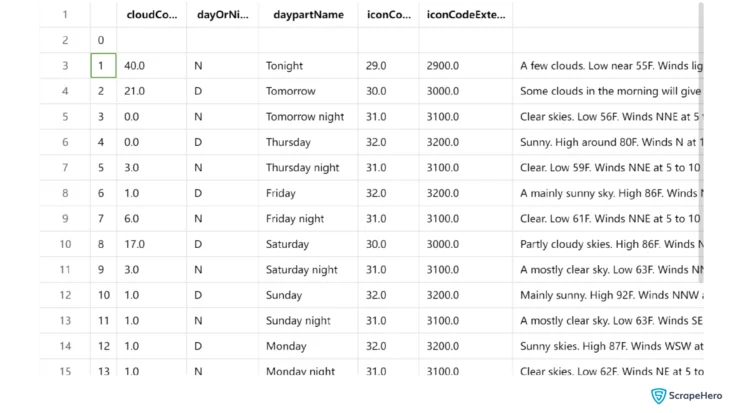
daypartDataFrame.to_csv("daypart.csv")The extracted data from Weather.com looks like this.
And here is the completed code for web scraping weather data using Python.
import pandas, json, re
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
browser = webdriver.Chrome(options=options)
browser.get("https://weather.com")
bar = browser.find_element(By.TAG_NAME,"input")
place = input("Enter a place")
bar.send_keys(place)
sleep(3)
bar.send_keys(Keys.ENTER)
forecasts = browser.find_element(By.XPATH,f"//nav/div/div/a/span[contains(text(),'Today')]")
forecasts.click()
source = browser.page_source
soup = BeautifulSoup(source,"lxml")
scripts = soup.find_all('script')
reqScript = ""
for script in scripts:
if "window.__data" in script.text:
reqScript = script.text
group = re.search(r'\("({.+})"\)',reqScript)
text = group[1].replace('\\"','"')
text = text.replace('\\"','"')
jsonWeather = json.loads(text)
hourly = jsonWeather['dal']['getSunV3HourlyForecastUrlConfig']
innerKey = list(hourly.keys())[1]
hourly = hourly[innerKey]['data']
dailyForecast = jsonWeather['dal']['getSunV3DailyForecastWithHeadersUrlConfig']
innerKey = list(dailyForecast.keys())[1]
fifteenDay = dailyForecast[innerKey]['data']
daypart = fifteenDay['daypart']
del fifteenDay['daypart']
response_headers = fifteenDay['responseHeaders']
del fifteenDay['responseHeaders']
fifteenDayDataFrame = pandas.DataFrame(fifteenDay)
daypartDataFrame = pandas.DataFrame(daypart[0])
hourlyDataFrame = pandas.DataFrame(hourly)
hourlyDataFrame.to_csv("hourly.csv")
fifteenDayDataFrame.to_csv("fifteenDay.csv")
daypartDataFrame.to_csv("daypart.csv")Code Limitations
This code only extracts three forecasts and requires alteration to extract other data, including allergy data and air quality index.
You also need to monitor for changes in the structure of the HTML code or the JSON string. Otherwise, the code will fail whenever Weather.com changes its HTML or JSON structure.
The code is also unsuitable for large-scale web scraping, which may require techniques to bypass anti-scraping measures.
Wrapping Up
You can scrape weather data from weather.com using an automated browser; this code uses Selenium. This browser enables you to input a location and extract weather data from that location.
However, you need to alter the code to get more forecasting data or for large-scale web scraping. You also need to monitor Weather.com for changes.
Contact ScrapeHero if you want to avoid doing all this work. We will also take care of anti-scraping measures that may become apparent in large-scale web scraping projects.
ScrapeHero is a full-service web scraping service provider capable of building enterprise-grade scrapers and crawlers. ScrapeHero services also include website monitoring and Custom Robotic Process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


